
1.Implicit BC:ロボットが優柔不断な行動を学習しないようにする(1/2)まとめ
・ロボットは複雑な行動を模倣しようとしたときに優柔不断になる事がある
・決断力を向上させるため離散化された行動空間を使用する事が多いが欠点がある
・この欠点を持たない新アプローチとして暗黙の行動クローニングを提唱した
2.Implicit BCとは?
以下、ai.googleblog.comより「Decisiveness in Imitation Learning for Robots」の意訳です。元記事は2021年11月19日、Pete FlorenceさんとCorey Lynchさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Dylan Hunter on Unsplas
ここ数年でロボットの学習はかなり進歩しましたが、ロボットエージェントのポリシーによっては、正確で複雑な行動を模倣しようとしたときに、確固とした行動を選択することができない場合があります。
例えば、ロボットがテーブルの上でブロックを滑らせて、所定位置に正確に配置しようとするタスクがあるとします。この課題を解決するには、さまざまな方法が考えられ、どの方法も正確な動作とその微修正動作が必要です。
ロボットは多くの選択肢の中から1つだけを選択しなければなりませんが、ブロックが予想以上に滑ってしまった場合には、その都度計画を変更することもできなければなりません。
これは簡単に思えるかもしれませんが、最近の学習型ロボットは、優柔不断で不正確な行動を学習してしまうことが良くあります。

今回の比較対象となる明示的行動クローニングモデル(explicit behavior cloning model)の例
ロボットがブロックをテーブルの上で滑らせ、それを固定具に正確に挿入するタスクに苦戦しています。
ロボットの決断力を高めるために、研究者はしばしば離散化された行動空間(discretized action space)を利用します。これにより、ロボットは選択肢の間で揺れ動くことなく、選択肢Aまたは選択肢Bを選択することになります。
例えば、離散化は、私たちが最近開発したTransporter Networksアーキテクチャの重要な要素であり、AlphaGoやAlphaStar、OpenAIのDota botなど、ゲームをプレイするエージェントが成し遂げた多くの重要な成果にも共通しています。
しかし、離散化には限界があります。空間的に連続した現実世界で活動するロボットにとって、離散化には少なくとも以下の2つの欠点があるのです。
(1)精度に限界があること
(2)次元の呪い(curse of dimensionality)が発生すること
これに関連して、3Dコンピュータビジョンの研究分野では、離散化された特徴表現ではなく、連続的な特徴表現が近年の大きな進歩の原動力となっています。
離散化による欠陥を持たない決定的なポリシーを学習することを目的として、本日、模倣学習(imitation learning)への新しいシンプルなアプローチであり、先週CoRL2021で発表された「暗黙の行動クローニング(Implicit BC:Implicit Behavioral Cloning)」のオープンソース実装を発表します。
私たちは、Implicit BCが正確で断固とした行動が求められるような「シミュレーション内のベンチマークタスク」と「実世界のロボットタスク」の両方で強力なスコアを達成することを発見しました。
これらのタスクには、私たちのチームが最近開発したオフライン強化学習のベンチマーク「D4RL」の中の、人間の専門家によるタスクで最先端(SOTA:state-of-the-art)の結果を達成したことも含まれます。
これらのタスクの7つのうち6つで、Implicit BCは、オフラインRLの従来の最良の手法であるConservative Q Learningを上回りました。興味深いことに、Implicit BCは報酬情報を必要とせずにこれらの結果を達成しています。つまり、複雑な強化学習ではなく、比較的単純な教師付き学習を用いることができるのです。
Implicit BC
私たちのアプローチは行動クローニングの一種であり、ロボットがデモンストレーションから新しいスキルを学ぶ最も単純な方法であると言えます。行動クローニングでは、エージェントは標準的な教師付き学習を用いて専門家の実演行動を模倣する方法を学びます。従来、行動クローニングでは、観察結果を受け取り、専門家の行動を出力する明示的なニューラルネットワーク(下図左)を学習していました。
Implicit BCの鍵となるアイデアは、行動クローニングをエネルギーベースのモデリング問題に変えることです。
すなわち、ニューラルネットワークを訓練するのではなく、観察と行動を観察して取り込んで専門家の行動に対しては低く、非専門家の行動に対しては高くなる単一の数値を出力させます。(下図、右)
学習後、Implicit BCポリシーは、与えられた観察に対して最も低いスコアを持つ行動入力を見つけることで行動を生成します。
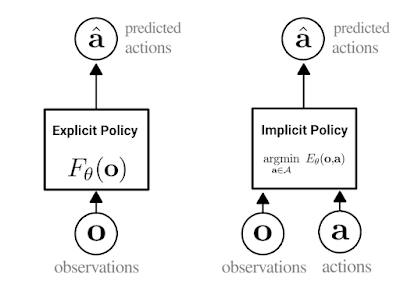
明示的ポリシー(左)と暗黙的ポリシー(右)の違いの概要図
暗黙的なポリシーでは、「argmin」は、特定の観測値とペアになったときに、エネルギー関数の値を最小化するアクションを意味します。
Implicit BCモデルを学習するために、InfoNCE損失を使用しています。これは、データセット内の専門家の行動に対しては低いエネルギーを出力し、それ以外の行動に対しては高いエネルギーを出力するようにネットワークを訓練するものです。(下記参照)。
興味深いのは、観測値と行動の両方をモデルに取り込むというアイデアは、強化学習では一般的ですが、教師ありポリシー学習ではそうではないということです。

暗黙的なモデルが不連続性(discontinuities)をどのようにフィットさせるかのアニメーション
この例では、ステップ(Heaviside)関数にフィットさせるために暗黙的なモデルをトレーニングしています。
左:黒(X)の学習点をフィッティングした二次元グラフ。色はエネルギーの値を表す(青は低く、茶は高い)
中:学習中のエネルギーモデルの三次元図
右:トレーニングの損失曲線
3.Implicit BC:ロボットが優柔不断な行動を学習しないようにする(1/2)関連リンク
1)ai.googleblog.com
Decisiveness in Imitation Learning for Robots
2)arxiv.org
Implicit Behavioral Cloning
3)github.com
google-research / ibc

