
1.RNN-T:全てをニューラルネットワークで実装したオンデバイス音声認識の実現(1/2)まとめ
・スマホで実行可能ニューラルネットワークベースの音声認識が発表
・音声をクラウドに送って認識する従来型システムより応答が早い
・コネクショニスト時間分類(CTC)と呼ばれる技術を応用している
2.RNN-Tとは?
以下、ai.googleblog.comより「An All-Neural On-Device Speech Recognizer」の意訳です。元記事の投稿は2019年3月12日、Johan Schalkwykさんによる投稿です。
2012年にディープラーニングにより音声認識の精度が大幅に向上し、GoogleのVoice Searchなどの製品に採用されるようになりました。
それはこの分野の革命の始まりでした。毎年、ディープニューラルネットワーク(DNN)からリカレントニューラルネットワーク(RNN)、ロングショートタームメモリーネットワーク(LSTM)、畳み込みネットワーク(CNN)に至るまで、品質をさらに向上させる新しいアーキテクチャが開発されました。この間、ニューラルネットワークの応答速度は常に最優先事項でした。貴方が音声アシスタントに呼びかけた時、素早く応答してくれれば、アシスタントを非常に有能に感じるでしょう。
本日、Gboardで音声入力を強化するための、エンドツーエンドの全てをニューラルネットワークで実現したオンデバイス音声認識装置を発表しました。
私達は論文、「Streaming End-to-End Speech Recognition for Mobile Devices」で、スマートフォンに搭載可能なほど十分にコンパクトなモデルを発表しました。このモデルはRNNトランスデューサ(RNN-T)技術を用いて訓練されています。
オンデバイス、つまりスマートフォンに搭載可能と言う事は、ネットワークの待ち時間や回線混雑状況によるむらがないことを意味します。ネットワークが繋がらないオフラインの場合でも、この新しい認識機能は常に使用可能です。
このモデルは文字単位で認識するので、人間があなたの話している事をリアルタイムで文字入力しているかのように1文字ずつ出力します。 。
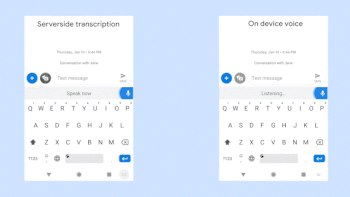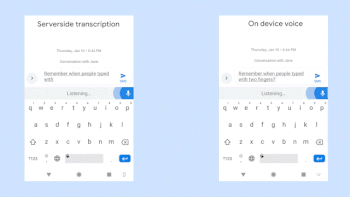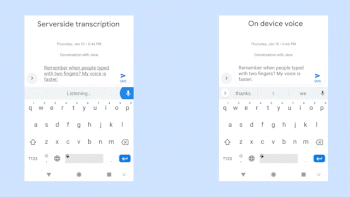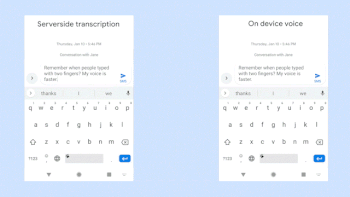
ネットワーク通信が必要なクラウド上の音声認識機能(左)とネットワーク通信が不要な新しいオンデバイス音声認識機能(右)の比較。ビデオクレジット:Akshay KannanとElnaz Sarbar
ちょっとした歴史
伝統的に、音声認識システムはいくつかのコンポーネント(部品)で構成される事がありました。
音響モデル(acoustic model):音声を分割して(通常10ミリ秒フレーム)を音素にマッピングする
発音モデル(pronunciation model):音素を連結して単語を形成する
言語モデル(language model):与えられた語句が言語的に正しいか関連性を定義する
初期のシステムでは、これらのコンポーネントは独立して最適化されていました。2014年頃、研究者たちは入力音声の波形を文章に直接変換するニューラルネットワークを訓練することに集中し始めました。
一連の音声特徴を与えて、一連の単語または書記素(grapheme:言葉を表現する何らかの記号。発音しないghなどを表現するための概念)を生成する事をモデルに学習させるこのsequence-to-sequence アプローチは、「Attention-based」および「listen-attend-spel」モデルの開発に繋がりました。
これらのモデルは精度の点で非常に有望ですが、入力された文章全体を見直すことによって機能するので、リアルタイム音声入力のように音声が逐次入力される状況で逐次出力する用途には一般的にあまり有用ではありません。
これらの研究が進められている間に、コネクショニスト時間分類(CTC)と呼ばれる独立した技術を使うと認識システム(production recognizer)の待ち時間を半分にできる事がわかりました。今回の最新リリースで採用されているRNN-Tアーキテクチャは、CTCの一般化と見なす事ができます。
リカレントニューラルネットワークトランスデューサ
RNN-Tは、Attentionメカニズムを採用していないsequence-to-sequenceモデルの一種です。ほとんどのsequence-to-sequenceモデルは入力シーケンス全体(音声認識の場合は波形)を処理して出力(文章)を生成する必要があります。しかし、RNN-Tsは入力サンプルを継続的に処理し、出力シンボルをストリーミングとして出力します。これは音声認識システムには歓迎される特性です。
この実装では、出力されるシンボルはアルファベットの一文字です。
RNN-Tレコグナイザは、あなたが話すように、必要に応じて空白を入れて1文字ずつ出力します。これは、次の図に示すように、モデルによって予測された文字をモデルにフィードバックして次の文字を予測するフィードバックループで行われます。
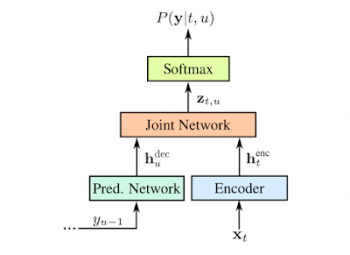
入力オーディオサンプルxと予測シンボルyを使ったRNN-Tの表現。予測されたシンボル(Softmaxレイヤの出力)は、yu-1として、予測ネットワークを介してモデルにフィードバックされ、これまでのオーディオサンプルと過去の出力の両方で予測が調整されるようにします。
予測ネットワークとエンコーダネットワークはLSTM RNNで、ジョイントモデルはフィードフォワードネットワークです(論文参照)。 予測ネットワークは、640次元の投影層を持つ2つの2048ユニットの層で構成されています。 エンコーダネットワークは8つのそのような層を含みます。イメージクレジット:Image credit: Chris Thornton
このようなモデルを効率的にトレーニングするためには大量の計算が必要になるのでかなり大変な事ですが、私達は単語エラー率をさらに5%削減する新しいトレーニング手法を開発し、それはより一層の計算機パワーを必要としました。
これに対処するために、Googleの高性能Cloud TPU v2ハードウェア上でRNN-T損失関数を大量に効率的に実行できるように、並列実装を開発しました。これにより、トレーニングが約3倍スピードアップしました。
3.RNN-T:全てをニューラルネットワークで実装したオンデバイス音声認識の実現(1/2)関連リンク
1)ai.googleblog.com
An All-Neural On-Device Speech Recognizer
Google voice search: faster and more accurate
2)arxiv.org
Streaming End-to-end Speech Recognition For Mobile Devices
Sequence Transduction with Recurrent Neural Networks
