
1.speaker labels:誰の発言かわかるように音声データにラベルをつけるスマホアプリ(2/2)まとめ
・音声をembedding化した後、複数のクラスタリング手法で話者推定を実施する
・メイン処理に渡す前に予備的アルゴリズムで事前処理して計算コストを削減
・録音中に話者ラベルを自動的に更新し最新かつ正確な予測を反映させる事も可能
2.speaker labelsの効率化の工夫
以下、ai.googleblog.comより「Who Said What? Recorder’s On-device Solution for Labeling Speakers」の意訳です。元記事は2022年12月14日、Quan WangさんとFan Zhangさんによる投稿です。
アイキャッチ画像はstable diffusionの生成
多段階クラスタリング
録音された音声が一連のembeddingベクトルで表現されたら、最後にこれらのembeddingベクトルをクラスタリングし、それぞれに話者を推定したラベルを割り当てます。しかし、Recorderアプリで録音された音声は数秒から最長18時間にも及ぶため、クラスタリングアルゴリズムには、長さが極端に異なる音声データを扱える事が重要です。
そこで、異なったクラスタリングアルゴリズムの利点を活用するために、多段階のクラスタリング戦略を提案します。まず、話者交代検出出力を用いて、録音に少なくとも2人の異なる話者が存在するかどうかを判断します。短い音声データでは、予備的アルゴリズムとして凝集型階層的クラスタリング(AHC:Agglomerative Hierarchical Clustering)を使用します。
中程度の長さの音声データでは、メインアルゴリズムとしてスペクトラルクラスタリング(spectral clustering)を使用し、正確な話者数推定のために固有ギャップ基準を使用します。
