
1.ムーアの法則を凌駕する人工知能の開発競争まとめ
・人工知能を訓練するために使われた計算量は3.5カ月毎に2倍との試算をOpen AIが発表
・コンピューターの進化予測に使われるムーアの法則は1.5年(18カ月)毎に2倍
・今後も潤沢な投資を背景にこのペースでの開発競争が続くと見込まれる
2.Open AIの研究発表した「AI and Compute」
以下、openai.comより「AI and Compute」の抜粋です。元記事の投稿は2018年5月16日、Dario Amodeiさん、Danny Hernandezさん、Girish Sastryさん、Jack Clarkさん、Greg Brockmanさん、Ilya Sutskeverさんによる投稿です。
2020年11月追記)AI関連のアルゴリズムの効率性向上についての研究も発表されています。
Open AIから「2012年以降、大規模な人工知能を訓練するために使用された計算量は、3.5カ月毎に倍増している事がわかった」と発表があった。
コンピューターの将来の性能を予測する際に良く使われる有名なムーアの法則は「1.5年(18カ月)毎に2倍になる」である。2012年以降、人工知能の学習に使われた計算量は300,000倍になった。もし、ムーアの法則ベースで計算するとわずか12倍の伸びに留まる事になる。この計算機パワーの改善はAIの進歩にとって重要な要素であるため、この伸びが続く限り、現在の能力をはるかに超えた人工知能の出現に備える価値はある。
下記のグラフは比較的良く知られて情報も公開されている人工知能を訓練するために使用された総計算量をpetaFLOPS/日且つ、わかりやすいように対数変換(左軸の単位に注目)して示したものである。
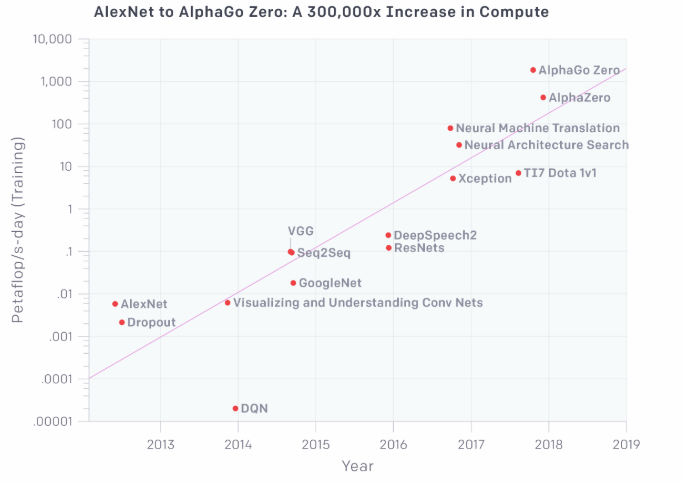
petaFLOPS/日とは、秒間1,015回のニューラルネットワーク操作または1,020回のオペレーションを一日中続ける事と定義する。計算機の瞬間的な性能を表現する最高演算性能ではなく、計算量で考える事によって、エネルギーで使われるKW/hのように、人工知能の規模感がイメージがしやすくなる。
Open AIでは、加算演算と乗算演算を別々の演算として数えた。加算も乗算も有効桁数は考慮せずにカウントしているため、厳密にはFLOPS(浮動小数点数演算能力)ではない。その他、アンサンブルモデルを無視する等、細かい事は付録部分で解説している。この試算の結果、計算量は「3.43カ月に2倍」となった。
3.Open AIの研究発表した「AI and Compute」概要
人工知能の進歩にとって需要な要因は3つある。
1)アルゴリズムの改良
2)学習用データ(ラベル付きデータ、会話データなど)
3)学習に利用できる計算機(つまり利用可能な計算量)
1)と2)は、定量的に観測する事が難しいが、3)は明確に定量化が可能であり、人工知能の進歩を測る手段として活用できる。もちろん、大規模な計算が、時には現在のアルゴリズムの欠陥を露呈させるだけで終わってしまう事もある。しかし、少なくとも現在の人工知能のほとんどの領域ではより多くの計算がより良いパフォーマンスに繋がっており、アルゴリズムの進化を補完する事が多い。
この分析では、計測すべき数値はGPUの速度や巨大なデータセンターの能力ではなく、1つのモデルを学習させるための必要な計算の量であるとOpen AIは考えている。これは、最高の人工知能がどれほど強力であるかを数字として示す事と考える事もできる。モデル毎の計算は、アルゴリズムやハードウェアの並列処理制限の影響を受ける実際の一括計算とは大きく異なる。この分析はモデル毎の必要な計算のみを考慮している。
その結果、計算量は、おおよそ毎年約10倍に増加している事がわかった。この傾向はカスタムハードウェア(GPUやTPU)の進化が部分的に主導しているが、主要な要因は、より多くのチップを並列動作させる方法の研究と、それを実現するための惜しみない投資が繰り返されてきたためである。
(1)時代区分
2012年以前
機械学習にGPUを使用する事は珍しかった。グラフに記載されているのと同程度の結果を達成する事は困難な時代。
2012年-2014年
沢山のGPUを同時に実行するようなインフラは珍しかった。1-8のGPUを使い、1-2TFLOPSで、0.001-0.1petaFLOPS/日が達成された。
2014年-2016年
