
1.Deep-MARC:初めてみる物体をマスクする能力を向上する秘訣(2/2)まとめ
・典型的なmask R-CNNの実装は完全教師有り設定ではパフォーマンスに影響を与えなかった
・部分的教師有り設定ではcropping-to-ground手法がパフォーマンス向上に重要となる
・この違いは初見クラスで評価した場合にのみ明白になり既知クラスには影響を与えない
2.Deep-MARCとは?
以下、ai.googleblog.comより「Revisiting Mask-Head Architectures for Novel Class Instance Segmentation」の意訳です。元記事は2021年9月15日、Vighnesh BirodkarさんとJonathan Huangさんによる投稿です。
アイキャッチ画像のクレジットはスタジオジブリ作品静止画より天空の城ラピュタ
典型的なmask R-CNNの実装は、両方のタイプの切り抜きをマスクヘッドに渡します。ただし、この選択は、完全教師有り(fully supervised)設定ではパフォーマンスに大きな影響を与えないため、従来は重要でない実装の細部と見なされてきました。
対照的に、部分的教師有り(partially supervised)設定では、切り抜き方法が重要な役割を果たします。トレーニング中に検証済み境界ボックス(ground truth bounding box)のみを切り抜いても、完全教師設定では結果が大幅に変わることはありませんが、部分的教師設定では驚くほど劇的なプラスの影響があり、初見クラスに対してパフォーマンスが大幅に向上します。
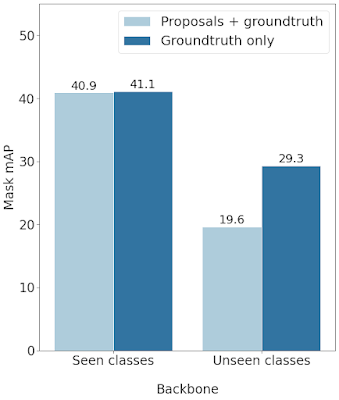
モデルが予測した境界ボックス(proposals)と検証済み境界ボックス(ground truth bounding box)のいずれか、または検証済み境界ボックスのみでトレーニングされた場合の、初見クラスでのMask R-CNNのパフォーマンス比較。検証済み境界ボックスのみを使用してマスクヘッドをトレーニングすると、初見クラスのパフォーマンスが大幅に向上し、mAPが9%以上向上します。ResNet-101-FPNバックボーンでのパフォーマンス結果です。
マスクヘッドを完全に一般化する可能性を解き放つ
さらに驚くべきことに、このアプローチは新しい現象を解き放ちます。
トレーニング中に検証済み境界ボックスを使った切り抜き(cropping-to-ground)が有効になっていると、Mask R-CNNのマスクヘッドは、モデルが初見クラスに一般化する能力において不釣り合いな程の役割を果たします。
例として、次の図では、検証済み境界ボックスを使った切り抜き(cropping-to-ground)を有効にしたモデルを比較しています。ただし、それぞれが異なったマスクヘッドアーキテクチャでパーキングメーター、携帯電話、ピザ(トレーニング中になかった初見クラス)の比較です。

