
1.長文を読みあげる合成音声の品質を評価する(1/2)まとめ
・合成音声の品質評価は従来1文ごとに行われており、文脈の中で評価する統一基準は存在しない
・しかし評価対象の文を長い文章の一部として評価すると従来と来なる評価基準が採用されている
・人間の発声した音声を評価した際も同様な事象が発生しており提示状況に応じて評価が変わる
2.合成音声の品質の評価
以下、ai.googleblog.comより「Assessing the Quality of Long-Form Synthesized Speech」の意訳です。元記事は2019年9月9日、Tom Kenterさんによる投稿です。
運転中にカーナビが読み上げる道案内から、スマートフォンの仮想アシスタント、自宅のスマートスピーカーまで、自動で生成された合成音声は身近な存在です。
合成音声を可能な限り自然なものにするために、多くの研究が行われています。
利用できる学習データが少ないマイナーな言語の音声の生成や、Tacotron 2を使用した人間そっくりの音声の作成など。
しかし、合成音声はどのようにして性能を評価すべきでしょうか?最善の方法は、自然に聞こえるかどうかを聴覚に優れた人に判断して貰う事です。音声合成の分野では、合成音声のサンプルを聞いて、その品質を評価する事が日常的に行われています。
しかし、従来、合成音声の評価は文ごとに行われてきました。しかし、多くの場合、ニュース記事の段落や会話の順番など、一連の文章としての品質を知りたいと思うでしょう。
連続する自然な文を評価する方法は複数あるため、これが興味深いところです。驚くべきことに、これらの異なる評価法の厳密な比較は行われていません。これは、性能が合成音声の品質に依存する製品開発における研究の進展を妨げる可能性があります。
この課題に対処するために、SSW10に掲載予定の論文「Evaluating Long-form Text-to-Speech: Comparing the Ratings of Sentences and Paragraphs」を発表しています。
ある文が複数の文を含む長い文章の一部として評価される場合、評価結果は、それを評価する人々に音声サンプルがどのように提示されたかに影響を受けることがわかりました。
例えば、文を前後の文脈なしで単独で聞かされた場合に人々が与える評価は、何らかの文脈と共に同じ文を聞いた場合に与える評価とは大きく異なります。(文脈を評価する必要がないとしても)。
自動で生成された合成音声の評価
音声信号の品質を判断する手法は、特定のサンプルについて1~5の尺度で複数の評価者に評価を求めるようにするのが一般的です。このテストに使うサンプルは自動的に生成できますが、人間が発声した自然音声を評価することもできます。特定の音声サンプルを評価する全てのレビュアーのスコアを平均して、平均意見スコア(MOS:Mean Opinion Score。1が最も音質が悪く5が最も音質が良いとする評価)を取得します。
訳注:以下、機械が発声した合成音声(synthesized speech)と人間が発声した自然音声(natural speech)の比較が続きます。自然音声と言う表現は日本語ではあまり一般的な使われ方ではないと思いますが、ここでは合成音声との対比で使われています。
従来、MOSの評価は通常、文ごとに収集されていました。つまり、評価者は、意見を形成するために単独で文を聞いていました。この典型的なアプローチの代わりに、音声サンプルを評価者に提示する3つの異なる方法を検討します。
文脈あり版と文脈なし版の両方、そして、それぞれのアプローチが異なる結果をもたらすことを示します。
1つ目は、文章を分離(Sentences in isolation)して表示することで、この分野で一般的に使用されるデフォルトの方法です。
別の方法は、文章の完全な段落(Full paragraphs)を提供することです。この場合、文が属する段落全体が音声に含まれ、アンサンブルとして評価されます。
最後のアプローチは、文脈と刺激のペア(context-stimulus pair)を提供することです。このケースでは、完全な文脈を提供するのではなく、元の段落の直前の文など、一部の文脈のみが提供されます。
興味深いことに、これら3つの異なるアプローチで提示された音声は、人間が発声した自然音声を評価した場合でも異なる結果をもたらします。これを以下の図に示します。MOSスコアは、3つの異なる表示方法を使用して評価された自然な音声サンプルについて表示されます。評価される文は3つの異なる設定で同一ですが、スコアはそれらが提示された状況に応じて平均的に異なります。
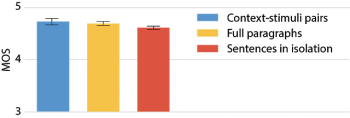
ニュース記事で構成されたデータセットを用いて人間が発声した自然音声のMOS結果。差は小さいように見えますが、すべての条件間で有意です。(両側t検定でα= 0.05)
上記の図を調べると、評価者は録音された人間の発声でさえ最高得点(5)を与えることはめったにないことがわかります。ただし、これは文の評価研究で見られる典型的な結果であり、おそらくタスクや設定に関係なく、人々は極端な評価を避ける傾向があると言う、より一般的な人間の行動パターンに関係しています。
3.長文を読みあげる合成音声の品質を評価する(1/2)関連リンク
1)ai.googleblog.com
Assessing the Quality of Long-Form Synthesized Speech
2)arxiv.org
Evaluating Long-form Text-to-Speech: Comparing the Ratings of Sentences and Paragraphs


コメント