
1.対照学習で最良のビューを選択するための原則(2/2)まとめ
・InfoMin仮説を検証のため相互情報量を徐々に減らすと逆U字型の曲線が観察される
・アーキテクチャ等の違いにもかかわらず、直近の対照学習は暗黙的にInfoMin仮説に従っている
・InfoMin仮説に従って新規にビューを合成する教師なしおよび半教師ありの手法を設計した
2.対照学習に関する統一見解
アイキャッチ画像のクレジットはPhoto by Pascal Müller on Unsplash
対照学習に関する統一見解
教師なしでビュー間で共有される相互情報を制御する簡単な方法があるという事実に基づいて、InfoMin仮説を検証するためにいくつかの実験を設計します。
例えば、同じ画像から異なる範囲を選び、選択範囲間の距離を増やすだけで相互情報量を減らすことができます。
ここでは、相互情報量の下限の定量的尺度であるInfoNCE(INCE)を使用して相互情報量を推定します。実際、相互情報量が減少すると、下流タスクの精度が最初に向上し、その後低下し始めるという逆U字型の曲線が観察されます。
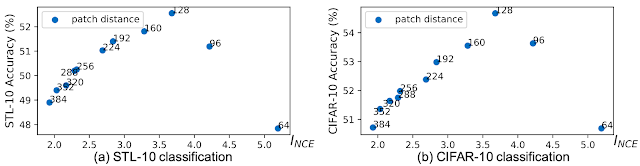
対照学習で学習した特徴表現に線形分類器を適用した下流タスクでSTL-10(左)およびCIFAR-10(右)の分類精度。前の図と同じように、ビューは同じ画像の異なる範囲から選択されます。選択範囲間のユークリッド距離を大きくすると、相互情報量が減少します。分類精度とINCE(つまり選択範囲間の距離)の間に逆U字曲線が観察されます。
更に、私達はいくつかの最先端の対照学習(InstDis、MoCo、CMC、PIRL、SimCLR、およびCPC)は、ビュー選択の観点から統合できることを示します。
アーキテクチャ、目的、及び工学的な詳細の違いにもかかわらず、直近の全ての対照学習は、暗黙的にInfoMin仮説に従う2つのビューを作成します。InfoMin仮説では、ビュー間で共有される情報は、データ水増しの強度によって制御されます。
これを動機として、ImageNet線形読み出しベンチマークで、従来のSimSLRをほぼ4%上回る、新しいデータ水増しセットを提案します。また、教師なしの事前トレーニング済みモデルを物体検出とインスタンスセグメンテーション用に転送すると、ImageNet事前トレーニングよりも常にパフォーマンスが優れていることもわかりました。
ビューを生成することを学ぶ
私達の研究では、InfoMin仮説に従って新規にビューを合成する教師なしおよび半教師ありの手法を設計します。自然な色空間を新しい色空間に変換するフローベースのモデルを学び、そこからチャネルを分割してビューを取得します。
教師なし設定では、ビュージェネレーターは、視点間のInfoNCEバウンドを最小限に抑えるように最適化されています。以下に示すように、InfoNCEの範囲を最小限に抑えつつ逆U字傾向のグラフとなります。
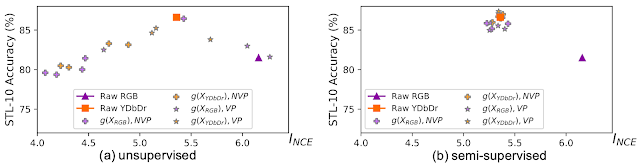
教師なし(左)および半教師あり(右)学習によって学習されたビュージェネレーター
相互情報量を過度に最小化せずにスイートスポットを獲得するために、半教師付き設定を使用して、ビュージェネレーターがラベル情報を保持するようにガイドします。予想どおり、すべての学習済みビューは、入力カラースペースが何であっても、スイートスポットを中心に配置されます。
コードと事前学習済みモデル
自己教師型の対照学習の研究を加速するため、InfoMinのコードと事前トレーニング済みモデルを学術コミュニティと共有できることを嬉しく思います。これらはgithubで見つけることができます。
謝辞
コアチームには、Yonglong Tian, Chen Sun, Ben Poole, Dilip Krishnan, Cordelia Schmid 及び Phillip Isolaが含まれます。洞察に満ちた議論をしてくれたKevin Murphy、原稿へのフィードバックをくれたLucas Beyer、計算をサポートしてくれたGoogle Cloudチームに感謝します。
3.対照学習で最良のビューを選択するための原則(2/2)関連リンク
1)ai.googleblog.com
Understanding View Selection for Contrastive Learning
2)arxiv.org
What makes for good views for contrastive learning
Representation Learning with Contrastive Predictive Coding
3)github.com
PyContrast/pycontrast/


コメント