4つの異なるマスクヘッドアーキテクチャによる初見クラスのマスク予測
(左から右へ:ResNet-4、ResNet-12、ResNet-20、Hourglass-20、後半の数字はニューラルネットワークの層の数を示します)
これらのニューラルネットワークは「パーキングメーター」、「ピザ」、「携帯電話」のクラスマスクを見た事がないにもかかわらず、マスクヘッドアーキテクチャは正しくセグメント化できます。左から右に、より良いマスクを予測するより良いマスクヘッドアーキテクチャを示します。さらに、この違いは、初見クラスで評価した場合にのみ明白になります。既知クラスで評価すると、4つのアーキテクチャすべてが同等のパフォーマンスを示します。
特に注目すべきは、マスクヘッドアーキテクチャ間のこれらの違いは、完全教師有り設定ではそれほど明白ではないということです。ちなみに、これは、従来のインスタンスセグメンテーションでは、複雑な構造を追加しても利点がなかったため、浅い(つまり、層の数が少ない)マスクヘッドがほぼ独占的に使われていた理由を説明している可能性があります。
以下では、既知クラス(Seen Classes)と初見クラス(Unseen Classes)に対して3つの異なるマスクヘッドアーキテクチャのmask mAPを比較します。3つのモデルはすべて、既知クラスのセットでは同等に機能しますが、初見クラスに適用すると、深い層を持つHourGlassマスクヘッドが傑出します。
試したアーキテクチャの中でHourGlassマスクヘッドが最適であることがわかったので、50以上の層をもつHourGlassマスクヘッドを使用して最良の結果を得ることができます。
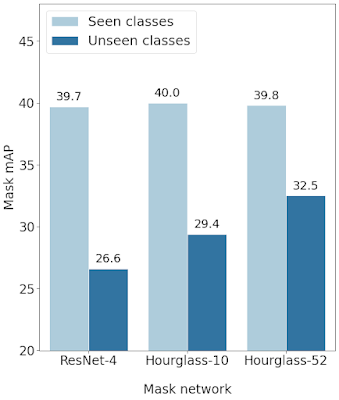
既知クラスと初見クラスでのResNet-4、Hourglass-10、およびHourglass-52マスクヘッドアーキテクチャのパフォーマンス。既知クラスのパフォーマンスはほとんど変化しませんが、初見クラスのパフォーマンスには大きな違いがあります。
最後に、私たちの調査結果は一般的であり、さまざまなバックボーン(ResNet、SpineNet、HourGlassなど)と、アンカーベースおよびアンカーフリーの検出器を含む検出器アーキテクチャ、および検出器がまったくない場合でも当てはまることを示しました。
全てを一緒にする
最良の結果を達成するために、上記の調査結果を組み合わせました。高解像度画像(1280×1280)で、検証済み境界ボックスを使った切り抜き(cropping-to-ground)を有効にしたmask R-CNNモデルと、SpineNetバックボーンを備えたDeep HourGlass52マスクヘッドをトレーニングしました。
このモデルをDeep-MARC(Deep Mask heads Above R-Cnn)と呼びます。Deep-MARCは、オフライントレーニングやその他の手作りの事前設定を使用せずに、以前の最先端モデルを4.5%以上(絶対値で)mask mAP上回っています。
このアプローチの一般的な性質を示すことで、CenterNetベース(Mask R-CNNベースではなく)モデル(Deep-MACと呼ばれる)でも強力な結果が得られます。これも以前の最先端技術を上回っています。
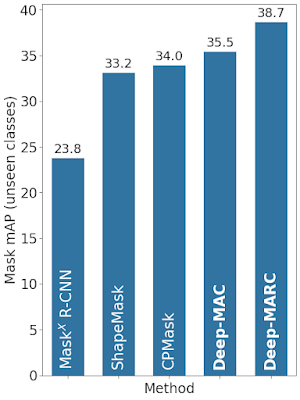
Deep-MACおよびDeep-MARCと、MaskX R-CNN、ShapeMask、CPMaskなどの他の部分的教師ありインスタンスセグメンテーションアプローチとの比較
結論
トレーニングセット内に存在しなかった初見クラスに一般化できるインスタンスセグメンテーションモデルを開発しました。
あらゆる「切り抜いてからセグメント化するモデル(crop-then-segment model)」(mask R-CNNなど)に適用できる2つの重要な要素の役割を強調します。(1)トレーニング中に検証済み境界ボックスを使った切り抜き(cropping-to-ground)(2)強力なマスクヘッドアーキテクチャ。
これらの要素はどちらも、トレーニング中にマスクを使用できるクラスに大きな影響を与えませんが、両方を使用すると、トレーニング中にマスクを使用できない未見クラスのマスクが大幅に改善されます。さらに、これらの成分は、部分的教師設定のCOCOベンチマークで最先端のパフォーマンスを達成するのに十分です。最後に、私たちの調査結果は汎用的であり、パノマティックセグメンテーションやポーズ推定などの関連タスクにも影響を与える可能性があります。
謝辞
共著者のZhichao Lu, Siyang Li, そしてVivek Rathodに感謝します。
この研究の改善に大きな役割を果たしたコメントについて、David Rossと匿名のICCVレビューアに感謝します。
Webbigdataによるおまけ
Colabで本当にサッと動いてしまうので検証してみましたが、簡単そうな場面から難しそうな場面までざっと見てみました。
1)風立ちぬよりゼロ戦

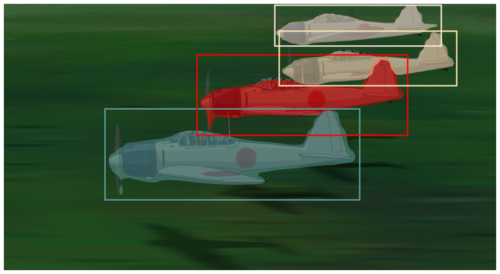
プロペラの部分以外はほぼmask出来てますね、スゴイです。
2)ラピュタよりシータとパズーと鳩

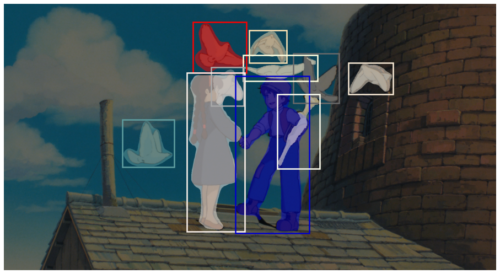
やや腕が被ってますが、トランペット部分がマスク出来ているのが凄い!
3)もののけ姫より出撃のシーン


槍の部分が少し失敗してますが、背後の狼は綺麗にマスク出来てますね。
4)風の谷のナウシカより王蟲の大群

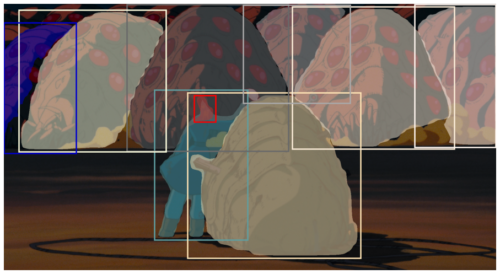
テトをマスク出来ているのが凄いですが、ナウシカの赤毛はさすがに難しかったようです。でも、スゴイここまで出来ちゃうんですね、不思議です。
3.Deep-MARC:初めてみる物体をマスクする能力を向上する秘訣(2/2)関連リンク
1)ai.googleblog.com
Revisiting Mask-Head Architectures for Novel Class Instance Segmentation
2)arxiv.org
The surprising impact of mask-head architecture on novel class segmentation
3)github.com
Novel class segmentation demo with Deep-MAC
4)www.ghibli.jp
スタジオジブリ作品静止画

