
1.VTAB:視覚タスク用のベンチマーク(1/2)まとめ
・視覚タスク用に事前トレーニングしたモデルは有用だが数が多く評価方法も異なっている
・数が多すぎる故にどのモデルが最適な特徴表現を提供してくれるのかを知ることは困難
・VTABは多様で現実的でチャレンジングな特徴表現ベンチマークを提供する事でこの問題に挑戦
2.VTABとは?
以下、ai.googleblog.comより「The Visual Task Adaptation Benchmark」の意訳です。元記事は2019年11月6日、Neil HoulsbyさんとXiaohua Zhaiさんによる投稿です。
ディープラーニングはコンピュータービジョンに革命をもたらしました。最先端のディープネットワークが未加工の画像から有用な特徴表現を直接学習し、多くの視覚タスクで前例のないパフォーマンスを実現しています。ただし、これらの特徴表現をゼロから学習するには、通常、数十万枚の学習用画像が必要です。
この負担は、TensorFlow Hub(TF Hub)やPyTorch Hubなどのサービスを通じて広く利用可能になった事前トレーニング済みモデルの特徴表現を使用することで軽減できます。
しかし、利用可能なモデルが多すぎる事はそれ自体が障害になる可能性があります。例えば、画像から特徴表現を抽出するタスクの場合、100を超えるモデルを選択できます。様々なモデルが様々な評価手法(ベンチマーク)で評価されているため、どのモデルが最適な特徴表現を提供してくれるのかを知ることは困難です。
特徴表現研究の最大の目標は、大量の汎用データから汎用に使える特徴表現を一度で学習することです。これが実現できれば、個別の視覚タスクをゼロからトレーニングする必要がなくなり、全ての視覚タスクがそれぞれ個別に大量データを用意する必要はなくなります。しかし、その目標を達成するためには、研究コミュニティ内に既存および将来の手法を評価できる統一されたベンチマークが存在している必要があります。
この問題に対処するために、「ビジュアルタスク適合ベンチマーク(VTAB:Visual Task Adaptation Benchmark)」(GitHubから入手可能)をリリースしています。
VTABは、1つの原則に基づいた、多様で現実的でチャレンジングな特徴表現ベンチマークです。VTABの原則とは「より良い特徴表現とは、学習時に未見のデータに対してパフォーマンスを向上できる特徴です。例え、そのタスク用に利用できるデータが限られている状況であっても」です。
VTABは自然画像分類のImageNet、自然言語処理のGLUE、強化学習のAtariなど、機械学習(ML)の他の分野の進歩を促進したベンチマークに触発されました。
VTABはこれらと同様のガイドラインに従います。
(i)創造性を促進するために制約は最小限に留める
(ii)実務的に考慮が必要な項目に焦点を当てる
(iii)進化を促進するための挑戦的で困難なタスク
ベンチマーク
VTABは、視覚的特徴表現の有用な進化を測定するために設計された評価手法です。学習アルゴリズムが解決しなければならない一連の視覚タスク群から構成されています。評価対象のアルゴリズムは、事前に視覚的特徴表現を使用して訓練する事で過大評価されてしまう懸念があるため、以下の2つの要件を満たす必要があります。
(i)下流評価タスクで使用されるデータ(ラベルまたは入力画像)を使って事前にトレーニングしてはなりません。
(ii)ハードコーディングされたタスク固有のロジックを含めることはできません。言い換えれば、評価タスクはテストセットのように未見のデータとして扱われる必要があります。
これらの制約により、VTABで評価した際に良い成績を収める手法が将来の視覚的タスクに一般化できるようになります。
VTABによる評価は、広い範囲から集めた視覚の集合から引き出された多数の独立したタスクにアルゴリズムを適用(下図の左下の(A))する事から始まります。
アルゴリズムは、視覚的特徴表現を含むモデルを生成するために上流データで事前トレーニングされる場合があります。しかし、各下流タスクに対応するために、各下流タスクの小さなトレーニングセットに対する適合戦略を定義し、個々のタスク固有の予測を行うモデルを返す必要もあります。 アルゴリズムの最終スコアは、タスク全体の平均テストスコアです。
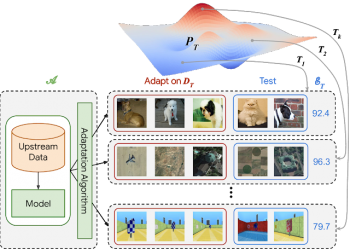
VTABの概要
アルゴリズムAは、広範囲な視覚問題の集まりであるPtから引き出された多数のタスクTに適用されます。この例では、ペットの分類、リモートセンシング、迷路の位置特定などのタスクが示されています。
VTABには、様々な領域にまたがる19の評価タスクが含まれており、自然(natural)、専門(specialized)、構造(structured)の3つのグループに分かれています。「自然」の画像タスクには、一般的なオブジェクト、きめ細かい分類、または抽象概念を表す、標準的なカメラで撮影された自然界の画像が含まれます。「専門」タスクでは、医療画像やリモートセンシングなどの専門機器を使用してキャプチャした画像を利用します。「構造」タスクは、多くの場合、3Dシーン内のオブジェクトまでの距離の予測(DeepMind Labなど)、オブジェクトのカウント(CLEVRなど)、向きの検出(例、特徴表現解きほぐしのためのdSprites)などです。
非常に多様ですが、VTABの全てのタスクは1つの共通の機能を共有します。すなわち、ほんの数例でトレーニングしただけで、人々は比較的簡単にそれらのタスクを実行できる事です。データが限られている新しいタスクへのアルゴリズムの一般化を評価するために、パフォーマンスはタスクごとに1000のサンプルを使用して評価されます。従来の研究と比較するために、完全なデータセットを使用した評価も実行できます。
3.VTAB:視覚タスク用のベンチマーク(1/2)関連リンク
1)ai.googleblog.com
The Visual Task Adaptation Benchmark
2)arxiv.org
The Visual Task Adaptation Benchmark
S4L: Self-Supervised Semi-Supervised Learning
3)github.com
google-research/task_adaptation
