
1.トレーニングデータ抽出攻撃:大規模言語モデルが記憶してしまうプライバシー情報(1/2)まとめ
・言語モデルがトレーニング時に使用したデータの詳細を漏洩してしまう危険性が指摘された
・大規模言語モデルを非公開データを使って公開している際に害を及ぼす可能性が高くなる
・GPT-2モデルに対して個人情報を抜き出す実験を行い実際に個人情報を抽出できた
2.トレーニングデータ抽出攻撃とは?
以下、ai.googleblog.comより「Privacy Considerations in Large Language Models」の意訳です。元記事の投稿は2020年12月15日、Nicholas Carliniさんによる投稿です。
メリーさんのウォンバットをイメージしたアイキャッチ画像のクレジットはPhoto by David Clode on Unsplash
文中に出て来る次の単語を予測するようにトレーニングされた機械学習ベースの言語モデルは、ますます能力が高まり、一般化可能で、便利になり、質問回答、機械翻訳などのアプリケーションに画期的な改善をもたらしています。
しかし、言語モデルが進歩し続けると、新しい予期しないリスクが露呈する可能性があり、研究コミュニティは潜在的な問題を軽減するための新しい方法を開発するために積極的に取り組む必要があります。
そのようなリスクの1つは、モデルがトレーニング対象のデータから詳細を漏洩してしまう可能性です。これはすべての大規模な言語モデルにとって懸念事項となる可能性がありますが、プライベートデータでトレーニングされたモデルが公開されると、特に問題が発生する可能性があります。
これらのデータセットは大きく(数百ギガバイト)、様々なソースから取得できるため、公開データでトレーニングされている場合でも、名前、電話番号、住所などの個人情報(PII:Personally Identifiable Information)を含む機密データが含まれる場合があります。
これにより、上記のようなデータを使用してトレーニングされたモデルが、これらの個人情報の一部を出力に反映する可能性が高まります。従って、そのような漏洩リスクを特定して最小限に抑え、将来のモデルの問題に対処するための戦略を開発することが重要です。
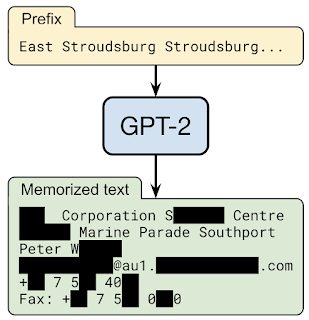
入力として「East Stroudsburg Stroudsburg …(訳注:ペンシルベニア州モンロー郡ストラウズバーグ区)」をGPT-2言語モデルに与えると個人の氏名、電話番号、電子メールアドレス、および住所を含む長いテキストで続きが補完されました。この情報はGPT-2のトレーニングデータに含まれていました。
OpenAI、Apple、Stanford、Berkeley、およびNortheastern Universityとのコラボレーションである論文「Extracting Training Data from Large Language Models」では、事前トレーニング済み言語モデルに入力文を与える事が出来れば、モデルが記憶している特定のトレーニングデータを抽出できることを示します。
そのため、トレーニングデータ抽出攻撃は、最先端の大規模言語モデルに対する現実的な脅威です。この調査は、こういった脆弱性について研究者に通知し、これらの弱点を軽減するための措置を講じることを目的とした、初期の重要なステップを表しています。
倫理的に言語モデル攻撃を実験
トレーニングデータ抽出攻撃は、モデルが一般に公開されていても、そのモデルをトレーニング時に使用したデータセットが非公開データであった場合に害を及ぼす可能性が最も高くなります。
ただし、このようなデータセットでこの調査を実施すると有害な結果が生じる可能性があるため、代わりに、OpenAIによって開発された公開データのみを使用してトレーニングされた大規模な公開言語モデルであるGPT-2に対して概念実証としてトレーニングデータ抽出攻撃を実装しました。
この作業は特にGPT-2に焦点を当てていますが、結果は、一般的に大規模な言語モデルでどのようなプライバシーの脅威が発生する可能性があるかを理解するために適用できます。
他のプライバシーおよびセキュリティ関連の調査と同様に、実際に攻撃を実行する前に、そのような攻撃の倫理を考慮することが重要です。
この作業の潜在的なリスクを最小限に抑えるために、この作業でのトレーニングデータ抽出攻撃は、公開されているデータを使用して開発されました。
更に、GPT-2モデル自体は2019年にOpenAIによって公開され、GPT-2のトレーニングに使用されたトレーニングデータは公開されているインターネットから収集されました。また、GPT-2の論文に記載されているデータ収集プロセスに従う人なら誰でもダウンロードできます。
さらに、責任あるコンピューターセキュリティ開示基準に従って、PIIが抽出された個人をフォローアップし、このデータへの参照を公開する前に許可を得ました。更に、この作品のすべての出版物において、個人を特定する可能性のある個人情報を編集しました。また、GPT-2の分析においてOpenAIと緊密に協力してきました。
トレーニングデータ抽出攻撃
設計上、言語モデルを使用すると、大量の出力データを非常に簡単に生成できます。モデルにランダムな短い入力文を与えることにより、モデルは何百万もの後に続く文、つまり長文を完成させる可能性のある後続文を生成できます。
ほとんどの場合、これらの継続は、適切なテキストの無害な文字列になります。例えば「メーリさんの~(Mary had a little)」という文字列の続きを予測するように求められた場合、言語モデルは次に来る単語が「羊(lamb)」である事に高い自信を持ちます。
ただし、ある特定のトレーニングドキュメント内で「メーリさんのウォンバット~(Mary had a little wombat)」という文字列を何度も繰り返した場合、モデルは羊の代わりにウォンバットを予測する可能性があります。
3.トレーニングデータ抽出攻撃:大規模言語モデルが記憶してしまうプライバシー情報(1/2)関連リンク
1)ai.googleblog.com
Privacy Considerations in Large Language Models
2)arxiv.org
Extracting Training Data from Large Language Models
3)github.com
tensorflow / privacy
4)research.google
The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks

