
1.PaLI:言語-画像モデルを100以上の言語に規模拡大(2/2)まとめ
・全タスクを単一の汎用API経由で実施する事でタスク間の知識共有を行った
・PaLIは難易度の高い汎用的な視覚-言語ベンチマークで最先端の結果を達成
・視覚と言語の両モデルを規模拡大する事が最高のパフォーマンスをもたらした
2.PaLIの性能
以下、ai.googleblog.comより「PaLI: Scaling Language-Image Learning in 100+ Languages」の意訳です。元記事は2022年9月15日、Xi ChenさんとXiao Wangさんによる投稿です。
アイキャッチ画像はstable diffusionによる生成
大規模言語-画像モデルの学習
視覚-言語タスクは、異なる能力を必要とし、時には目標が異なることもあります。あるタスクでは、正確に解くために対象物の局所的な位置を特定する事が本質的に必要ですが、他のタスクではより大域的な視点が必要な場合があります。同様に、タスクによっては、長文の回答や簡潔な回答を必要とする場合もあります。
これらの目的に対応するため、私達はWebLIの豊富な事前学習データを活用し、様々な下流のアプリケーションに対応するモデルを準備する混合事前学習タスクを導入しました。
多種多様なタスクを解決するという目的を達成するため、すべてのタスクを単一の汎用API(入力:画像+テキスト、出力:テキスト)経由で実施する事で、複数の画像タスクと言語タスク間の知識共有を可能にしました。
このAPIは事前学習でも共有されています。これにより再利用されるモデルの能力の維持と、新しいタスク(例えば、画像説明のための分割説明文の付与、風景をテキストで理解するためのOCR予測、VQGおよびVQA予測など)を実行するためのモデルの訓練の両方を目的とした重みの混合を狙っています。
モデルの学習は、オープンソースのT5XとFlaxformerフレームワークを用いて、FlaxによるJAXで行います。視覚部については、ViT-eと名付けた大規模なViTアーキテクチャを導入し、オープンソースのBigVisionフレームワークを用いて40億のパラメータで学習させます。ViT-eはViT-G(パラメータ数20億)と同じレシピで作られています。
言語部では、密なトークンembeddingsと視覚成分で生成された断片embeddingsを連結し、mT5-XXLで初期化されるマルチモーダルエンコーダ・デコーダの入力とします。PaLIの学習中、この視覚部の重みは固定され、マルチモーダルエンコーダ・デコーダの重みのみが更新されます。
結果
PaLIを、多様で難易度の高い汎用的な視覚-言語ベンチマークで比較しました。PaLIのモデルは、これらのタスクにおいて最先端の結果を達成し、文献にある非常に大規模なモデルをも凌駕しています。
例えば、VQAや画像説明文付与の課題では、数倍大きいFlamingoモデル(パラメータ数800億)を凌駕する性能を発揮しています。また、主な学習目的ではない、言語のみ、視覚のみの困難なタスクでも性能を維持することができます。
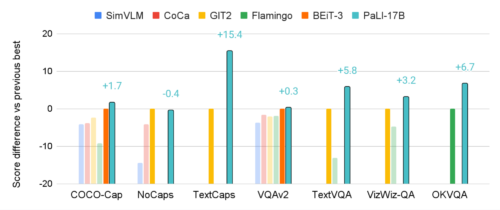
PaLI(170億パラメータ)は、複数の視覚・言語タスクにおいて、最先端アプローチ(SimVLM、CoCa、GIT2、Flamingo、BEiT3など)を凌駕する性能を示しました。この図では、PaLIの相対的な改良を強調するために、従来の最高モデルと比較したスコアの絶対的な差を示しています。公式な分割テストデータがある場合、それを使って比較しています。画像説明文付与タスクの評価にはCIDErスコアを用い、VQAタスクはVQA Accuracyで評価しています。
モデルの規模拡大結果
モデルの規模拡大に関して、画像モデルと言語モデルのどちらがどのように相互作用し、どこで最も性能向上が得られるかを検証しています。
その結果、両モデルを共同で規模拡大することが最高のパフォーマンスをもたらし、特に、比較的少ないパラメータで済む視覚部分を規模拡大することが最も重要であると結論付けました。また、規模拡大は、多言語タスク全体でより良いパフォーマンスを得るために重要です。
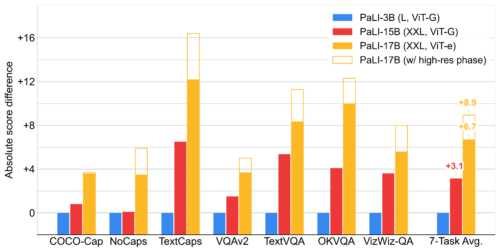
PaLIモデルの言語部分と視覚部分の両方の規模を拡大することは性能向上に寄与しています。図はPaLI-3Bモデルとのスコア差を示しています。画像説明文付与タスクはCIDErスコアで評価し、VQAタスクはVQA Accuracyで評価しています。
