
1.音響的な手がかりと言語的な手がかりを使って発言者を特定する(1/3)まとめ
・スピーカーダイアライゼーション(Speaker Diarization)は「誰が何を発言したのか?」を認識する技術
・従来は発言者が変化した事を認識するシステムと個別の発言者を識別するシステムの二段階構成
・RNN-Tが最近開発された事により従来型システムが持つ幾つかの制限は対処可能になった
2.スピーカーダイアライゼーションとは?
以下、ai.googleblog.comより「Joint Speech Recognition and Speaker Diarization via Sequence Transduction」の意訳です。元記事は2019年8月16日、Laurent El ShafeyさんとIzhak Shafranさんによる投稿です。
発言者の特定、専門用語で言えばスピーカーダイアライゼーション(Speaker Diarization)、つまり「誰が何を発言したのか?」を認識する事は、機械と人間が音声を使って対話する技術を開発するための重要なステップです。例えば、医師と患者が会話している際、「心臓の薬を定期的に服用していましたか?」と言う質問に対する患者の「はい」は、医師の相槌的な「はい」とはかなり異なった意味を持ちます。
従来の発言者特定システム(SD)は2段階で実現されています。第一段階は音響スペクトルの変化を検出して会話中の発言者が変わった事を判断します。第二段階は会話全体を通じてどの時点で誰が発言したのか、個別の発言者を識別します。
この基本的な2段階アプローチは20年近く前に考案されたものであり、その間、発言者の変化を検出する箇所のみが改善されてきました。
新しいニューラルネットワークモデルであるRNN-T(Recurrent Neural Network Transducer)が最近開発された事により、以前の発言者特定システムが持つ制限のいくつかに対処可能になりました。この発言者特定システムのパフォーマンスを向上させた適切なアーキテクチャについては以前発表しています。
Interspeech 2019で論文「Join Speech Recognition and Speaker Diarization via Sequence Transduction」として報告予定ですが、RNN-Tベースの発言者特定システムを開発し、単語特定エラー率を約20%から2%に改善するブレークスルーを実証しました。約10倍の改善です。
従来の発言者特定システム
従来の発言者特定システムは、会話中の発言者を区別するために、個々人の発声が音響的にどのように聞こえるかの違いに依存しています。
男性と女性の音声は、単純な音響モデル(ガウス混合モデルなど)を使用して、音程から比較的簡単に一度の作業で区別できます。一方、発言者特定システムは、多段階アプローチを使用して、潜在的に同じ音程を持つ発言者を捜して区別します。
1)会話データの分割
まず、発言者の変化を検出するアルゴリズムが、検出された音程特性に基づいて、会話データを単一の話者のみを含む同質なデータに分割します。
2)特徴ベクトルの作成
次に、ディープラーニングモデルを使用して、各発言者の音声データからembeddingsベクトルを作成します。
3)特徴ベクトルのクラスタリング
最後にこれらのembeddingsがグループ化され、「誰がいつ発言したか?」を会話全体を通して追跡できるようになります。
実際には、発言者特定システム(SD)は自動音声認識(ASR:Automatic Speech Recognition)システムと並行して実行されます。2つのシステムの出力が組み合わされて「ASRが認識した単語」に「SDが認識した発言者」をラベルとして関連付けます。
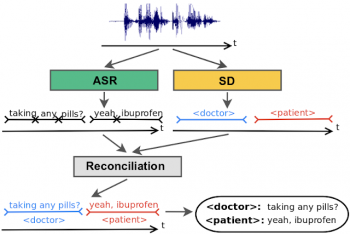
従来の発言者特定システムは、音程から発言者を推測し、別のASRシステムによって生成された単語に発言者をラベル付けします。
3.音響的な手がかりと言語的な手がかりを使って発言者を特定する(1/3)関連リンク
1)ai.googleblog.com
Joint Speech Recognition and Speaker Diarization via Sequence Transduction
2)arxiv.org
Joint Speech Recognition and Speaker Diarization via Sequence Transduction

コメント