
1.XTREME:多言語対応能力を評価する多言語マルチタスクベンチマークまとめ
・自然言語処理の主要な挑戦の1つは世界の全ての約6900言語で機能するシステムを構築すること
・「多言語間で汎用的な言語の特徴」を学習しようとするモデルは増加しているがベンチマークがなかった
・XTREAMは多言語で構文または意味について推論する事を要求する9つタスクで構成されるベンチマーク
2.XTREMEとは?
以下、ai.googleblog.comより「XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization」の意訳です。元記事の投稿は2020年4月13日、Melvin JohnsonさんとSebastian Ruderさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Roman Kraft on Unsplash
自然言語処理(NLP)の主要な挑戦の1つは、英語だけでなく、世界の全ての約6900言語で機能するシステムを構築することです。
世界の言語のほとんどは利用可能なデータがあまり存在せず、独自の堅牢なモデルをトレーニングするために十分な学習用データがありません。しかし幸いなことに、多くの言語は言語の基礎となる構造をかなりの部分で共有しています。
語彙レベルでは、言語にはしばしば同じ起源に由来する単語があります。例えば、英語の「desk」とドイツ語の「Tisch」はどちらもラテン語の「discus」に由来します。また、中国語やトルコ語では時間的および空間的関係を記すために後置詞を使用していますが、多くの言語でも同様の方法で意味上の役割を割り当てています。
NLPには、利用出来るデータが少ない問題を克服するために、複数の言語間の共有構造を活用して学習する手法がいくつかあります。歴史的に、これらの手法のほとんどは、質問応答などの「特定のタスク」を複数の言語で実行することに焦点を当てていました。
過去数年の深層学習の進歩に牽引されて、「特定のタスク」に留まらない「多言語間で汎用の特徴表現」を学習しようとするアプローチ(mBERT、XLM、XLM-Rなど)の数が増加しています。
これは、多言語間で共有され、多くのタスクに役立つ「汎用的な言語知識」を取り込むことを目的としたモデルです。ただし、実際には、このような手法を評価する測定基準は、ほとんどの場合、少数のタスクや言語的に類似した言語を使ってモデルを評価しています。
多言語学習の研究を促進するために、論文「XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization」を紹介します。
XTREMEは、40の言語類型的に異なった言語(12の言語ファミリにまたがる)をカバーする9つのタスクを含み、これらのタスクは様々なレベルの構文または意味について推論をまとめる事を要求します。
XTREMEに含まれる言語は、言語の多様性、既存のタスクが実行できる事、トレーニングデータの可用性を最大化する事を意図して選択されており、多くの研究中の言語が含まれています。
ドラヴィダ語族のタミル語(南インド、スリランカ、シンガポールで話されています)
テルグ語とマラヤーラム語(主に南インドで話されています)
ニジェール・コンゴ語族のスワヒリ語とヨルバ語(アフリカで話されています)
コードとデータはgithubから入手可能で、様々なサンプルコードも含まれています。
XTREMEのタスクと言語