巨大スケール、つまり、10-100のGPUを使い、5-10TFLOPSで、0.1-10petaFLOPS/日が達成された。しかし、収穫逓減の法則により、大規模並列学習が思うように成果をあげられなくなった。
2016年-2017年
並列アルゴリズムの改良(huge batch sizes,architecture search,Expert Iteration等)、及びTPUのような最適化されたハードウェアを使い、少なくとも一部のアプリケーションでは大きく性能を向上させる事ができた。
AlphaGoZeroとAlphaZeroは公表されている中では、最も大規模な並列処理アルゴリズムを利用した製品である。しかし、他の多くのアプリケーションも理論上は同等性能を実現可能であり、既に現実世界で非公表で使用されている可能性もある。
(2)楽しみな未来
グラフの傾向が続くと考えられる理由は複数ある。多くの新興企業がAI用途に特化したハードウェアを開発しており、その中には今後1-2年でFLOPS/Watt(FLOPS/$、つまりコストと相関がある)性能を大幅に向上させると主張しているものがある。同じ操作をより低いコストで達成できるのならば、単純にハードウェアを追加するだけで性能を向上させる事ができる。並列性の面でも、改良されたアルゴリズムは原理的には複数組み合わせる事が可能であり、architecture searchと大規模並列確率的勾配降下法など、パフォーマンスの向上が見込まれる。
その一方で、コストが並列実行性を制限し、演算装置の性能向上に物理的な制限が出てくる事も考えられる。Open AIは、現在の最高性能の人工知能を訓練させるための必要なハードウェアの価格は数百万ドルになると信じている。(償却コストはもっと安いが)。しかし、ほとんどの企業は学習済の人工知能を動作させるためのハードウェアしか購入しておらず、人工知能を学習させるためのより高性能なハードウェアにはまだこれから沢山のニーズが発生する。この需要は大きな経済的なインセンティブを生み出し、今後数年間は続くだろう。上記を考えると、ハードウェアの性能向上の傾向が短期間で終了すると考えるのは間違いである。
過去の傾向は、トレンドが将来にわたってどれくらいの期間続くか、及びその傾向が続く間に何が起こるかを予測するのに十分ではない。しかし、人工知能の急速な性能の向上が合理的に予測できるのであるのならば、人工知能の安全性と悪意ある利用に対する備えを開始する事は重要である。先見の明は、責任ある政策立案と責任ある技術開発に不可欠であり、傍観するのではなく傾向を先取りする必要がある。
4.Open AIの研究発表した「AI and Compute」感想
ムーアの法則はコンピュータの性能の進化の速さを表現する際に良く使われる指標で、1965年の発表と言われています。2年後には2.52倍、5年後には10.08倍、7年後には25.4倍、10年後には101.6倍、15年後には1024.0倍、と凄まじい速さの進化です。私の知っている限りでも過去に数回「技術的な限界があるため、これ以上ムーアの法則を維持する事はできない」と宣言された事がありますが、その度、限界を乗り越える方法を誰かが発見し維持されてきました。
しかし、OpenAIの発表によれば、人工知能の開発競争はムーアの法則が遅く見える程の速さであるとの事。前述の対数変換したグラフを直線ベースにすると下記のようになり、囲碁の世界チャンピオンに勝って有名になったAlphaGo zeroとAlphaZeroが突出した異常値にも見えてしまいます。
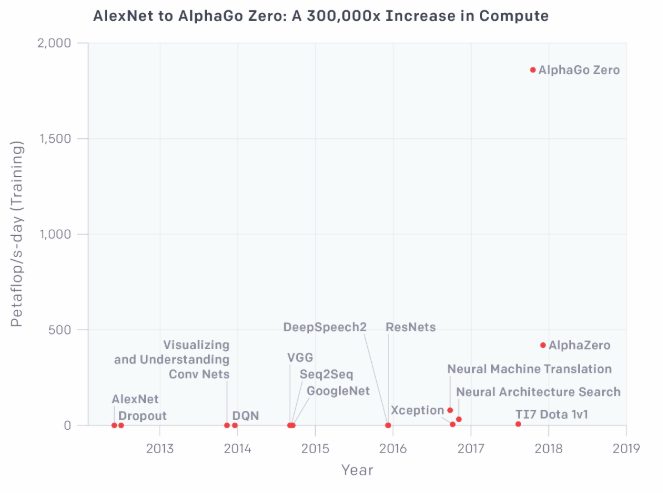
しかし、本文中にもありますが、公表されていないだけで同規模の人工知能はおそらく他にも存在するでしょうし、Googleが先日発表したTPUv3の記事を読むと、実感値としても「3.5カ月毎に倍増」に違和感はないですね。
本当にすごい時代であり、ワクワクするような事でもあるのですが、「個人のライフプラン」として考えると進化の速度が速すぎて世の中の仕組みが追いついていないとも感じます。AIが人間の仕事を奪う脅威論を産業革命時代の機械打ちこわしのラッダイト運動(つまり過去にも同様な懸念はあったが杞憂で終わった事)と見なす考え方はある程度は同意できるのですが、産業革命って数カ月毎に工場の生産量が倍増するレベルで技術が進歩したのでしょうか?
5.Open AIの研究発表した「AI and Compute」関連リンク
1)blog.openai.com
AI and Compute

