
1.speaker labels:誰の発言かわかるように音声データにラベルをつけるスマホアプリ(1/2)まとめ
・Pixel用の音声録音アプリRecorderは便利だが誰が何を言ったのかが不明確
・録音中にリアルタイムで各発言者にユニークな匿名ラベルを付ける機能を開発
・この機能は新しい話者推定システム「Turn-to-Diarize」によって実現された
2.speaker labelsとは?
以下、ai.googleblog.comより「Who Said What? Recorder’s On-device Solution for Labeling Speakers」の意訳です。元記事は2022年12月14日、Quan WangさんとFan Zhangさんによる投稿です。
アイキャッチ画像はstable diffusion 2.1のDreamBooth拡張をstable diffusionのアウトペインティングで更にサイズ拡張した画像。stable diffusionのアウトペインティング実装は幾つかあるのですが、まだ私が上手に使いこなせるものを見つける事が出来ておらずイマイチな感じになってしまっています。
2019年、私たちは、ユーザーが音声録音を作成、管理、編集するのに役立つPixelスマートフォン用のオーディオ録音アプリ、Recorderを発表しました。Recorderは最近のデバイス上で動作する機械学習の開発を活用して、音声の転記、音声イベントの認識、タイトルのタグの提案、およびユーザーが録音データから希望するデータを探すのを支援します。
しかしRecorderのユーザーの中には、誰が何を言ったのかが明確でないため、複数の話し手がいる長い録音を取り扱うのが難しいと感じている人もいます。
今年の Made By Google イベントで、私たちは Recorder アプリの「speaker labels」機能を発表しました。
許諾すると使用可能になるこの機能は、録音中に各発言者にユニークな匿名ラベル(「発言者1」、「発言者2」など)をリアルタイムに注釈付けするものです。これにより、録音データの可読性と使い勝手が大幅に向上します。この機能は、ICASSP 2022で初めて発表されたGoogleの新しい話者推定システム(speaker diarization system)「Turn-to-Diarize」によって実現されています。
左:発言者ラベルのないレコーダー原稿
右:発言者ラベル付きのレコーダー原稿
システム構成
私達の話者推定システムは、高度に最適化された機械学習モデルとアルゴリズムを用いて、モバイル端末の限られた計算資源で数時間分の音声をリアルタイムにストリーミングから記録することを可能にします。
本システムは、3つの主要部品から構成されています。
入力音声内の話者が交代した事を検出する話者交代検出モデル(speaker turn detection model)、それぞれの話者から音声の特徴を抽出する話者エンコーダモデル(speaker encoder model)、各話者交代に話者ラベルを効率的に付与する多段階クラスタリングアルゴリズム(multi-stage clustering algorithm)です。
すべてのコンポーネントは、デバイス上で完全に動作します。
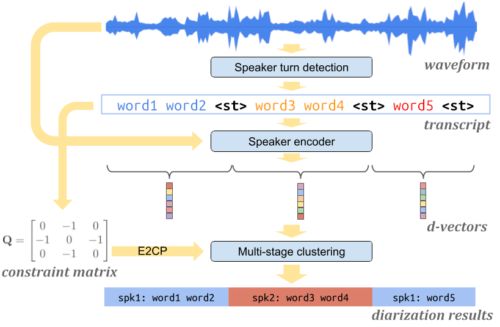
Turn-to-Diarizeシステムの構成
話者の交代の検出
本システムの最初のコンポーネントは、Transformer Transducer(T-T)に基づく話者交代検出モデルです。このモデルは、音響特徴に話者の交代を表す特別なトークン<st>を付与してテキスト原稿に変換するものです。
会話に役割に特化したトークン(例:<医者>と<患者>)を使用する先行カスタマイズシステムとは異なり、このモデルはより汎用的で、様々なアプリケーション領域で学習し展開することが可能です。
ほとんどのアプリケーションでは、話者推定システムの出力は直接ユーザーに示されるのではなく、単語エラーを小さくするように学習された別の自動音声認識(ASR:automatic speech recognition)システムと組み合わされます。
つまり、話者推定システムにとって、私達は<st>トークンの誤りよりも単語トークンの誤りに対して相対的に寛容です。この直感に基づき、予測された<st>トークンに対して高い精度を持つ、小さい話者切り替え検出モデルを学習できる新しいトークンレベルの損失関数を提案します。
編集ベースの最小ベイズリスク(EMBR:Edit-Based Minimum Bayes risk)学習と組み合わせることで、この新しい損失関数は7つの評価データセットにおいて区間ベースのF1スコアを大幅に向上させました。
音声特性を抽出する
音声データを同一話者単位に分割した後、話者エンコーダモデルを用いて、各話者の音声特性を表すembeddingベクトル(d-vector)を抽出します。この方法は、音声データを固定長に小さく断片化したデータからembeddingベクトルを抽出する先行研究に対して、いくつかの利点があります。
まず、複数の話者の音声を含む断片からembeddingを抽出することを避けることができます。同時に、各embeddingは話者からの信号が十分に含まれる比較的大きな時間範囲をカバーする事になります。また、クラスタリングされるembeddingの総数を減らすことができるため、クラスタリングステップのコストが低くなります。これらの埋め込みは、転記先の話者ラベル付けが完了するまで、すべてオンデバイスで処理され、その後削除されます。
3.speaker labels:誰の発言かわかるように音声データにラベルをつけるスマホアプリ(1/2)関連リンク
1)ai.googleblog.com
Who Said What? Recorder’s On-device Solution for Labeling Speakers
