
1.人間による評価を使って要約を学ぶ(3/4)まとめ
・初期要約モデル、人間が要約品質を定量化、報酬モデル、RLによる微調整の4ステップで実現
・要約品質の定量化はラベル付け作業者に高い報酬と緊密な連携を取る事で実現した
・報酬モデルを最適化すると、最終的にサンプルの品質が低下してしまう事がわかった
2.報酬モデルの最適化
以下、openai.comより「Learning to Summarize with Human Feedback」の意訳です。元記事の投稿は2020年9月4日、Jeffrey Wuさん、Ryan Loweさん、Long Ouyangさん、Nisan Stiennonさん、Paul Christianoさん、Daniel Zieglerさん、Chelsea Vossさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Aaron Burden on Unsplash
手法
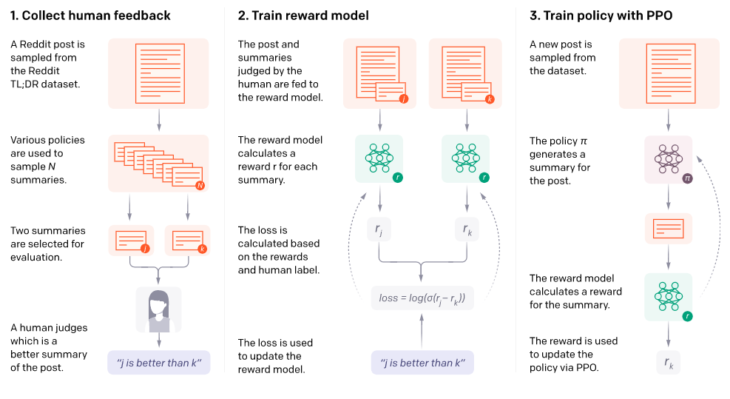
以前の作業で使用したものと同様の概要図
私たちのコアメソッドは4つのステップで構成されています。
・初期要約モデルのトレーニング
・要約同士を人間が比較してデータセットを組み立て
・人間が好む要約を予測するための報酬モデルのトレーニング
・RLを使用して要約モデルを微調整し、高い報酬を取得
インターネットからのテキストでトレーニングされたGPTスタイルのトランスフォーマーモデルから開始し、教師あり学習を介して人間が作成した要約を予測するように微調整することにより、いくつかの教師ありベースラインをトレーニングしました。
主に13億と60億のパラメータを持つモデルを使用します。正当性チェックとして、このトレーニング手順がCNN / DMデータセットで競争力のある結果につながることを確認しました。
次に、人間の品質判断のデータセットを収集しました。
人間は特定の投稿の2つの要約を比較し、より良いと思うものを選びます。このデータを使用して、(投稿、要約)ペアを報酬rにマップする報酬モデルをトレーニングします。
報酬モデルは、報酬を使用して、人間が好む要約を予測するようにトレーニングされています。
最後に、RLを使用して報酬モデルに対してポリシーを最適化します。合計100万エピソードのPPO(Proximal Policy Optimization、OpenAIのデフォルトの強化学習アルゴリズム)を使用します。各エピソードは、1つの記事を要約し、報酬rを受け取るポリシーで構成されます。ポリシーを教師あり初期値の近くに留めるように促すKLペナルティが含まれています。
人間からデータを収集
人間のフィードバックを使用するトレーニングは、データ経由でラベル付け作業者から直接影響を受けます。
私達は以前、人間の好みから言語モデルを微調整するという研究を行いました。その際、ラベル付け作業者は、特に優秀なわけではなく平均的と思われる要約に高い評価を与えることがよくありました。このラベルを使って訓練すると、この評価がモデルの品質に反映されてしまいます。
これを踏まえて、今回のプロジェクトでは、高いデータ品質を確保するために多額の投資を行いました。サードパーティベンダーのサイトを使用して約80名の請負業者を雇用し、評価した要約の数に関係なく、時間給で支払いました。
クラウドソーシングのウェブサイトに頼るのではなく請負業者を雇うことで、ラベル付け作業者と実践的な関係を維持することができました。研修を行い、カスタマイズ可能なラベル付け作業者向けインターフェイスを備えたWebサイトを開発し、共有チャットルームで質問に回答し、ラベル付け作業者と1対1のビデオ通話を行いました。
また、要約を自分達で読む事にかなりの時間を費やした後、要約の品質の定義を明確に伝えるようにし、プロジェクト全体を通して私達とラベル付け作業者の間の合意率を注意深く監視しました。
報酬モデルの最適化
報酬モデルを最適化すると、最終的にサンプルの品質が低下します
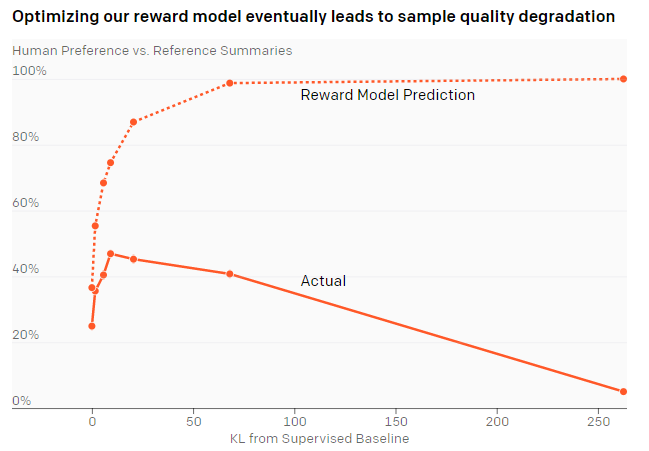
13億の教師ありベースライン(x軸の0)から開始して、RLを使用して、報酬モデルに対してポリシーを最適化します。これにより、ベースラインとは異なる「距離」を持つポリシーが作成されます。(x軸は教師ありベースラインからのカルバック・ライブラー情報量を「距離」として使用して測定)報酬モデルに対して最適化すると、最初は人間による要約が改善されますが、最終的には過剰になり、要約が悪化します。 このグラフは、古いバージョンの報酬モデルを使用しているため、報酬モデルのピークは0.5未満です。
「私は28歳の男性です。体操を始めたいと思っています」タイトルでほぼ全てを言いました。 私は28歳で、非常に運動能力があり(自転車/サーフィン/スノーボード)、常に体操をしたいと思っていました。私は橋やスノーボードでバク転やスピンをするのが好きです。体操は、制御された環境で、好きな動きをするのに最適な方法だと思います。今回の最終的な目標は、それが楽しくなり、実際の生活の中でこれらの動きをより良くすることです。しかし、私には手遅れですか? 私のような28歳の男性は、YouTubeでパルクールをやっている男性を見るだけで満足する必要がありますか? それとも、体操のジェダイのやり方を学ぶことができますか? ところで、私はカリフォルニア州サンノゼに住んでいます。
体操をしたいのですが、28歳です。 私が体操選手になるには遅すぎますか?!
28歳の男が初めて体操を始めたいと思っています。 私がカリフォルニア州サンノゼに住んでいることを考えると、私には遅すぎますか?
28歳の男は頑固に延期し、明らかな興味を持っていたにもかかわらず、物流を理由に体操の趣味を追求し始めますか?個人的にも学問的にも長期的なフィットネスの進歩に悪影響を及ぼしていますか?このばかげたくだらないポリシーを変更したいと思って頂けませんか?
3.人間による評価を使って要約を学ぶ(3/4)まとめ
1)openai.com
Learning to Summarize with Human Feedback
2)arxiv.org
Learning to summarize from human feedback
3)github.com
openai / summarize-from-feedback
4)openaipublic.blob.core.windows.net
models trained in the “Learning to Summarize from Human Feedback” paper.
