
1.人工知能はサイズを大きくすると今までできなかった事が突然できるようになる(1/2)まとめ
・大きな人工知能の性能は小さな人工知能の性能傾向を元に予測可能な事が多い
・ある種のタスクは人工知能が特定のサイズを超えると突然性能が向上し始める
・小規模モデルには存在しないが大規模モデルには存在する能力について調査
2.創発的能力とは?
以下、ai.googleblog.comより「Characterizing Emergent Phenomena in Large Language Models」の意訳です。元記事の投稿は2022年11月10日、Jason WeiさんとYi Tayさんによる投稿です。
創発(Emergent)とは日本語でも耳慣れない言葉ですが、人工知能関連の文脈で出てきた場合は、ある能力が突然開花する事です。
今回のお話は物凄く興味深いのです。例えば、人間の赤ちゃんも身体の成長と共に創発的に能力を開発していくわけではないですか?
立つ事、発声する事、言葉を使う事、相手と会話をする事、世界を意識する事、感情を持つ事などなど。何らかの急激な変化が起こる転換点があって、ある日、突然、能力が開花したように見えると。
人工知能も同じようにモデルのサイズを拡大する事で、創発的に能力が開発されていくのだとしたら、そう、ちょっと前に「意識を得た人工知能」として話題になったLaMDAのお話をどうしても思い出すのです。
Googleの人工知能LaMDAは本当に意識を得たのか?(1/3)
Googleの人工知能LaMDAは本当に意識を得たのか?(2/3)
Googleの人工知能LaMDAは本当に意識を得たのか?(3/3)
言語モデルに関しての調査なのですから、対話型チャットボットに関する調査も絶対にやってると思うのですが、特に言及されてないのですよね。「まだ私達の知らない能力があるのかもしれませんね~」みたいな事は言ってますが。
アイキャッチ画像はstable diffusionの1.5版の生成で創発的に能力を開花させたトトロ
自然言語処理(NLP:Natural Language Processing)の分野は、大量のテキストデータで学習させた言語モデルによって革命を起こしてきました。言語モデルのサイズを拡大することで、下流のさまざまなNLPタスクのパフォーマンスとサンプル効率が向上することがよくあります。
多くの場合、大規模な言語モデルの性能は、小規模なモデルの性能傾向を元に予測することができます。例えば、言語モデルの文脈に応じて適切な単語を絞り込む性能に対する規模の効果は、経験則的に7桁以上にも及ぶことが示されています。
一方、他のある種のタスクについては、予測可能な形で性能が向上するわけではありません。例えば、GPT-3の論文では、複数桁の足し算を解く言語モデルの能力は、モデルのパラメータが1億から130億までは(ほぼランダムな回答と等しいレベルの正答率のままで)わずかに性能が向上していきますが、130億を超えた時点で性能が大きく飛躍することが示されています。
自然言語処理の研究や応用において言語モデルの利用が拡大していることを考えると、予期せず発生する可能性のあるこのような能力をよりよく理解することが重要です。
TMLR(Transactions on Machine Learning Research)で発表された論文「Emergent Abilities of Large Language Models」では、小規模なモデルには存在しないが、大規模なモデルには存在する能力として定義される創発的な能力(emergent abilities)について議論します。
具体的には、言語モデルの性能を、総浮動小数点演算数(FLOPs)、すなわち言語モデルの学習に使われた計算量の関数として分析することで、創発を研究しています。
しかし、私達はデータセットサイズやモデルパラメータ数など、他の変数の関数としても創発を調査しています。(詳細は論文をご覧ください)
全体として、私達は言語モデルをスケールアップすることによって生じる創発能力の数十の例を提示します。このような創発能力の存在は、さらなるスケーリングによって言語モデルの能力の幅をさらに広げられる可能性があるか?という問題を提起しています。
プロンプトに関する創発的なタスク
まず、プロンプトタスクで生じる可能性のある創発的な能力について説明します。このようなタスクでは、事前に学習した言語モデルに次の単語予測というタスクのプロンプトを与え、応答を完了させることでタスクを実行させます。このようなタスクでは、言語モデルをさらに微調整することなく、学習時には見た事がなかったタスクを実行できることが多くあります。
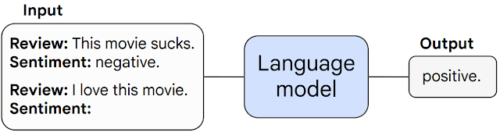
映画レビューの感情分類に関する少数回プロンプトの例
このモデルはタスクとして1つの例文(映画レビューを肯定的か否定的に分類する)を与えられると、学習中に見た事のない例文に対して感情分類タスクを実行可能です。
私達は、プロンプトタスクが特定の規模の閾値でそれまでのランダムな性能からランダム以上の性能に予測不可能に急増するとき、それを創発(emergent)と呼びます。
以下では、複数回の計算が求められる問題、大学レベルの試験問題、単語の意味の特定という3つの事例で、タスクに関する創発パフォーマンスを紹介します。いずれの場合も、言語モデルの性能は低く、ある閾値まではモデルサイズにほとんど依存しませんが、ある閾値から突然性能が向上し始めます。
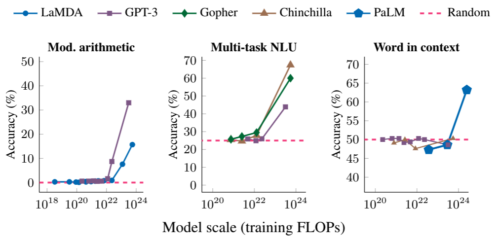
複数回の計算が求められる問題(左)、大学レベルの試験での正答(中)、文脈から単語の意味を特定する(右)能力はすべて、十分に大きなスケールのモデルに対してのみ現れるものです。モデルには、LaMDA、GPT-3、Gopher、Chinchilla、PaLMが含まれます。
例えば、算術計算とマルチタスクの自然言語理解(NLU:Natural Language Understanding)タスクでは\(10^{22}\)FLOPs以上、文脈中の単語タスクでは\(10^{24}\)FLOPs以上のモデルで、これらのタスクの性能がランダムに近い性能ではなくなります。
なお、タスクやモデルによって創発が起こる規模は異なりますが、どのモデルもこれらのタスクの性能が徐々に改善されることはありませんでした。その他、数十の創発的なプロンプトタスクが論文に掲載されています。
3.人工知能はサイズを大きくすると今までできなかった事が突然できるようになる(1/2)関連リンク
1)ai.googleblog.com
Characterizing Emergent Phenomena in Large Language Models
2)openreview.net
Emergent Abilities of Large Language Models