長時間の音声データでは、メインアルゴリズムに渡す前に、AHCを使用してシーケンスを事前にクラスタリングすることにより、計算コストを削減します。
ストリーミングデータを扱う際、私達は以前に求めたAHCクラスタの中心点を動的なキャッシュに保持し、将来のクラスタリング呼び出しの際に再利用することができます。このメカニズムにより、一定の時間と空間の複雑さを持つシステム全体に対して上限を強制することができます。
この多段階クラスタリング戦略は、CPU、メモリ、バッテリーの予算が非常に少ないデバイス上で実施するアプリケーションにとって重要な最適化であり、何時間もオーディオを録音した後でも、システムを低電力モードで動作させることができるようにします。品質と効率のトレードオフとして、計算コストの上限は、異なる計算資源を持つデバイスに対して柔軟に設定することができます。
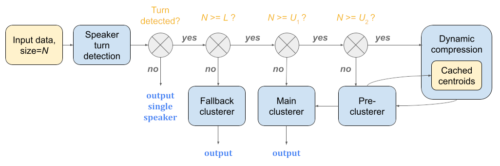
多段階クラスタリング戦略のイメージ図
修正とカスタマイズ
私達のリアルタイムにストリーミングデータの話者を推定可能なシステムでは、より多くの音声入力を消費することで、予測された話者推定ラベルの信頼度を蓄積し、以前に予測された信頼度の低い話者推定ラベルを修正する場合があります。Recorderアプリは、録音中に画面上の話者ラベルを自動的に更新し、最新かつ最も正確な予測を反映させます。
同時に、RecorderアプリのUIでは、匿名の話者ラベル(例:「話者2」)をカスタマイズしたラベル(例:車販売員)に名称変更して、各録音内でユーザーが読みやすく、覚えやすいようにすることができます。
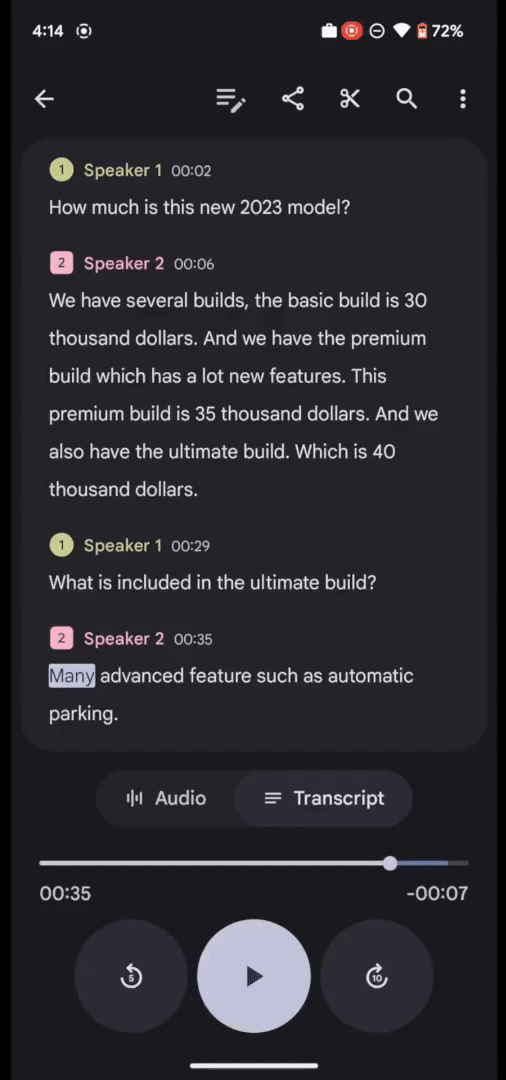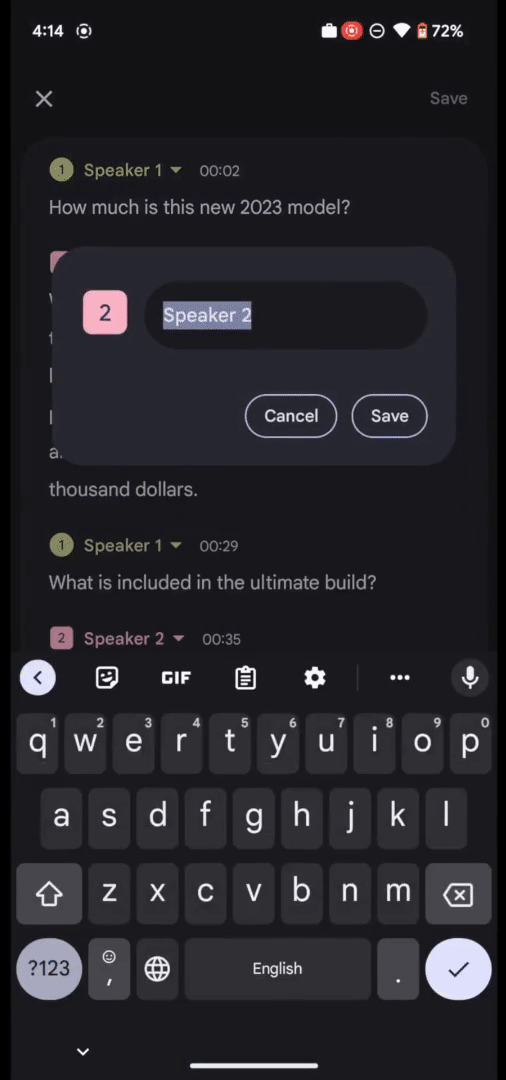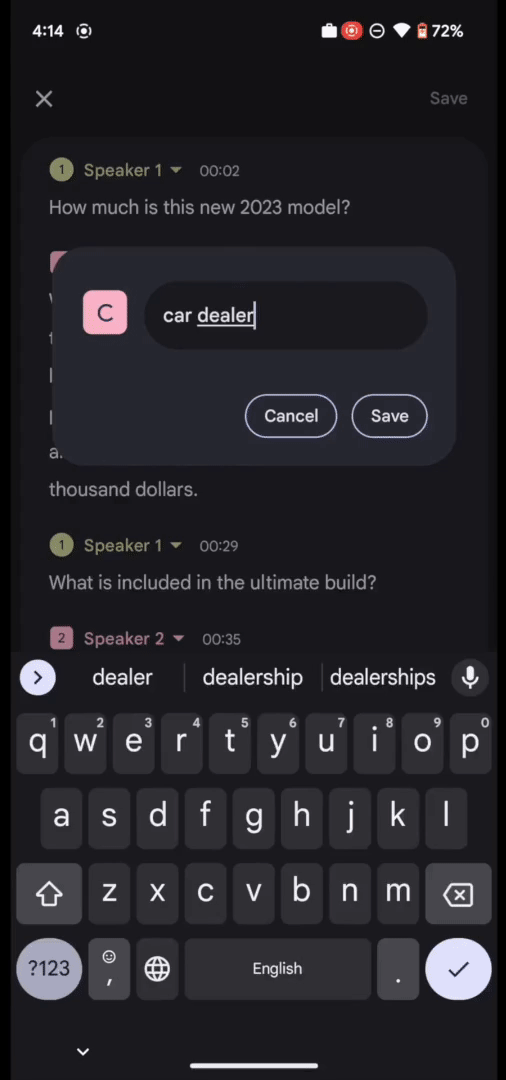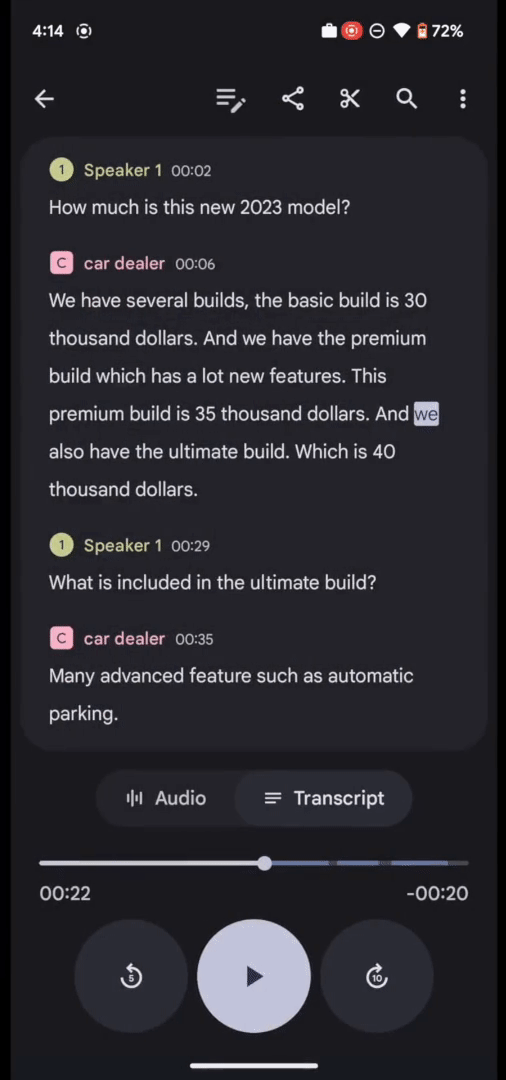
