
1.CATS4ML:機械学習の未知の不明を明らかにするコンペまとめ
・機械学習モデルのパフォーマンスは学習アルゴリズムとデータ品質の両方に依存
・機械学習の評価に使用されるデータセットの品質はアルゴリズム程探求されていない
・CATS4MLはモデルが分類に自信を持っているが実際には間違っている未知の不明を捜すコンペ
2.CATS4MLとは?
以下、ai.googleblog.comより「Uncovering Unknown Unknowns in Machine Learning」の意訳です。元記事の投稿は2021年2月11日、Lora AroyoさんとPraveen Paritoshさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Artem Kovalev on Unsplash
機械学習(ML:Machine Learning)モデルのパフォーマンスは、学習アルゴリズムと、トレーニング時と評価時に使用されるデータ品質の両方に依存します。
アルゴリズムの役割は十分に研究されており、SQuAD、GLUE、ImageNetなどで多数の課題に焦点が当てられています。更に、MLを評価する課題に取り組む一連のワークショップなど改善にも取り組んできました。
対照的に、MLモデルの評価に使用されるデータセットに焦点を当てた研究と課題はアルゴリズム程一般的ではありません。さらに、多くの評価データセットには、評価しやすい項目が含まれています。例えば、被写体が識別しやすい写真などであり、このようなデータセットでは現実世界で生じる自然なあいまいさを見逃してしまいます。
評価データセット内にあいまいな実例がないため、機械学習のパフォーマンスの確実性をテストする能力が損なわれており、MLモデルに「弱点」が発生しやすくなります。つまり、モデルが正確に評価することが困難または不可能な事例が評価データセットから欠落しているのです。
MLモデルのこれらの弱点を特定する問題に対処するために、最近、HCOMP 2020でクラウドソーシング機械学習用有害テストセット(CATS4ML:Crowdsourcing Adverse Test Sets for Machine Learning)データチャレンジを開始しました。(2021年4月30日まで世界中の研究者と開発者に公開中です)。
本チャレンジの目標は、MLを評価するデータセットの水準を引き上げ、アルゴリズムの処理を混乱させる、または問題を引き起こす例をできるだけ多く見つけることです。CATS4MLでは、人々の能力と直感に依存して、機械学習が自信を持っているが実際には誤分類している新しいデータの例を見つけます。
MLの「弱点」とは何でしょうか?
弱点には、「既知の不明(known unknowns)」と「未知の不明(unknown unknowns)」の2つのカテゴリがあります。
既知の不明とは、モデルが正しい分類について確信が持てない事例です。研究コミュニティは、アクティブラーニングとして知られる分野でこれを研究し続けており、おおまかに言えば、不確実な事例について人間と対話して新しいラベルの付与を求めるという解決策を見つけました。
例えば、写真の被写体が猫であるかどうかがモデルにわからない場合、モデルは人間に確認を求めます。しかし、システムが確信を持っている場合、人間に尋ねる事はしません。この領域には改善の余地がありますが、このやり方が快適なのは、モデルの信頼性がそのパフォーマンスと相関していることです。つまり、モデルが何を知らないかを確認する事ができます。
一方、未知の不明は、モデルがその答えに自信を持っているが、実際には間違っている例です。未知の不明を積極的に発見するための取り組み(Attenberg2015やCrawford2019など)は、意図しない多数のマシンの誤動作を明らかにするのに役立ちました。
未知の不明を発見するための上記のようなアプローチとは対照的に、敵対的生成ネットワーク(GAN:Generative Adversarial Networks)は、コンピューターの錯視として画像認識モデルの未知の不明を生成します。これはディープラーニングモデルが人間の知覚を超えた間違いを犯す原因になります。
GANは、画像に対して意図的な編集操作が行われた場合にモデルが悪用される危険性を明らかにしましたが、現実世界の実例の中にも、モデルの日常用途におけるパフォーマンスの失敗をより明確に示すことができます。これらの現実世界の実例が、CATS4MLが関心を持つ未知の不明です。この課題は、人間が確実に解釈できるが、多くのMLモデルが自信を持って間違う画像編集されていない事例を収集することを目的としています。
