
1.TensorFlow 3Dによる3Dシーンの理解(1/2)まとめ
・3Dセンサーの普及が進んでおり三次元データを処理できるテクノロジーが求められている
・3Dデータに適用できるツールとリソースは限られており分野への参入は困難な場合がある
・三次元データ用ディープラーニング機能をTensorFlowに組み込んだTensorFlow 3Dを発表
2.TensorFlow 3Dとは?
以下、ai.googleblog.comより「3D Scene Understanding with TensorFlow 3D」の意訳です。元記事の投稿は2021年2月11日、 Alireza FathiさんとRui Huangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Leo Foureaux on Unsplash
過去数年間で3Dセンサー(Lidar、深度検知カメラ、深度検知レーダーなど)の普及が進んでいるため、これらのデバイスが捕捉するデータを処理できるシーン理解テクノロジーが必要になっています。 このようなテクノロジーにより、自動運転車やロボットなどのこれらのセンサーを使用する機械学習(ML:machine learning)システムが実世界で道案内や行動ができるようになり、モバイルデバイスで拡張現実体験を向上させることも可能になります。
コンピュータビジョンの分野は、モバイル3D物体検出、透明物体検出などのモデルを含む3Dシーンの理解において最近順調に進歩し始めていますが、3Dデータに適用できる可用性ツールとリソースが限られているため、この分野への参入は困難な場合があります。
3Dシーンの理解を更に向上させ、関心のある研究者の参入障壁を減らすために、3Dディープラーニング機能をTensorFlowに組み込むように設計された高度にモジュール化された効率的なライブラリであるTensorFlow 3D(TF 3D)をリリースします。
TF 3Dは、幅広い研究コミュニティが最先端の3Dシーン理解モデルを開発、トレーニング、および展開できるようにする、良く使われる操作、損失関数、データ処理ツール、モデル、および測定基準のセットを提供します。
TF 3Dには、分散トレーニングをサポートする、最先端の3Dセマンティックセグメンテーション、3D物体検出、および3Dインスタンスセグメンテーションのためのトレーニングおよび評価パイプラインが含まれています。
また、3D物体の形状予測、点群の登録、点群の高密度化など、他の潜在的なアプリケーションも可能にします。更に、標準的な3Dシーン理解データセットのトレーニングと評価のための統一されたデータセット仕様と構成を提供します。
現在、Waymo Open、ScanNet、Rioのデータセットをサポートしています。ただし、ユーザーはNuScenesやKittiなどの他の人気のあるデータセットを同様の形式に自由に変換し、既存または独自に作成したパイプラインで使用できます。また、TF 3Dを活用して、新しいアイデアの迅速なプロトタイピングや試行からリアルタイム推論システムの展開まで、さまざまな3Dディープラーニングの研究とアプリケーションを実現できます。
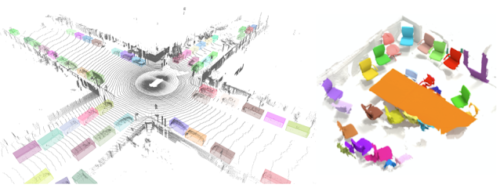
Waymo OpenDatasetのフレーム上でTF 3Dを使い3D物体検出モデルが出力した例を左側に示します。ScanNetデータセットの3Dインスタンスセグメンテーションモデルの出力例を右側に示します。
本稿では、TF 3Dで提供される効率的で構成可能なスパース畳み込みバックボーンを紹介します。
これは、様々な3Dシーン理解タスクで最先端の結果を達成するための鍵です。更に、TF 3Dが現在サポートしている3つのパイプライン(3Dセマンティックセグメンテーション、3D物体検出、3Dインスタンスセグメンテーション)のそれぞれについて説明します。
3Dスパース畳み込みネットワーク
センサーによって捕捉された3Dデータは、多くの場合、関心のある物体のセット(車、歩行者など)を含むシーンで構成されます。このシーンの大部分は、あまり関心がない(あるいは全くない)オープンスペースに囲まれています。
そのため、3Dデータは本質的にまばら(sparse、スパース)です。このような環境では、畳み込みの標準的な実装は計算量が多く、大量のメモリを消費します。そのため、TF 3Dでは、3Dスパースデータをより効率的に処理するように設計された部分多様体スパース畳み込み(submanifold sparse convolution)およびプーリング操作を使用します。
スパース畳み込みモデルは、ほとんどの屋外自動運転(Waymo、NuScenesなど)および屋内ベンチマーク(ScanNetなど)に適用される最先端の方法の中核です。
また、さまざまなCUDA手法を使用して、計算を高速化します。(例えば、ハッシュ、共有メモリでのフィルターのパーティション化/キャッシュ、ビット演算の使用)Waymo Openデータセットでの実験によると、この実装は、既存のTensorFlow操作を使用して適切に設計された実装よりも約20倍高速です。
次に、TF 3Dは、3D部分多様体スパースU-Netアーキテクチャを使用して、各3D画素の特徴表現を抽出します。U-Netアーキテクチャは、ネットワークに粗い特徴と細かい特徴の両方を抽出させ、それらを組み合わせて予測を行う事が出来るので、効果的であることが証明されています。U-Netネットワークは、エンコーダー、ボトルネック、およびデコーダーの3つのモジュールで構成され、各モジュールは、プールまたはアンプール操作が可能な多数のスパース畳み込みブロックで構成されます。
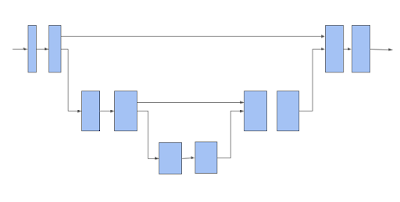
3DスパースボクセルU-Netアーキテクチャ
水平矢印は3D画素特徴表現を取り込み、部分多様体のスパース畳み込みを適用することに注意してください。下に移動している矢印は、部分多様体のスパースプーリングを実行します。上に移動する矢印は、プールされた特徴表現を集めて、水平矢印からの特徴表現と連結し、連結された特徴表現に対して部分多様体のスパース畳み込みを実行します。
3.TensorFlow 3Dによる3Dシーンの理解(1/2)関連リンク
1)ai.googleblog.com
3D Scene Understanding with TensorFlow 3D
2)github.com
google-research / tf3d
3)arxiv.org
DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes

