
1.RCE:報酬関数が不要な強化学習(2/2)まとめ
・自律エージェントに成功事例を提供する事でタスクを実行するように教える方法を提案
・本手法では報酬関数の設計もエキスパートがデモして成功操作を見せる必要がなくなる
・ユーザーの能力の違いに影響を受けないようにRCEを設計する事は将来的な課題
2.事例の再帰的分類
以下、ai.googleblog.comより「Recursive Classification: Replacing Rewards with Examples in RL」の意訳です。元記事の投稿は2021年3月24日、Benjamin Eysenbachさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Fausto Marqués on Unsplash
RCE(事例の再帰的分類)
RCEアプローチの背後にある直感は単純です。モデルは、「世界の現在の状態」と「エージェントが実行しているアクション」を考慮して、エージェントが将来タスクを解決するかどうかを予測する必要があります。
どの状態とアクションのペアが将来の成功につながり、どの状態とアクションのペアが将来の失敗に繋がるかを指定するデータがあれば、標準的な教師あり学習を使用してこの問題を解決できます。
ただし、利用可能なデータが成功例のみで構成されている場合、システムはどの状態とアクションが成功につながったかを認識しません。また、システムには環境との相互作用の経験がありますが、この経験は成功につながるかどうかというラベルは付けられていません。
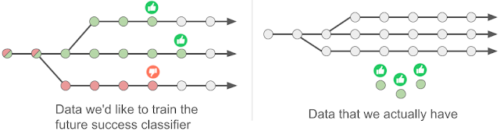
左:従来手法の重要なアイデアは、タスクが将来解決されるかどうか(親指上向き or 親指下向き)を軌道のすべての状態(円)について予測する「将来の成功分類器(future success classifier)」を学習することです。
右:事例ベースの制御アプローチでは、モデルにはラベルのない経験(灰色の円)と成功事例(緑色の円)のみが提供されるため、標準の教師あり学習を適用することはできません。代わりに、モデルは成功例を使用して、ラベルのない経験に自動的にラベルを付けます。
しかしそれでも、これらのデータが利用可能であれば、現在の状態がどのように見えるかをまとめることができます。
まず、定義上、成功する事例は、与えられたタスクを解決するものでなければなりません。第2に、任意の状態とアクションのペアがタスクの解決に成功するかどうかは不明ですが、エージェントが次の状態で開始した場合にタスクが解決される可能性は見積もることができます。次の状態が将来の成功につながる可能性が高い場合、現在の状態も将来の成功につながる可能性が高いと見なすことができます。事実上、これは再帰的な分類であり、ラベルは次のタイムステップでの予測に基づいて推測されます。
将来のタイムステップでモデルの予測を現在のタイムステップのラベルとして使用するという基本的なアルゴリズムの考え方は、Q学習や後継特徴(successor features)などの既存の時間差法(temporal-difference methods)によく似ています。主な違いは、ここで説明するアプローチは報酬関数を必要としないことです。それにもかかわらず、この方法は、時間差法と同じ理論的収束保証の多くを継承することを示します。実際には、RCEを実装するには、既存のQラーニング実装に数行のコードを変更するだけで済みます。
評価
さまざまな困難なロボット操作タスクでRCE手法を評価しました。例えば、あるタスクでは、ロボットハンドでハンマーを拾い、釘をボードに打ち込む必要がありました。このタスクに関する以前の研究は、複雑な報酬関数(手とハンマーの間の距離、ハンマーと釘の間の距離、および釘がボードにノックインされたかどうかに対応)を使用していました。対照的に、RCE法では、釘をボードに打ち込んだ場合に世界がどのように見えるかを数回観察するだけで済みます。
RCEのパフォーマンスを、明示的な報酬関数を学習する手法や模倣学習に基づく手法など、このタスクの解決に苦労しているいくつかの従来の手法と比較しました。この実験では、事例に基づく制御により、ユーザーが複雑なタスクを簡単に指定できることを強調し、再帰的分類によってこれらの種類のタスクを正常に解決できることを示します。
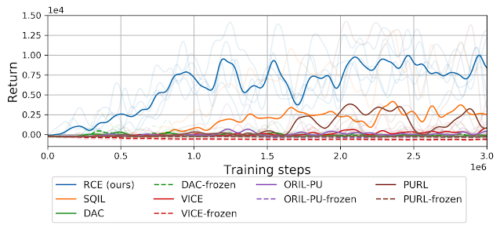
RCEアプローチは、従来手法(模倣学習[SQIL、DAC]および明示的な報酬関数[VICE、ORIL、PURL]に基づくアプローチ)と比較して、確実に釘をボードに打ち込むタスクを解決します。
結論
自律エージェントに成功事例を提供することにより、タスクを実行するように教える方法を提示しました。この手法では報酬関数を細心の注意を払って設計したり、主人公視点でデモ操作を行う必要がなくなります。
本ホワイトペーパーで解説する事例ベースの制御の重要な側面は、様々な異なるユーザーの能力についてシステムがどのような仮定をするかです。ユーザーの能力の違いに影響を受けないRCEの変種を設計することは、現実世界のロボット工学アプリケーションにとって重要な場合があります。(訳注:要は成功事例を提供する必要があると言う事は、ユーザが成功事例を提供する能力を備えている事を暗黙のうちに仮定していると言うお話のようです)
コードはGithubで利用可能であり、プロジェクトのWebサイト(ben-eysenbach.github.io)には、学習した動作に関する追加のビデオが含まれています。
謝辞
共著者のRuslan SalakhutdinovとSergey Levineに感謝します。また、この投稿に感想をくれたSurya Bhupatiraju、Kamyar Ghasemipour、Max Igl、Harini Kannan、およびこの投稿内の作図のデザインを手伝ってくれたTom Smallにも感謝します。
3.RCE:報酬関数が不要な強化学習(2/2)関連リンク
1)ai.googleblog.com
Recursive Classification: Replacing Rewards with Examples in RL
2)arxiv.org
Replacing Rewards with Examples: Example-Based Policy Search via Recursive Classification
3)ben-eysenbach.github.io
Replacing Rewards with Examples: Example-Based Policy Search via Recursive Classification
4)github.com
google-research/rce/

