
1.暗記は学習ではありません!機械学習で過学習を防ぐための6つの手法まとめ
・過剰適合とはモデルが学習に使ったトレーニング用データに特化しすぎる事
・過剰適合は、トレーニングエラーとテストエラーの違いから検出可能
・過剰適合の防止はデータ、モデル、トレーニングのどれかを改善する事で可能
2.過学習とは?
以下、hackernoon.comより「Memorizing is not learning! — 6 tricks to prevent overfitting in machine learning.」の意訳です。元記事の投稿は2018年3月21日、Julien Despoisさんによる投稿です。
overfitting、すなわちオーバーフィッティングは日本語訳としては過学習の方が良く使われていると思いますが、過適合や過剰適合の方が意味合いとしては合っている気がするので以下過剰適合としています。
直感的に過剰適合が説明出来ているのではないかと自画自賛したアイキャッチ画像のクレジットはPhoto by Alex Shaw on Unsplash
前書き
過剰適合は、機械学習の最も苛立たしい問題かもしれません。この記事では、過剰適合とは何であるのか?過剰適合を見つける方法、そして最も重要なこととして、過剰適合が起こらないようにする方法を見ていきます。
過剰適合とは何でしょうか?
過剰適合(overfitting、過学習)という言葉は「モデルが学習に使ったトレーニング用データに特化しすぎる事」です。モデルは、トレーニングデータが示す全般的なデータの分布傾向を学習する代わりに、トレーニングデータ内の各データポイントそのものを学習してしまいます。
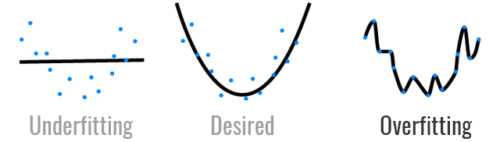
これは、数式を理解するのではなく、クイズのように答えを覚えるのと同じです。このため、モデルをトレーニングデータ外のデータも扱えるように一般化することはできません。トレーニングデータのみを扱う慣れ親しんだ領域にいる限り、全てが良好ですが、トレーニングデータ外のデータに出会うとすぐに道に迷います。

この小さなロボットは掛け算の仕方を知らないようです。彼はすでに見た質問の答えを覚えているだけです。
油断ならないのは、トレーニングデータを扱っている限りエラーが非常に小さいため、一見、モデルが正常に機能しているように見える場合があることです。ただし、新しいデータポイントを予測するように要求するとすぐに、失敗します。
過剰適合を検出する方法
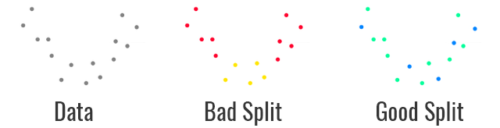
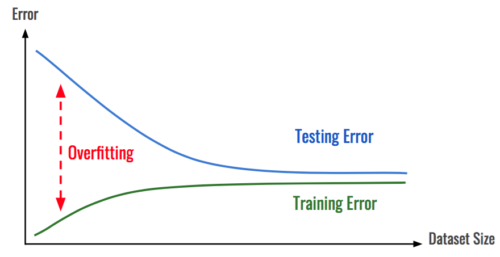
前述のように、過剰適合は、モデルが一般化できないことを特徴としています。この特徴をテストする簡単な方法は、データセットをトレーニングセットとテストセットの2つの部分に分割することです。
あなたがモデルを選択するとき、データセットを3つに分割することをお勧めします。
その理由を以下で説明します。
(1)トレーニングセットには、利用可能なデータの約80%を割り当て、モデルのトレーニングに使用します。(あなたはご存じですよね?)
(2)テストセットは、データセットの残りの20%で構成され、トレーニング中に出現しなかったデータに対するモデルの精度をテストするために使用されます。
この分割により、各セットでモデルのパフォーマンスをチェックして、トレーニングプロセスがどのように進行しているかについての洞察を得て、過剰適合が発生したときに見つけることができます。
以下の表は、さまざまなケースを示しています。
| トレーニングエラーが低くなる | トレーニングエラーが高くなる | |
| テストエラーが低くなる | モデルは学習中です! | 貴方の書いたプログラムにミスがあるか、あなたは心霊AIの開発に成功しました |
| テストエラーが高くなる | モデルの過剰適合が始まっています! | モデルは学習してません |
過剰適合は、トレーニングエラーとテストエラーの違いと見なすことができます。
注:この手法を機能させるには、両方の部分が代表的なデータを含んでいる事を確認する必要があります。データを分割(Split)する前に、データセットの順序をシャッフルすることをお勧めします。
過剰適合は、直前に素晴らしいモデルが完成したかのように希望を高めてから、その希望を残酷に押しつぶすため、かなりの落胆を招く可能性があります。幸いなことに、過剰適合を防ぐいくつかの手法があります。
過剰適合を防ぐ方法 モデルとデータ
まず、私達のシステムを構成する部品を調べて解決策を見つけることができます。つまり、使用しているデータやモデルを変更することを意味します。
#1
より多くのデータを収集する
モデル内に保存できる情報はそれほど多くありません。これは、与えるトレーニングデータが多いほど、過剰適合する可能性が低くなることを意味します。その理由は、データを追加すると、モデルがすべてのサンプルに対して過剰適合する事ができなくなり、学習を進めるために一般化する必要が出てきます。
より多くのデータを収集することは、すべてのデータサイエンスタスクの最初のステップとなる必要があります。データが増えると、モデルの精度が向上し、過剰適合の可能性が減少するためです。
#2
データを水増ししたりノイズを加える
より多くのデータを収集することは、退屈で費用のかかるプロセスです。それができない場合は、データがより多様であるかのように見せかけるようにする必要があります。
これを行うには、データ拡張手法を使用して、サンプルがモデルによって処理されるたびに、前回とわずかに異なるようにデータを水増しします。これにより、モデルが各サンプルの要素を学習するのが難しくなります。

反復して行われる各学習時に、モデルは元のサンプルの異なるバリエーションを見る事になります。
もう1つの良い方法は、ノイズを追加することです。
入力へ:これはデータ水増しと同じ目的を果たしますが、モデルを実際に遭遇する可能性のある自然なブレに対して耐久性を高めるためにも機能します。
出力へ:繰り返しますが、これによりトレーニングはより多様化されます。
注:どちらの場合も、ノイズの大きさが大きすぎないことを確認する必要があります。そうしないと、入力の情報をノイズでそれぞれダメにしたり、出力を不正確にしたりする可能性があります。どちらもトレーニングプロセスを妨げます。
#3
モデルを簡素化する
現在の全てのデータを使用しても、モデルがトレーニングデータセットを過剰適合させることができる場合は、モデルが強力すぎる可能性があります。次の試みとして、モデルの複雑さの軽減を試みることができます。
以前に述べたように、モデルは一定量のデータにしか適合できません。
複雑さ(ランダムフォレスト内の推定量の数やニューラルネットワーク内のパラメーターの数など)を徐々に減らすことで、モデルを過剰適合しないように単純にすることができます。その上でデータから学習するのに十分な複雑さを保つようにすることができます。
そのためには、モデルの複雑さに応じて、テストエラーとトレーニングエラーの両方のエラーを確認すると便利です。
これには、モデルを軽量化し、トレーニングを高速化し、実行を高速化するという利点もあります。
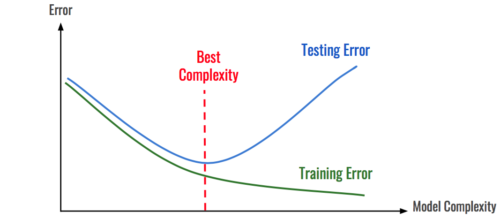
左端のモデルは単純すぎます。右側に進むにつれてオーバーフィットしていきます。
過剰適合を防ぐ方法 トレーニングプロセスの改善
2番目の可能性は、トレーニングの方法を変更することです。これには、損失関数、またはトレーニング中にモデルが機能する方法の変更が含まれます。
#4
早期終了(Early Termination)
ほとんどの場合、モデルはデータの正しい分布を学習する事から開始し、ある時点からデータに過剰適合し始めます。この移行が発生する瞬間を特定することにより、過剰適合が発生する前に学習プロセスを停止できます。前述の手法と同様に、これは時間経過に伴って推移するトレーニングエラー率を調べることによって実行可能になります。
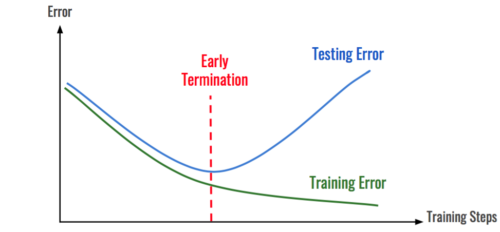
テストエラーが増え始めたら、学習をストップしましょう。
過剰適合を防ぐ方法 正則化(Regularization)
正則化は、モデルの学習を制約して過剰適合を減らすプロセスです。
それは多くの異なる形をとることができます、それらのいくつかを見ていきましょう。
#5
L1正則化とL2正則化
正則化の最も強力でよく知られている手法の1つは、損失関数にペナルティを追加することです。最も一般的なものはL1およびL2と呼ばれます。
(1)L1ペナルティは、重みの絶対値を最小化することを目的としています
(2)L2ペナルティは、重みの2乗の大きさを最小化することを目的としています。
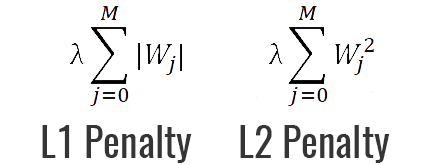
ペナルティがあるため、モデルは重みを好き放題に大きくすることができなくなり、重みの大きさを妥協する必要が出てきます。これにより、モデルがより汎用的になり、過剰適合との戦いに役立ちます。
L1ペナルティには、特徴表現の取捨選択を強制するという追加の利点があります。つまり、有用性の低いパラメーターを0に設定するように促す傾向があります。これは、データセット内で最も関連性の高い特徴表現を特定するのに役立ちます。欠点は、L2ペナルティほど計算効率が良くないことが多いことです。
重み行列は以下のようになります。L1行列が多くのゼロを持つまばらな(sparse、スパース)構造であり、L2行列の重みはわずかに小さいことに注意してください。

もう1つの可能性は、トレーニング中にパラメーターにノイズを追加することです。これは、一般化に役立ちます。
#6
ディープラーニングの場合:DropoutとDropconnect
この非常に効果的な手法は、ニューラルネットワークが層から層へと情報を伝播して処理するという事実に依存しているため、複数層(レイヤー)を持つディープラーニングに固有のものです。
アイデアは、トレーニング中にニューロン、またはニューロン間の接続のいずれかをランダムに非アクティブ化することです。ニューロンを非アクティブ化する場合はドロップアウト、または接続の場合はドロップコネクトと呼びます。
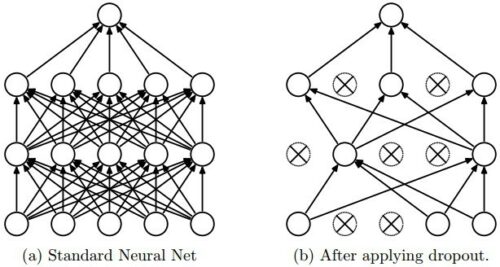
これにより、特定のニューロンや接続に依存する特定の特徴表現を抽出できなくなるため、ネットワークが冗長になります。トレーニングが完了すると、すべてのニューロンと接続が復元されます。この手法は、一般化を優先するアンサンブルアプローチを使用することとある程度同等であるため、過剰適合が減少することが示されています。
結論
ご存知のように、過剰適合はデータサイエンティストが直面しなければならない主要な問題の1つです。それを止める方法がわからない場合、対処するのは本当に苦痛になる可能性があります。この記事で紹介する手法を使用すると、モデルが学習プロセスでズルをするのを防ぎ、適切な結果を得ることができるはずです。
あなたは学び終えました!
この記事を楽しんでいただけたでしょうか。もしそうなら、イイネをして、共有して、あなたの猫にそれを説明してあげてください。mediumで私をフォローするなり、またはあなたがやりたいと思うことを何でも試してみてください!
3.暗記は学習ではありません!機械学習での過剰適合を防ぐための6つの手法関連リンク
1)hackernoon.com
Memorizing is not learning! — 6 tricks to prevent overfitting in machine learning.

