
1.ビットコイン急落時の日本語ツイートをGPT-3で感情分類するまとめ
・プロンプトエンジニアリングは性能だけではなく料金にも影響するのでとても大事
・現在公開されている4モデルは価格差が結構あり高性能モデルは非常に高くなる
・ビットコインが下がったら買いたいと思っている人は多いのかもしれない
2.GPT-3のTweet classifierとは?
アイキャッチ画像のクレジットはPhoto by Executium on Unsplash
2022年9月1日からgpt-3の各モデルの価格改定が行われるそうです。モデルによっては私が確かめた当時の1/3ぐらいの値段になるそうなので、以下の事例は価格を1/3に割り引いて読んでください。
| MODEL名 | 従来の価格 | 2022年9月1日以降の新価格 |
| Davinci | $0.06 / 1k tokens | $0.02 / 1k tokens |
| Curie | $0.006 / 1k tokens | $0.002 / 1k tokens |
| Babbage | $0.0012 / 1k tokens | $0.0005 / 1k tokens |
| Ada | $0.0008 / 1k tokens | $0.0004 / 1k tokens |
| Davinci Embeddings | $0.6 / 1k tokens | $0.2 / 1k tokens |
| Curie Embeddings | $0.06 / 1k tokens | $0.02 / 1k tokens |
| Babbage Embeddings | $0.012 / 1k tokens | $0.005 / 1k tokens |
| Ada Embeddings | $0.008 / 1k tokens | $0.004 / 1k tokens |
先日、ビットコインが急落したというニュースがありました。
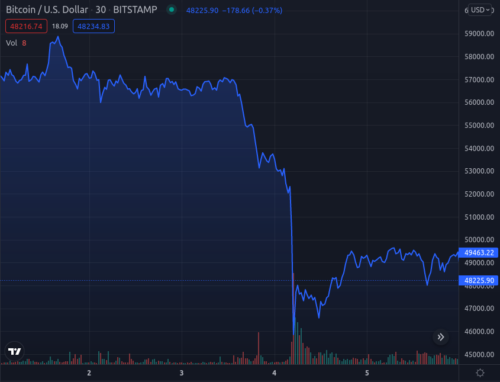
12月4日の夜に急落しています。
ビットコインの急落は珍しくないかもしれませんが、このグラフを見て、やっぱりTwitter上では阿鼻叫喚になってるのかしらん?と思ったのです。
でも、Twitterって多国語が飛び交っているので感情分類って簡単に出来ないよね?
しかし、GPT-3だと言語が混ざっていても分類出来るのかな?
と言うのが今回のチャレンジの発端です。
結論から言うと多国語が混ざった状態での分類は以下の理由により出来ませんでした。
・Tweetの数が多すぎるがGPT-3の無料枠($18)が少なすぎる
・言語が混在した状態での分類性能を検証する事が難しい
以下、試行錯誤の結果です。
一日にTwitterに投稿されるTweetは5億を超えていると聞いた事がありますが、重複やスパム投稿などを極力除いて、日本語に絞っても該当時間帯のbitcoin or ビットコイン関連のTweetの数は以下のようになります。急落した時間帯に急増してますね。
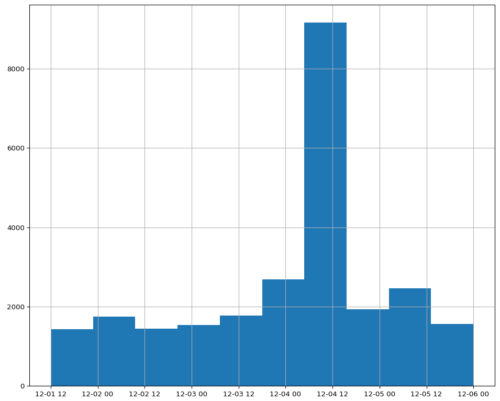
さて、GPT-3でTweetの分類をする方法ですがTwitterの感情分類用のプロンプト「Tweet classifier」がサンプルとして用意されています。以下、引用すると
プロンプト
This is a tweet sentiment classifier
Tweet: “I loved the new Batman movie!”
Sentiment: Positive
###
Tweet: “I hate it when my phone battery dies.”
