
1.TensorFlow 3Dによる3Dシーンの理解(2/2)まとめ
・スパース畳み込みネットワークをバックボーンにヘッドを追加して様々なタスクを実行可能
・3Dセマンティックセグメンテーション、3Dインスタンスセグメンテーションは三次元を対象
・3D物体検出モデルは、三次元画素毎のサイズ、中心、回転行列、セマンティックスコアを予測
2.3DスパースU-Net
以下、ai.googleblog.comより「3D Scene Understanding with TensorFlow 3D」の意訳です。元記事の投稿は2021年2月11日、 Alireza FathiさんとRui Huangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Leo Foureaux on Unsplash
前述のスパース畳み込みネットワークは、TF 3Dで提供される3Dシーン理解パイプラインのバックボーンです。以下で説明する各モデルは、このバックボーンネットワークを使用して疎な三次元画素の特徴を抽出し、1つまたは複数の追加の予測ヘッドを追加して対象のタスクを推測します。
ユーザーは、エンコーダー/デコーダー層の数と各層の畳み込みの数を変更することにより、U-Netネットワークを構成できます。畳み込みフィルターのサイズを変更することにより、さまざまなバックボーン構成を通じて、速度と精度のさまざまなトレードオフも検討できます。
3Dセマンティックセグメンテーション
3Dセマンティックセグメンテーションモデルには、三次元画素(voxel、ボクセル)毎のセマンティックスコアを予測するための出力ヘッドが1つだけあります。これらのスコアはポイントにマッピングされ、ポイント毎のセマンティックラベルを予測します。

ScanNetデータセットからの屋内シーンの3Dセマンティックセグメンテーション
3Dインスタンスセグメンテーション
3Dインスタンスのセグメンテーションでは、セマンティクスの予測に加えて、同じ物体に属する三次元画素をグループ化することが目標です。TF 3Dで使用される3Dインスタンスセグメンテーションアルゴリズムは、ディープメトリック学習を使用した2D画像セグメンテーションに関する従来の研究に基づいています。
モデルは、三次元画素毎のインスタンスembeddingベクトルと、各ボクセルのセマンティックスコアを予測します。 インスタンスembedding ベクトルは、三次元画素をembedding空間にマップします。embedding空間では、同じ物体のインスタンスに対応する三次元画素は互いに近く、異なる物体に対応する三次元画素は遠く離れています。この場合、入力は画像ではなく点群であり、2D画像ネットワークではなく3Dスパースネットワークを使用します。推論時に、貪欲アルゴリズム(greedy algorithm)は一度に1つのインスタンスシードを選択し、三次元画素embedding間の距離を使用してそれらをセグメントにグループ化します。
3D物体検出
3D物体検出モデルは、三次元画素毎のサイズ、中心、回転行列、および物体のセマンティックスコアを予測します。推論時に、ボックス提案メカニズムを使用して、数十万の三次元画素毎のボックス予測をいくつかの正確なボックス提案に減らし、トレーニング時に、ボックス予測と分類損失を三次元画素毎の予測に適用します。
予測されたボックスの角と真のボックスの角の間の距離にHuber損失を適用します。サイズ、中心、回転行列からボックスの角を推定する関数は微分可能であるため、損失は自動的にそれらの予測された物体の属性に伝播します。真のボックスと強く重なるボックスをポジティブとして分類し、重ならないボックスをネガティブとして分類する動的ボックス分類損失を使用します。

ScanNetデータセットでの3D物体検出結果
私達が最近発表した論文「DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes」では、TF3Dでの物体検出に使用される単一ステージの弱い教師あり学習アルゴリズムについて詳しく説明します。
更に、フォローアップ研究は、時間情報を活用するために3Dオブジェクト検出モデルを拡張し、スパースLSTMベースのマルチフレームモデルを提案しました。更にこの時間モデルがWaymo Openデータセットでフレームごとのアプローチを7.5%上回っていることを示します。
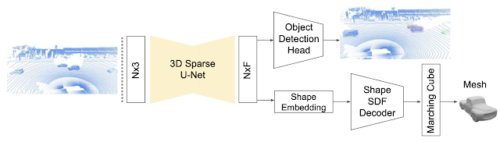
DOPSの論文で紹介された3D物体検出および形状予測モデル
3DスパースU-Netを使用して、各三次元画素の特徴表現ベクトルを抽出します。
物体検出モジュールは、これらの特徴を使用して3Dボックスとセマンティックスコアを提案します。同時に、ネットワークの他のブランチは、各オブジェクトのメッシュを出力するために使用される形状embeddingを予測します。
始める準備はできましたか?
このコードベースが3Dコンピュータビジョンプロジェクトに役立つことは確かです。あなたにとってもそうなることを願っています。コードベースへの貢献は大歓迎です。フレームワークの今後の更新にご期待ください。開始するには、githubリポジトリにアクセスしてください。
謝辞
TensorFlow 3Dコードベースとモデルのリリースは、Googleの研究者間の広範なコラボレーションと製品グループからのフィードバックとテストの結果です。特に、Alireza FathiとRui Huang(Google在籍中に行われた作業)による主要な貢献を強調したいとと思います。また、Guangda Lai、Abhijit Kundu、Pei Sun、Thomas Funkhouser、David Ross、Caroline Pantofaru、Johanna Wald、Angela Dai、MatthiasNiessnerに特に追加の謝意を表します。
3.TensorFlow 3Dによる3Dシーンの理解(2/2)関連リンク
1)ai.googleblog.com
3D Scene Understanding with TensorFlow 3D
2)github.com
google-research / tf3d
3)arxiv.org
DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes

