
1.Loss-Conditional Training:損失関数を改良してモデルのバリエーションを統合(1/2)まとめ
・多くの機械学習アプリケーションでは、モデルのパフォーマンスを一つの数値で表現する事ができない
・画質と圧縮率のようなトレードオフの関係にある数値は損失関数の係数として扱う事が多い
・用途に応じて係数のペアを変更した複数のモデルを作って対応する事が現在の主流だが統合できないか検討
2.Loss-Conditional Trainingとは?
以下、ai.googleblog.comより「Optimizing Multiple Loss Functions with Loss-Conditional Training」の意訳です。元記事の投稿は2020年4月27日、Alexey Dosovitskiyさんによる投稿です。
lossで頑張って探しても、どうしても暗いイメージの画像しかなかったので、losしかあってないけれどもLos Angelesで、筋トレ好きであれば一度は耳にした事があるであろうMuscle Beachのアイキャッチ画像のクレジットはPhoto by Kevin McCutcheon on Unsplash
多くの機械学習アプリケーションでは、モデルのパフォーマンスを一つの数値で表現する事はできません。パフォーマンスは様々な側面から測定されるからです。
例えば、「学習ベースの画像圧縮(learned image compression)」を行うモデルは、画像を圧縮してサイズを最小化しつつ、画質を最大化する必要があります。圧縮率と画質はトレードオフの関係にあり、両立は根本的に矛盾しています。
また、限定的なリソースでモデルを動かさねばならない場合などもあり、関心のある全ての値を同時に最適化することは、しばしば不可能になります。
従って、現実世界では、追求したいパフォーマンスの間でバランスをとる方法を決定する必要があります。

画像圧縮における画像品質とファイルサイズの間のトレードオフ
理想的は、画像の歪みとファイルサイズの両方を最小化する事ですが、これら2つの目的は根本的に矛盾しています。
異なるパフォーマンス間でバランスをとる必要があるモデルをトレーニングする標準的なアプローチは、それらのパフォーマンスを測定する多項式、すなわち損失関数を調整する事です。
例えば、画像圧縮の場合、損失関数には、画像品質と圧縮率に対応する2つの項が含まれます。これらの項の係数を調整する事で、圧縮率と画質のどちらを重視するかをトレーニングの目的として定める事ができます。
モデルが求められている品質間のトレードオフ(例えば画質と圧縮率)を解決する必要がある場合、標準的な方法は、異なった損失関数を使って何パターンかモデルを個別にトレーニングする事です。
これを実現するには、トレーニングの際も推論の際も複数のモデルをメンテナンスする必要があるため、非常に非効率的です。
ただし、これらのモデルのバリエーションは非常に密接に関連した問題を扱っているので、モデル間で一部の情報を共有可能なのではないかと推測できます。
ICLR 2020で受理された2つの論文では、様々なトレードオフに対して複数のモデルをトレーニングする非効率を回避し、代わりにそれら全てをカバーする単一のモデルを使用する、シンプルで広く適用可能なアプローチを提案します。
論文「You Only Train Once: Loss-Conditional Training of Deep Networks」では、この手法の一般的な定式化を提供し、これを変分オートエンコーダーや画像圧縮などのいくつかのタスクに適用しています。
また、論文「Adjustable Real-time Style Transfer」では、 スタイル転送に本手法を適用する手法について詳しく説明しています。
Loss-Conditional Training
私たちのアプローチの背後にある考え方は、係数のセットごとにモデルをトレーニングするのではなく、損失関数の係数の全ての選択肢をカバーする単一のモデルをトレーニングすることです。
これを実現するには、
(1)モデルを単一の損失関数ではなく損失の分布でトレーニングします。
(2)モデルの出力を損失項の係数ベクトルで調整します。
このようにして推論時にベクトルを調整することで、異なる係数を持つ損失関数に対応するモデルの空間を横断的に扱う事ができます。
このトレーニング手順は、スタイル転送タスクを例にすると以下の図で示されます。
トレーニング時には、最初に損失係数がランダムにサンプリングされます。この損失係数は2つの用途で用いられます。損失の計算と、調整ネットワーク(conditioning network)を介してメインネットワークを調整する用途です。システム全体がエンドツーエンドで同時にトレーニングされます。つまり、モデルのパラメータは、ランダムにサンプリングされた損失関数と同時にトレーニングされます。
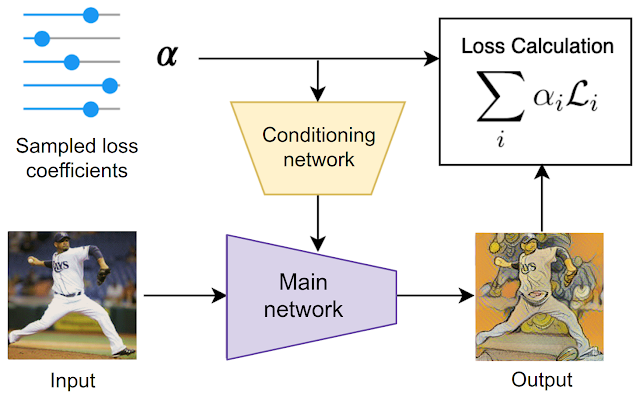
スタイル転送を例とした本手法の概要
中心となるスタイル化ネットワーク(stylization network)は、ランダムにサンプリングされた損失関数の係数を使って調整され、損失関数の分布でトレーニングされます。
その結果、一群の損失関数でモデルを学習している事になります。
3.Loss-Conditional Training:損失関数を改良してモデルのバリエーションを統合(1/2)関連リンク
1)ai.googleblog.com
Optimizing Multiple Loss Functions with Loss-Conditional Training
2)openreview.net
YOU ONLY TRAIN ONCE:LOSS-CONDITIONAL TRAINING OF DEEP NETWORKS(PDF)
ADJUSTABLE REAL-TIME STYLE TRANSFER (PDF)
3)sites.google.com
Adjustable Real-Time Style Transfer


コメント