Recorderでは、ユーザは読みやすいように話者に付与されるラベルの名称を変更することができます。
今後の課題
現在、私たちの話者推定システムは、Google TensorのCPUブロック、つまり最近のPixelシリーズのスマートフォンに搭載されているGoogleの特注チップで主に動作しています。私たちは、より多くの計算をTPUブロックに委ねることで、話者推定システム全体の消費電力をさらに削減することに取り組んでいます。また、話者エンコーダと音声認識モデルの多言語機能を活用し、この機能をより多くの言語に拡張することも今後の課題です。
謝辞
この投稿は、Googleの複数のチームによる共同研究です。
貢献者には以下の皆さんが含まれます。
Quan Wang、Yiling Huang、Evan Clark、Qi Cao、Han Lu、Guanlong Zhao、Wei Xia、Hasim Sak、Alvin Zhou、Jason Pelecanos、Luiza Timariu、Allen Su、Fan Zhang、Hugh Love、Kristi Bradford、Vincent Peng、Raff Pengが参加しています。Vincent Peng, Raff Tsai, Richard Chou, Yitong Lin, Ann Lu, Kelly Tsai, Hannah Bowman, Tracy Wu, Taral Joglekar, Dharmesh Mokani, Ajay Dudani, Ignacio Lopez Moreno, Diego Melendo Casado, Nino Tasca, Alex Gruenstein。
3.speaker labels:誰の発言かわかるように音声データにラベルをつけるスマホアプリ(2/2)関連リンク
1)ai.googleblog.com
Who Said What? Recorder’s On-device Solution for Labeling Speakers