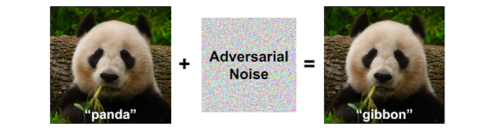
敵対的なノイズを加えられた事によって引き起こされるコンピューターの錯視が、画像操作された未知の不明の発見にどのように役立つかを示す例。パンダの画像に敵対的なノイズを加える事により「テナガザル(gibbon)」と誤認識させている。(Brown等の2018の研究に基づく)
CATS4MLデータチャレンジの初版:Open Imagesデータセット
CATS4MLデータチャレンジは、Open Imagesデータセットの画像とラベルを使用して、視覚的な認識に焦点を当てています。チャレンジのターゲット画像は、同じデータセットの24個のターゲットラベルのセットとともに、Open Imagesデータセットから選択されます。チャレンジ参加者は、この既存の公開されているデータセットを探索するための新しい創造的な方法を発明し、事前に選択されたターゲットラベルのリストに焦点を当て、MLモデルの未知の不明事例を発見する事に招待されます。

Open Imagesデータセット内のMLモデル用の未知の不明事例
CATS4MLは、動的データ収集のために最近導入されたFAIRのDynaBench研究プラットフォームを補完する取り組みです。DynaBenchは学習ループ内に人間が存在しているMLモデルを使用して静的ベンチマークの問題に取り組んでいます。CATS4MLは未知の不明の可能性を持つ有害な事例について既存のMLベンチマークの調査を奨励することにより、MLの評価データセットの改善に焦点を当てます。結果は、将来のエラーを検出して回避するのに役立ち、モデルの説明性についての洞察も提供します。
このように、CATS4MLは、開発者がアルゴリズムの弱点を明らかにするために使用できるデータセットリソースを提供することにより、問題の認識を高めることを目的としています。これにより、よりバランスの取れた、多様で、社会的に認識された機械学習のベンチマークデータセットを作成する方法についても研究者に通知されます。
参加するためには
MLの研究者と実践者のグローバルコミュニティに参加して、Open ImagesDatasetから興味深く難しい事例を発見する取り組みに参加してください。チャレンジウェブサイトに登録し、ターゲット画像とラベル付きデータをダウンロードし、発見した画像を投稿して、優勝を競うコンテストに参加してください!
このコンテストでポイントを獲得するには、参加者は、ヒューマンインザループの評価者によって確認される一連の画像とラベルのペアを提出する必要があります。その提出物は、多くの機械学習モデルが出力するラベルと一致しないはずです。
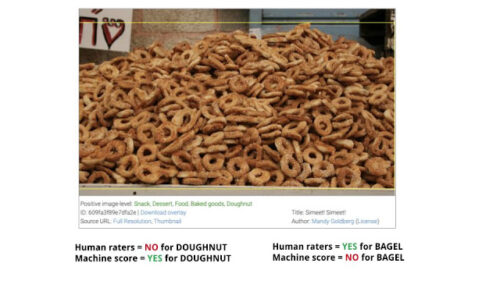
送信された画像がポイントを獲得する例
同じ画像が、2つの異なるラベルで誤検知(左)と見逃し(右)としてスコア付けされる可能性があります。どちらの場合も、人間による検証はマシンのスコアと一致しません。 参加者は、送信された画像とラベルのペアでスコアを付けます。つまり、1つの同じ画像が、異なるラベルでMLにとっての未知の不明事例になる可能性があります。
チャレンジは2021年4月30日まで世界中の研究者と開発者に開かれています。CATS4MLの詳細と参加方法については、チャレンジのWebサイト「cats4ml.humancomputation.com」にアクセスしてください。
謝辞
CATS4MLデータチャレンジのリリースは、以下の沢山の人々を含み、この人々に限定されない多くの人々の努力のおかげで可能になりました。(以下は姓のアルファベット順です)
Osman Aka, Ken Burke, Tulsee Doshi, Mig Gerard, Victor Gomes, Shahab Kamali, Igor Karpov, Devi Krishna, Daphne Luong, Carey Radebaugh, Jamie Taylor, Nithum Thain, Kenny Wibowo, Ka Wong, and Tong Zhou.
3.CATS4ML:機械学習の未知の不明を明らかにするコンペ関連リンク
1)ai.googleblog.com
Uncovering Unknown Unknowns in Machine Learning
2)cats4ml.humancomputation.com
Cats4ml App