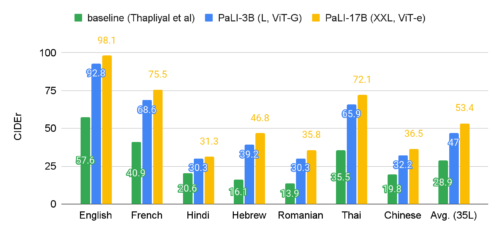
多言語の説明文付与はPaLIモデルの規模拡大により大きな恩恵を受けます。私達は35言語のベンチマークであるCrossmodal-3600でPaLIを評価しました。ここでは、35言語すべての平均スコアと、7つの多様な言語の個別スコアを提示しています。
モデルの内部調査 公平性、偏り、その他の潜在的な問題
大規模な言語モデルや画像モデルにおいて不公平な偏見が発生したり強化されたりしないようにするためには、まず、
(1)使用したデータとそのデータをモデルが使用する方法について透明性を確保する
(2)モデルの公平性を検証し、責任を持ってデータ分析を行う
ことが重要です。
(1)に関しては、データカードとモデルカードを掲載しました。(2)については、データセットの人口統計学的な分析結果を含んでいます。私たちはこれを最初の一歩と考え、私たちのモデルを新しいタスクに適用する際に、私たちのAI原則に沿って、潜在的な偏りを測定し緩和し続けることが重要であることを理解しています。
まとめ
様々な視覚-言語タスクを解決するために設計された規模拡大可能なマルチモーダル、多言語モデルであるPaLIを発表しました。私達は、視覚タスク、言語タスク、視覚-言語タスクにおいて、性能が向上したことを実証しました。私達の研究は、モデルの視覚と言語の両方の部分における規模の重要性と、2つの間の相互作用を示しています。
私達は、視覚と言語のタスク、特に複数の言語でのタスクを達成するためには、実際には大規模なモデルとデータが必要であり、さらなる規模拡大によって恩恵を受ける可能性があることを理解しています。この研究が、マルチモーダルモデルや多言語モデルのさらなる研究のきっかけとなることを願っています。
謝辞
この研究を実施した全ての著者に感謝します。
Soravit (Beer) Changpinyo, AJ Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, Alexander Kolesnikov, Joan Puigcerver, Nan Ding, Keran Rong, Hassan Akbari,Gaurav Mishra, Linting Xue, Ashish Thapliyal, James Bradbury, Weicheng Kuo, Mojtaba Seyedhosseini, Chao Jia, Burcu Karagol Ayan, Carlos Riquelme, Andreas Steiner, Anelia Angelova, Xiaohua Zhai, Neil Houlsby, Radu Soricut。
また、Claire Cui, Slav Petrov, Tania Bedrax-Weiss, Joelle Barral, Tom Duerig, Paul Natsev, Fernando Pereira, Jeff Dean, Jeremiah Harmsen, Zoubin Ghahramani, Erica Moreira, Victor Gomes, Sarah Laszlo, Kathy Meier-Hellstern, Susanna Ricco, Rich Lee, Austin Tarango, Emily Denton, Bo Pang, Wei Li, Jihyung Kil, Tomer Levinboim, Julien Amelot, Zhenhai Zhu, Xiangning Chen, Liang Chen, Filip Pavetic, Daniel Keysers, Matthias Minderer, Josip Djolonga, Ibrahim Alabdulmohsin, Mostafa Dehghani, Yi Tay, Elizabeth Adkison, James Cockerille, Eric Ni, Anna Davies, and Maysam Moussalemには示唆、改善、支援を頂きました。
また、Tom Smallには、このブログ記事のための視覚化を提供していただきました。
3.PaLI:言語-画像モデルを100以上の言語に規模拡大(2/2)関連リンク
1)ai.googleblog.com
PaLI: Scaling Language-Image Learning in 100+ Languages
2)arxiv.org
PaLI: A Jointly-Scaled Multilingual Language-Image Model