Sentiment: Negative
###
Tweet: “My day has been 👍”
Sentiment: Positive
###
Tweet: “This is the link to the article”
Sentiment: Neutral
###
Tweet: “This new music video blew my mind”
Sentiment:
レスポンス
つまり、緑枠のプロンプトの太字部分の「This new music video blew my mind」を自分が分類したいTweetに差し替えて、Pythonモジュールとしても提供されているOpenAI APIで緑枠のプロンプトを含めて全部をドーンと送ると、「Positive」 or 「Negative」 or 「Neutral」のいずれかがバーンっと返却されるのです。
え?ちょっと待ってよ、これって毎回プロンプトを全部送らなきゃならんのですか?
と思ったのですが、どうも私の調べた限り毎回送らなければいけないようなのです。
一応、前半のTweet部分を日本語のTweetに差し替えて、分類して欲しいTweetも日本語のものに差し替えてドーンと送ると、日本語でもかなりの精度で感情分類が出来ているようではあります。
しかし、4モデルの中で一番お高いDavinci(ダビンチ)モデルで、試行錯誤しつつ、どうにか200ツイートを分類(つまり200回送る)させたところ、なんとお値段この時点で500円!前回のPlayGroundで$0.21を使っていますが、
無料枠の1/3近い「$4.91 / $18.00」を費やしてしまった事に!
ダビンチ先生のお給金高すぎ問題!
そう、プロンプトの前半部分もちゃんとトークン単位で課金されるので、無駄に毎回送るプロンプトが長いとその部分もしっかり課金されます。
え?プロンプトエンジニアリングって、毎回送るテキストを可能な限り少なくして課金額を抑えつつ、分類性能に影響が出ないようにするとか、そんな工夫も求められるの?
というか、言語が混在している際のプロンプトってどうやればエエんじゃい?
まぁ、いずれにしても英語+日本語だけでも該当期間のtweetは70万件以上あったので相当絞っても残りの無料枠では到底全部を分類する事は無理なので、この時点で日本語のみに絞る事にしました。
で、上記のようにプロンプトを与えて続きの文章を補完させる使い方は「Completions」なのですが、ラベル付きデータを与えて、それを参考に分類してもらう「Classification」と言う使い方もベータ版ながら存在します。
そのため、先ほど、ダビンチ先生に作って頂いた200ラベルをファイルとしてアップロードして、これを使って分類してくだしゃい、ダビンチ先生お給金高すぎなので二番目にお給金が高いCurie(キュリー)先生お願いします!
とやってみたところ、数十件くらい処理したところで、「似た文章見つからないからもっと沢山のサンプルをアップするか、クエリを調整するといいわよ(「No similar documents were found in file with ID ‘file-xxxxxxxxxxxx.Please upload more documents or adjust your query.」)」とご指摘頂き、マダムキュリー先生にはお仕事を完遂して頂けず。
困った!しかし、もうしょうがないので伯爵夫人なのでダビンチ先生の1/75の一番お安いお給金で働いて頂けるAda(エイダ)先生にTweet classifier形式でお願いするしかない!って事で、プロンプトも少し調整し、エイダ・ラブレス伯爵夫人様に10000件のツイート分類をお願いした結果が以下。
残予算枠 $8.03 / $18.00
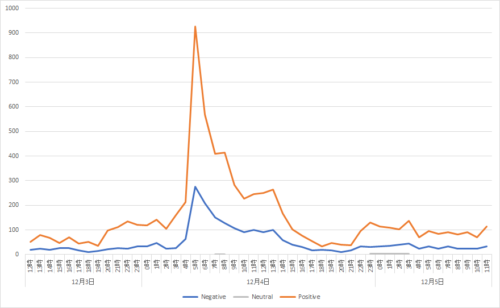
Ada先生の分類を信じるのであれば、赤(Positive)のツイート件数が青(Negative)を一貫して上回っています。
もちろん、Twitter上で本音をTweetしていない人もいるかもしれませんし、強がってる人、買い煽りしている人など、様々な事は考えられますが、「ビットコインが下がったら買いたいと思っている人は多い」と言う事なのかもしれませんね。