XTREMEに含まれるタスクは、文章分類(sentence classification)、構造予測(structured prediction)、意味検索(sentence retrieval)、質問回答(question answering)など、様々な使用場面をカバーしています。
従って、XTREMEベンチマークでモデルを成功させるには、言語横断的な機能を求められる多くの標準的な状況に対応できる特徴表現を学習する必要があります。
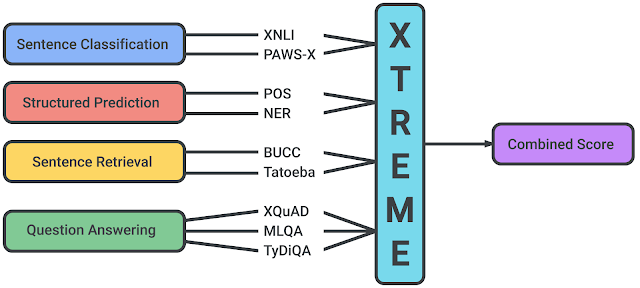
XTREMEベンチマークでサポートされるタスク
各タスクは、英語以外の40の言語をカバーしています。学習データが少ない言語をXTREMEで使用するために、自然言語推論(XNLI)と質問応答(XQuAD)の2つの代表的なタスクのテストデータを英語から自動的に翻訳して学習用データを得ました。
これらの自動機械翻訳された学習用データを使用して学習したモデルが、人間がラベル付けした学習用データを使用して学習したモデルと同等のパフォーマンスを示す事以下で示します。
ゼロショット設定での評価
XTREMEを使用してパフォーマンスを評価するには、まず、クロスリンガル学習を目的として、モデルを多言語テキストで事前トレーニングする必要があります。
次に、タスク固有の英語データを使って微調整します。(ラベル付けされたデータが利用できる最も可能性の高い言語は英語であるため)
それから、XTREMEは、ゼロショットでクロスリンガル転移パフォーマンスを測定します。
訳注:多言語で事前トレーニングするけれども、個々のタスク用の微調整は英語のみでやり、英語以外の言語では、基本的にはゼロショット設定、つまり一度もその言語を使って微調整しないで、そのまま評価すると言う事です。これは、テストが楽になると言う事もありますが、微調整用の学習データが存在しない言語もあるからと言う事が理由のようです。
次の図に、事前トレーニングから微調整、ゼロショット転送までの3ステップのプロセスを示します。
![]()
与えられたモデルのクロスリンガル転送学習プロセス
多言語テキストによる事前トレーニング
その後の下流タスク用に英語で微調整
最後にXTREMEをゼロショットで評価
実務的には、このゼロショット設定の利点の1つは計算効率です。事前トレーニング済みモデルは、各タスク用に英語データで微調整するだけで、他の言語で直接評価できます。
それにもかかわらず、他言語でラベル付けされたデータを利用できるタスクについては、その言語を使った微調整の結果とも比較しました。 最後に、9つ全てのXTREMEタスクのゼロショットスコアを取得して、合計スコアを確認しました。
転移学習のための試験用プラットフォーム
私達は、以下の最先端の事前トレーニング済み多言語モデルを使って実験を行いました。
mBERT(multilingual BERT、人気のあるBERTモデルの多言語拡張版)
XLMとXLM-R(更に多くのデータでトレーニングされたmBERTの2バージョン)
M4(Massively Multilingual Machine translation Model、大規模多言語機械翻訳モデル)
これらのモデルの共通点は、複数の言語の大量のデータを使って事前トレーニングされていることです。私たちの実験では、基準とするベンチマークモデルは40言語、その他は約100言語で事前トレーニングされているモデルを選択しています。
これらのモデルは、英語であれば、既存のタスクのほとんどで人間に近いパフォーマンスを実現します。しかし、英語以外の言語ではパフォーマンスが大幅に低下します。
全てのモデルで、英語のパフォーマンスと他の言語のパフォーマンスのギャップは、構造予測タスクと質問回答タスクで最大になります。その一方、言語間の分散としては、構造予測と意味検索タスクで最大になります。
説明のため、下図では、全てのタスクと言語で最も高いスコアを出したXLM-Rのパフォーマンスを表しています。異なるタスク間ではスコアは単純比較できないため、主な焦点は、タスク間で異なる言語が相対的にどのようにランク付けされるかに絞る必要があります。
ご覧のように、利用できる学習データが多い言語、特にインドヨーロッパ言語ファミリーの言語は、常に上位にランクされています。 対照的に、このモデルでは、中国系チベット語、日本語、韓国語、ニジェールコンゴ語など、他の言語ファミリの多くの言語ではパフォーマンスが低下します。
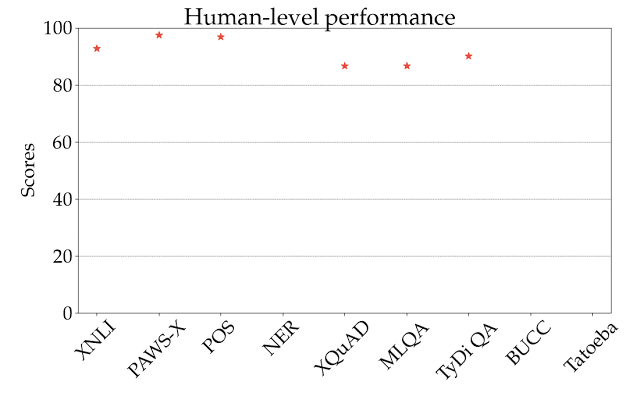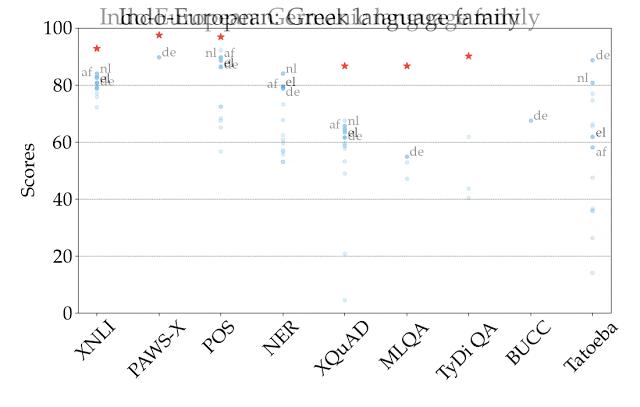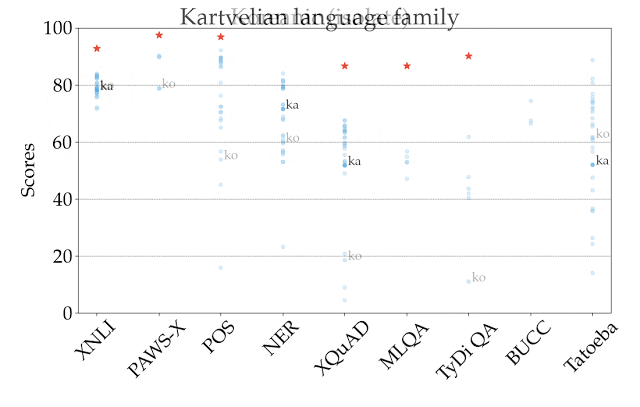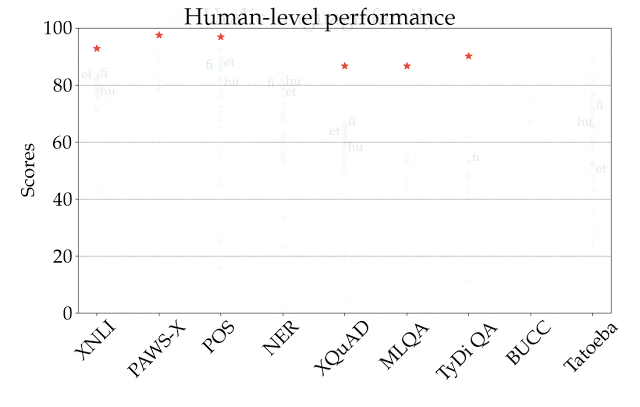
ゼロショット設定でのXLM-R(XTREMEの全てのタスクと言語で最も高いスコアを出した)のパフォーマンスの図
スコアは、タスク固有の基準に基づいた割合であり、タスク間で直接比較することはできません。人間のパフォーマンスは赤い星で表されます(利用可能な場合のみ)。各言語の具体的な例は、ISO 639-1コードで表現されています。
全般的に、私たちは多くの興味深い事象を観察しました。
・ゼロショット設定では、M4とmBERTは、いくつかの単純なタスクでXLM-Rに近いスコアを出しましたが、後者は、特に困難な質問回答タスクで優れています。例えば、XQuADでは、mBERTの64.5とM4の64.6と比較して、XLM-Rは76.6のスコアでした。MLQAとTyDi QAでも同様にスコアに差が出ました。
・トレーニングデータまたはテストデータで機械翻訳したデータを利用すると、非常に効果があることがわかりました。XNLIタスクでは、mBERTはゼロショット転移設定では65.4でしたが、翻訳されたトレーニングデータを使用した場合74.0を記録しました。
・少数ショット設定(つまり、利用可能な場合、転移先言語のラベル付きデータを使用して微調整用に少数回学習する事)は、単純なタスクに対しては特に競争力があることがわかりました。例えば、」名前付きエンティティ認識タスク」などです。しかし、より複雑な質問回答タスクにはあまり役立ちません。例えば、mBERTのパフォーマンスでは、名前付きエンティティ認識タスクは42%改善され、少数ショット設定で62.2から88.3になりました。しかし、質問応答タスク(TyDi QA)の場合、25%(59.7から74.5)しか向上しません。
・全体として、英語と英語以外の言語ではパフォーマンスの間に大きなギャップが存在します。全てのモデルとセッティングにわたってギャップがあるため。これは、クロスリンガル転移学習に関する研究のポテンシャルが非常に高いことを示しています。
クロスリンガルな転移の分析
ディープモデルの一般化能力に関するこれまでの観察と同様に、より多くの事前トレーニングデータが利用可能であれば、性能が向上することがわかっています。(例えば、XLM-RはmBERTと比較してトレーニングデータが多いです)
