
1.プライバシーに配慮しながら医療現場の略語を解読可能な機械学習を実現(2/2)まとめ
・略語展開タスクは構造化されていないため性能計測が困難であったが新規にアルゴリズムを開発した
・医療用略語に対する理解は一般人で30%未満、医師で90%程度であったがモデルは98%を達成
・医師が特に非省略形にする必要がないと考えてしまう略語や専門外領域の略語がスコアの差に繋がった
2.人間の医者と人工知能の略語展開性能の比較
以下、ai.googleblog.comより「Google Research, 2022 & beyond: Responsible AI」の意訳です。元記事の投稿は2023年1月24日、Marian Croakさんの投稿です。
アイキャッチ画像はstable diffusionのカスタムモデルによる生成。
タンパク質整列用アルゴリズムを医療文書に使用
略語展開という特殊なタスクに対するこれらのモデルの評価は困難です。これらのモデルは構造化されていない文章を出力するため、入力のどの略語が出力のどの拡張に対応するかを把握する必要がありました。
そこで、分子生物学における分岐配列(divergent sequence)を整列するために考案されたNeedleman Wunschアルゴリズムの改良版を作成し、モデルの入力と出力を位置合わせして、対応する略語-拡張のペアを抽出することに成功しました。この整列手法を用いることで、モデルが略語を正確に検出し、展開する能力を評価することができました。
様々なサイズ(パラメータ数6000万から600億以上)のText-to-Text Transfer Transformer(T5)モデルを評価した結果、大きなモデルは小さなモデルよりも翻訳性能が高く、最大のモデルが最高の性能を達成することがわかりました。
新しい推論連鎖手法を開発してモデルを実現
しかし、私たちは予想外のことを発見しました。実際の臨床記録から得た複数の外部テストセットで性能を評価したところ、モデルが一部の略語を展開しないままにしてしまうこと、さらに、大きなモデルでは不完全な展開の問題がより深刻であることがわかったのです。
これは主に、Web上の非略語を略語に置き換えてラベルを作成しているのに、原文に最初から存在する略語がラベルを持たない事に起因しています。つまり、略語が個々のラベルとして使われる原文、及び入力として使われる書き直された文章の両方に現れるので、モデルは略語を展開しない事を学習してしまうのです。
そこで、モデルの出力を再び入力として与え、モデルが非略語の展開に自信を持っている限り、さらに非略語を展開するように仕向ける推論連鎖手法を新たに開発しました。技術的には、ある対数尤度の閾値以上のビーム探索の出力を調べるという、エリシティブ推論(elicitive inference)と呼ばれる手法が最も有効です。エリシティブ推論を用いることで、複数の外部テストセットにおいて、最先端の略語展開能力を実現することができました。
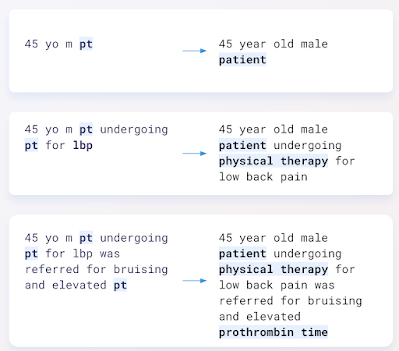
モデルの入力(左)と出力(右)の実例
性能比較
また、患者や医師が診断書を解読する際にどのように実行しているのか、そして私達のモデルがどのような能力を発揮しているのかについても調査しました。その結果、一般人(医学の専門的な教育を受けていない人)は、サンプルに含まれる略語の理解度が30%未満であることが分かりました。Google検索を使用させると、理解度は75%近くまで上昇しましたが、それでも5つの略語のうち1つは判読できませんでした。当然のことながら、医学生や訓練を受けた医師は、このタスクで90%の精度でより良い結果を出しました。私たちの最大のモデルは、98%の精度で、専門家と同等以上の能力を発揮することがわかりました。
このタスクにおいて、なぜモデルは医師と比べてこれほどまでに優れたパフォーマンスを発揮できるのでしょうか?
モデルの高い性能には、2つの重要な要因があります。一つは、臨床医が展開しようとしない略語(センチメートルを表す「cm」など)が存在し、それが測定スコアを一部低下させたことです。これはどうでもいいことのように思えるかもしれませんが、英語を話さない人にとっては、これらの略語は馴染みがないため、書いてもらうと助かるかもしれません。
これに対し、私達のモデルは略語を包括的に展開するように設計されています。また、臨床医は自分の専門分野でよく目にする略語に慣れていますが、それ以外の専門家は専門外の人には理解できない略語を使います。私たちのモデルは、複数の専門分野にわたる何千もの略語について訓練されているため、幅広い用語を解読することができます。
健康状態の理解の向上に向けて
大規模言語モデル(LLM:Large Language Models)は、患者が見たり読んだりする情報を補強できるので、患者の健康に関する理解の向上に役立つ多くの手段になると考えています。ほとんどのLLMは、臨床記録データとは似ても似つかないデータで訓練されており、臨床記録データの独特な分布は、これらのモデルをすぐに使えるようにすることを困難にしています。私たちはこの制限を克服する方法を示しました。このモデルはまた、臨床記録データを「正規化」し、あらゆる教育レベル、健康に関する理解レベルの患者にとって文章を理解しやすくするMLの追加機能を促進するものです。
謝辞
この研究はYuchen Liu, Jonas Kemp, Benny Li, Ming-Jun Chen, Yi Zhang, Afroz Mohiddin, そしてJuraj Gottweisとの共同作業として行われました。Lisa Williams, Yun Liu, Arelene Chung, Andrew Daiには、この研究に関して多くの有益な会話と議論を提供していただきました。
3.プライバシーに配慮しながら医療現場の略語を解読可能な機械学習を実現(2/2)関連リンク
1)ai.googleblog.com
Deciphering clinical abbreviations with privacy protecting ML
2)www.nature.com
Deciphering clinical abbreviations with a privacy protecting machine learning system

