
1.量子コンピューターで誤り訂正機能を実現(1/2)まとめ
・現世代の量子プロセッサは1操作あたりのエラー率が非常に高く、このままでは使用に耐えない
・将来の量子コンピューターは、量子エラー訂正機能を実装してエラー率を下げる必要がある
・量子反復コードを使用して、Sycamoreアーキテクチャに誤り訂正機能を実装する事に成功
2.量子エラー訂正とは?
以下、ai.googleblog.comより「Demonstrating the Fundamentals of Quantum Error Correction」の意訳です。元記事は2021年8月11日、Jimmy ChenさんとMatt McEwenさんによる投稿です。
しかし、まぁホントにGoogleの量子コンピューター研究は着々と前進してますね。量子の世界からコンピューターサイエンスの世界に移行してきているのが今回も感じ取れます。
反復するゲートをイメージしたアイキャッチ画像のクレジットはPhoto by JuniperPhoton on Unsplash
Google Quantum AIチームは、これまでで最大の量子化学シミュレーションだけでなく、超伝導量子ビット(superconducting quantum bits)で作られた量子プロセッサを構築し、世界で初めて古典的コンピューターの限界を超えた計算を達成しました。
ただし、現在の世代の量子プロセッサは、さまざまな有用なアルゴリズムに必要であると考えられている\(10^{-12}\)と比較して、操作あたり\(10^{-3}\)の範囲の高い操作エラー率となっています。エラー率のこの途方もないギャップを埋めるには、より良い量子ビットを作成するだけでは不十分です。将来の量子コンピューターは、量子エラー訂正(QEC:Quantum Error Correction)を使用する必要があります。
QECの中心的な考え方は、量子状態を多くの「物理データ量子ビット」に分散させることによって「論理量子ビット」を作成することです。物理エラーが発生した場合、量子ビットの特定の属性を繰り返しチェックすることでそれを検出し、修正できるようにして、論理キュービットでは状態エラーが発生するのを防ぎます。
複数の物理量子ビットに同時にエラーが発生した場合には論理エラーが発生する可能性がありますが、このエラーは、物理量子ビットを追加していけば指数関数的に減少するはずです(論理エラー発生させるために、より多くの物理量子ビットを関与させる必要が出て来るため)。
この指数関数的な規模拡大動作は、物理的な量子ビットエラーが十分に稀で独立出来ているかに依存しています。特に「1つの物理エラーが同時に多くの量子ビットに影響を与える事」や「エラー訂正時に多くのサイクルにわたって持続するような相関エラーを抑制する事」が重要です。このような相関エラーは、修正がより困難で論理エラーを引き起こしやすい、より複雑なエラー検出パターンを生成します。
私たちのチームは最近、量子反復コード(quantum repetition codes)を使用して、SycamoreアーキテクチャにQECのアイデアを実装しました。これらのコードは、「論理量子ビットをエンコードするデータ量子ビット」と「論理状態のエラーを検出するために使用する測定量子ビット」を交互に繰り返す1次元の量子ビットチェーンで構成されます。
これらの反復コードは一度に1種類の量子エラーしか訂正できませんが、より高度なエラー訂正コードと同じ要素がすべて含まれており、論理キュービットあたりの物理キュービットが少なくて済みます。そのため、論理量子ビットのサイズが大きくなるにつれて、論理エラーがどのように減少するかをよりよく調べることができます。
Nature Communicationsに掲載された「Removing leakage-induced correlated errors in superconducting quantum error correction」では、これらの反復コードを使用して、物理量子ビットの相関誤差の量を減らすための新しい手法を示します。次に、Natureに掲載された「Exponential suppression of bit or phase flip errors with repetitive error correction」では、QEC理論から得られる期待通りに、物理量子ビットを追加するにつれて、これらの反復コードの論理エラーが指数関数的に抑制されることを示します。
