
1.自己教師学習で音声特徴表現と個人専用モデルを改善(1/2)まとめ
・非セマンティックタスクとは、声の調子など、人間の音声の「意味以外の側面」に焦点を当てたタスク
・従来のベンチマークでは非セマンティックタスク用の特徴表現が有用か否かを比較する事が困難
・音声関連の特徴表現学習研究コミュニティにデータセット、モデル、測定ツールの3つの貢献を行った
2.非セマンティックな音声タスクとは?
以下、ai.googleblog.comより「Improving Speech Representations and Personalized Models Using Self-Supervision」の意訳です。元記事は2020年6月18日、Joel ShorさんとOran Langさんによる投稿です。
人間の音声は文章や画像と違って、「その人固有の声」で、且つ「怒っている声」など「発言内容の意味している事(セマンティック)」ではなく声の調子を対象にする必要があったりするために、大規模なデータセットが構築しにくく、他の研究領域で活発な大規模な事前学習からの転移学習アプローチがやりにくいのですが、その解決を探ったお話です。
アイキャッチ画像は心の赴くままに自己教師で独自音楽モデルを作り上げていそうな格好良いブラジルのストリートミュージシャンで、クレジットはPhoto by Talles Alves on Unsplash
音声処理には、大量の学習用データを用意することで簡単に解決できる多くのタスクがあります。例えば、自動音声認識(ASR:Automatic Speech Recognition)は、音声をテキストに変換します。
対照的に、「非セマンティック(non-semantic)」タスクは、人間の音声の「意味以外の側面」に焦点を当てます。これらは例えば、音声感情認識や話者識別、言語識別、ある種の音声ベースの医療診断などです。
学習ベースのシステムでこれらのタスクを成功させる一般的なアプローチの一つは、可能な限り大きいデータセットを利用して学習し、良好な結果を保証することです。
ただし、大規模なデータセットに性能が直接依存する機械学習技術は、小規模なデータセットを使ってトレーニングした場合、多くの場合あまり良いパフォーマンスを出せません。
大規模なデータセットと小規模なデータセット間のパフォーマンスのギャップを埋める1つの方法は、大規模なデータセットで特徴表現モデル(representation model)をトレーニングし、それを利用できるデータが少ない環境に転移学習する事です。
特徴表現は2つの方法でパフォーマンスを向上させることができます。
高次元データ(画像や音声など)を低次元に変換する事で小さなモデルをトレーニングできるようにする事ができます。また、特徴表現モデルを事前トレーニングとして使用することもできます。
更に、特徴表現モデルがスマートフォンなどのデバイス上で実行またはトレーニングできるほど小さい場合、ユーザから直接収集した生データを使ってユーザ専用のモデルを構築しパフォーマンスを向上させることができます。個人情報を含むデータをデバイス外に送る必要がないため、プライバシーを保護しながらこれを実現できます。
特徴表現学習は、テキストを扱う研究領域(BERTやALBERTなど)や画像を扱う研究領域(InceptionレイヤーやSimCLRなど)で一般的に使用されていますが、このようなアプローチは音声を扱う研究領域では十分に活用されていません。
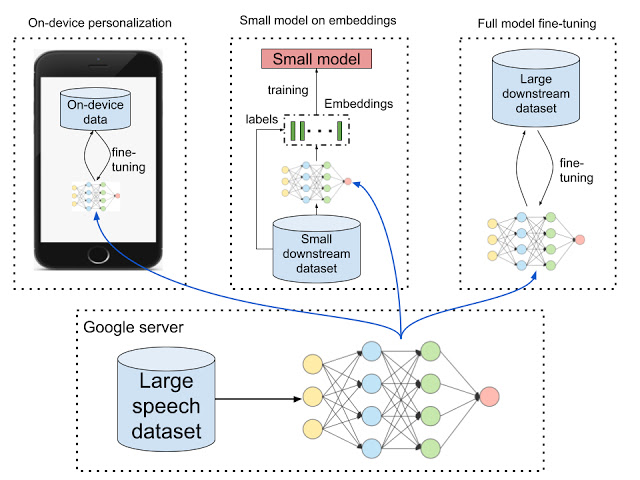
下段:大きな音声データセットを使用してモデルをトレーニングし、それを他の環境に展開します。
上段左:「デバイス内で個人専用モデルを構築」パーソナライズされたデバイス上のモデルは、セキュリティとプライバシーを両立しています。
上段中央:「embeddingsを使って小さなモデルを構築」
汎用特徴表現は、精度を犠牲にすることなく、少数の高次元サンプルデータセットを低次元に変換します。これを使って小さいモデルはより速く学習と正則化を行えます。
上段右:「完全なモデルを微調整」
大規模なデータセットはで事前トレーニングを行いパフォーマンスを改善できます。
有用な特徴表現を明確に改善する事は、基準となる標準的なベンチマークがなければ困難です。特に「非セマンティック音声タスク」は、音声の持つ意味を参照する事ができないので「音声特徴表現の有用性」を比較することは困難です。
T5フレームワークは文章のembeddingを体系的に評価し、ビジュアルタスク適応ベンチマーク(VTAB:Visual Task Adaptation Benchmark)は画像のembedding評価を標準化し、どちらもそれぞれの分野での特徴表現学習の進歩につながりましたが、非セマンティックな音声のembeddingにはそのようなベンチマークがありませんでした。
論文「Towards Learning a Universal Non-Semantic Representation of Speech」では、音声関連の特徴表現学習に3つの貢献をしています。
まず、音声特徴表現を比較するための非セマンティック音声(NOSS:NOn-Semantic Speech)ベンチマークを示します。これには、音声感情認識、言語識別、話者識別など、多様なデータセットとベンチマークタスクが含まれます。これらのデータセットは、TensorFlow Datasetsの「audio」セクションで利用できます。
次に、TRIpLet Loss network(TRILL)を作成してオープンソースとして公開します。これは、他の特徴表現より優れた性能を発揮しながら、オンデバイスで実行および微調整できるほど小さい新しいモデルです。
3番目に、私達は様々な特徴表現を比較する大規模な調査を実行しました。その際に使った、新しい特徴表現のパフォーマンスを計算するためのコードをオープンソース化します。
音声Embeddingsのための新しいベンチマーク
ベンチマークを用いてモデル開発を効果的に行うためには、ベンチマークが対象タスクと似たタスクを含み、且つ大幅に異なったタスクを除外している必要があります。
従来の研究では、考えられる様々な音声ベースのタスクを個々に扱うか、セマンティックタスクも非セマンティックタスクも一緒に扱っていました。
私達の研究は、部分的に、非セマンティック音声タスクのパフォーマンスを向上させます。一部の音声タスクで特にうまく機能するニューラルネットワークアーキテクチャに焦点を当てる事でこれを実現しています。
NOSSベンチマークに含まれるタスクは、以下を重視して選択されました。
(1)多様性
それは様々な使われ方に対応できる必要があります。
(2)複雑さ
それは挑戦的なタスクも含まれる必要があります。
3)可用性
特に、オープンソースのタスクに重点を置いています。
サイズとタスクが異なる6つのデータセットを組み合わせました。
| Dataset | Has intraspeaker | Target | Number of classes | Number of samples | Average duration(secs) |
| VoxCeleb | No | Speaker identification | 1251 | 153514 | 8.2 |
| VoxForge | No | Language identification | 6 | 176438 | 5.8 |
| Speech Commands | Yes | Command | 12 | 105829 | 1.0 |
| CREMA-D | Yes | Emotion | 6 | 7442 | 2.5 |
| SAVEE | Yes | Emotion | 7 | 480 | 3.8 |
| DementiaBank | No | Dementia/healty | 2 | 210 | 70.0 |
下流タスクのベンチマークデータセット
※私達の研究におけるVoxCelebの結果は、データセットのサブセットを使用して計算されました。
サブセットはデータセットを内部ポリシーに従ってフィルタリングした結果です。
3.自己教師学習で音声特徴表現と個人専用モデルを改善(1/2)関連リンク
1)ai.googleblog.com
Improving Speech Representations and Personalized Models Using Self-Supervision
2)arxiv.org
Towards Learning a Universal Non-Semantic Representation of Speech
3)github.com
google-research/non_semantic_speech_benchmark/
4)aihub.cloud.google.com
nonsemantic-speech-benchmark
5)www.tensorflow.org
TensorFlow Datasets

コメント