
1.PSM:行動の類似性に着目して強化学習の一般化性能を改善(1/2)まとめ
・強化学習は意味的に同等なタスク間であっても新タスクへの応用が困難
・障害物を飛び越えるタスクでは初見の場所に設置された障害物に苦労する
・タスク間で類似している動作に着目してこの問題の解決に挑戦した
2.ポリシー類似性指標とは?
以下、ai.googleblog.comより「Improving Generalization in Reinforcement Learning using Policy Similarity Embeddings」の意訳です。元記事の投稿は2021年9月29日、Rishabh Agarwalさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Bùi Thanh Tâm on Unsplash
強化学習(RL:Reinforcement learning)は一連の意思決定パラダイムです。
ロボットの移動、ビデオゲームのプレイ、成層圏の気球の飛行、ハードウェアチップの設計などの複雑なタスクに取り組むために知的なエージェントをトレーニングします。
RLエージェントはさまざまな行動で有望な結果を示していますが、意味的に同等なタスク間であっても、これらのエージェントの能力を新しいタスクに移行することは困難です。
たとえば、エージェントが画像を観察して障害物を飛び越えるジャンプタスクの学習について考えてみます。さまざまな場所に位置を変えた障害物で訓練されたディープRLエージェントは、訓練時になかった場所に設置された障害物をうまくジャンプするのに苦労します。
ジャンプタスク:画素から学習したエージェント(白いブロック)は、障害物(灰色の正方形)を飛び越える必要があります。課題は、少数のトレーニングタスクを使用して、テストタスクでトレーニング時になかった位置にある障害物と床の高さに一般化することです。特定のタスクでは、エージェントは障害物から特定の距離でのジャンプ時間を正確に計る必要があります。そうしないと、最終的に障害物にぶつかります。
ICLR 2021でスポットライト論文として提示された「Contrastive Behavioral Similarity Embeddings for Generalization in Reinforcement Learning」では、固有の順次構造をRLの特徴表現学習プロセスに組み込んで、初見タスクへの一般化を強化します。
この問題は従来、教師あり学習が適用されていたため、連続的な側面(sequential aspect)はほとんど無視されていました。
私たちのアプローチは、エージェントが、基礎となるメカニズムが類似しているタスクで動作している場合、タスク間で類似している動作が存在し、少なくとも短い類似した連続性を示すという事実を利用しています。
一般化に関する従来の研究は、通常、教師あり学習が適用され、学習プロセスの強化を中心に展開されていました。これらのアプローチは、時間的観察全体を通したアクションの類似性など、連続的な側面を属性として利用することはめったにありません。
私たちのアプローチは、エージェントにとって最適な動作が状態間で類似している場合に、類似した状態の特徴表現を学習するようにエージェントをトレーニングします。
行動の類似性(behavioral similarity)と呼ばれるこの近接性の概念(notion of proximity)は、さまざまなタスクにわたる観察に一般化されます。
さまざまなタスク(たとえば、位置が異なる障害物をジャンプするタスク)にわたる状態間の動作の類似性を測定するために、双模倣性(bisimulation)に触発された理論的に動機付けられた状態類似性指標であるポリシー類似性指標(PSM:Policy Similarity Metric)を導入します。
たとえば、次の画像は、視覚的に異なる2つの状態でのエージェントの将来のアクションが同じです。PSMに従うとこれらの状態は類似しています。
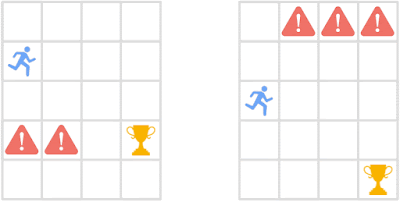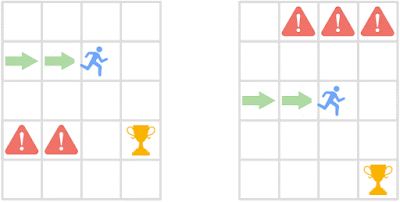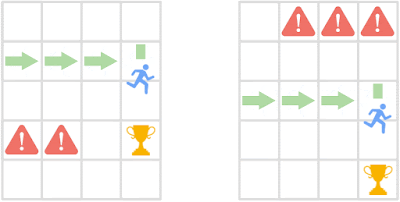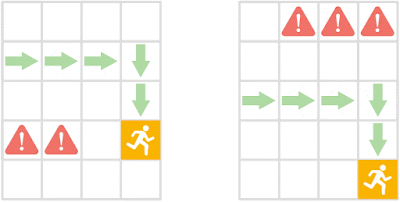
行動の類似性の理解
エージェント(青いアイコン)は、危険(赤い!アイコン)と距離を保ちながら報酬を獲得する必要があります。初期状態は視覚的に異なりますが、現在の状態と現在の状態に続く将来の状態における最適な動作の点で類似しています。ポリシー類似性指標(PSM)は、そのような動作的に類似した状態に高い類似性を割り当て、異なる状態に低い類似性を割り当てます。
3.PSM:行動の類似性に着目して強化学習の一般化性能を改善(1/2)関連リンク
1)ai.googleblog.com
Improving Generalization in Reinforcement Learning using Policy Similarity Embeddings
2)agarwl.github.io
Contrastive Behavioral Similarity Embeddings for Generalization in Reinforcement Learning
3)github.com
google-research / jumping-task