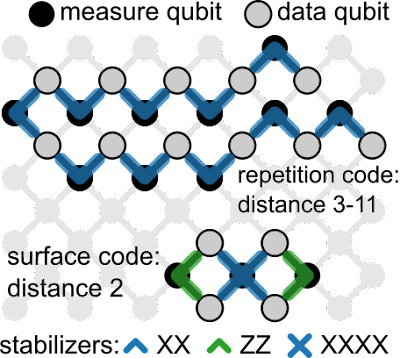
Sycamoreデバイスでの反復コード(21量子ビット、1Dチェーン)とdistance-2 surfaceコード(7量子ビット)のレイアウト
量子ビットのリーク
反復コードの目的は、「データ量子ビットの状態を直接測定せずに、データ量子ビットのエラーを検出すること」です。
これは、各データ量子ビットとそれらの共有測定量子ビットをペアにして絡ませることによって行われます。これにより、データ量子ビットの状態自体を通知せずに、それらのデータ量子ビットの状態が同じか異なるかチェック(つまり、パリティエラーチェック)を行う事ができます。このプロセスを1マイクロ秒だけ続くラウンドで何度も繰り返します。測定されたパリティがラウンド間で変化する場合、エラーが検出されます。
ただし、重要な課題の1つは、超伝導回路から量子ビットを作成する方法にあります。量子ビットに必要なエネルギー状態は、通常|0>と|1>の2つだけですが、デバイスには、|0>、|1>、|2>、|3>などのエネルギー状態の梯子があります。2つの最低エネルギー状態を使用して、計算に使用する情報で量子ビットをエンコードします。(これらを計算状態(computational states)と呼んでいます)。
より高いエネルギー状態(|2>, |3>以上)を使用して、忠実度の高い絡み合い操作を実現します。しかし、これらの絡み合い操作により、量子ビットがこれらのより高い状態に「リーク」し、リーク状態(leakage states)になる場合があります。
リーク状態の量子群は、操作が適用されるにつれて増加します。これにより、後続操作のエラーが増加し、他の近くの量子ビットもリークしはじめます。これは、特に困難な相関エラーの原因になります。 2015年初頭のエラー訂正に関する実験では、エラー訂正をさらに実行すると、リークが発生しパフォーマンスが低下することがわかりました。
リークの影響を軽減するには、マルチレベルリセットと呼ばれる、リーク状態を「空にする(empty out)」ことができる新しい種類の量子ビット操作を開発する必要がありました。量子ビットを操作して、読み出しに使用される構造にエネルギーを迅速に送り出し、チップからすばやく移動して、|2>または|3>で開始した場合でも、量子ビットを|0>状態に冷却します。
この操作をデータ量子ビットに適用すると、保護しようとしている論理状態が破壊されますが、データ量子ビットを乱すことなく、測定量子ビットに適用できます。すべてのラウンドの終わりに測定量子ビットをリセットすると、デバイスが動的に安定するため、リークが拡大および拡大し続けることがなくなり、デバイスが理想的な量子ビットのように動作できるようになります。
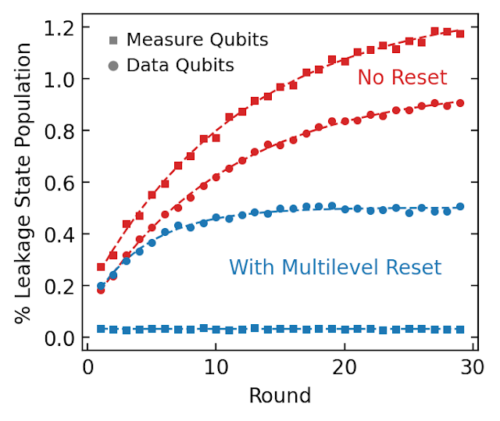
マルチレベルリセットゲートを測定量子ビットに適用すると、リークがほぼ完全に除去されると同時に、データ量子ビットでのリークの増加が減少します。
3.量子コンピューターで誤り訂正機能を実現(1/2)関連リンク
1)ai.googleblog.com
Demonstrating the Fundamentals of Quantum Error Correction
2)www.nature.com
Removing leakage-induced correlated errors in superconducting quantum error correction
Exponential suppression of bit or phase errors with cyclic error correction