ただし、この相関関係は構造予測タスク、具体的には品詞タグ付けタスク(POS:part-of-speech tagging)、および名前付きエンティティ認識タスク(NER:named entity recognition)には当てはまりません。これは、現在のディープトレーニング済みモデルでは、事前トレーニングデータを活用して、このような構造予測タスクに完全には転移できないことを示しています。
また、モデルを非ラテン文字に変換する事が困難である事もわかりました。これはPOSタスクで明らかです。mBERTのスコアは、非ラテン文字の日本語では49.2であるのに対し、スペイン語では86.9のゼロショット精度を達成します。
自然言語推論タスク、つまりXNLIの場合、モデルは「英語の例文」と「他言語の同じ例文」で約70%の確率で同じ予測を行います。これは、半教師あり学習で、様々な言語間で翻訳文の一貫性を向上を促進するために役立つ場合があります。
また、モデルが微調整時に使った英語のトレーニングデータには出現しなかったPOSタグの順序を予測する事のに苦労していることもわかりました。これは、モデルが、事前トレーニングに使用されるラベルなしの大量のデータから他の言語の構文を学ぶのに苦労していることを強調しています。
モデルは、言語体系的に英語に近くない言語で、英語のトレーニングデータには出現しなかったエンティティを予測する名前付きエンティティ認識タスクに最も苦戦しました。インドネシア語とスワヒリ語の精度は、それぞれ58.0と66.6ですが、ポルトガル語とフランス語の精度は82.3と80.1です。
多言語転移学習の進歩
英語は、世界人口の約15%のみが使っている言語であるにもかかわらず、NLPの最新の進歩の中心言語となっています。より深い文脈表現に基づいたベンチマークを構築することで、世界の残りの言語に対応するシステムを大幅に進歩させるためのツールを手に入れました。
GLREやSuperGLUEなどのベンチマークがBERT、RoBERTa、XLNet、ALBERTなどの単一言語モデルの開発に拍車をかけたのと同様に、XTREMEが多言語転移学習の研究を触発することを期待しています。
今後のランキング用Webサイトの立ち上げに関して、Twitterアカウント(@GoogleAI)にて発表予定です。
謝辞
この取り組みは、以下の人々を含む多くの方々の尽力で成し遂げられました(姓のアルファベット順)。
Jon Clark, Orhan Firat, Dan Garrette, Sebastian Goodman, Junjie Hu, James Kuczmarski, Graham Neubig, Jason Riesa, Aditya Siddhant および Tom Small.
3.XTREME:多言語対応能力を評価する多言語マルチタスクベンチマーク関連リンク
1)ai.googleblog.com
XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization
2)arxiv.org
XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization
How Language-Neutral is Multilingual BERT?
Unsupervised Cross-lingual Representation Learning at Scale
3)github.com
google-research/xtreme
