
1.人の流れを統計的に処理した結果から新しい洞察を得る(3/3)まとめ
・階層的な都市ではモビリティが均一的に分布している傾向が高く、公共交通機関が広く利用されている
・また、歩きやすく、汚染物質の排出が少なく、健康に関する様々な指標が優れた都市である
・社会経済的hub間を繋ぐ公共交通機関と自家用車を制限させる事が都市の階層化に貢献するかもしれない
2.データ主導の都市計画とは?
以下、ai.googleblog.comより「New Insights into Human Mobility with Privacy Preserving Aggregation」の意訳です。元記事は2019年11月12日、 Adam SadilekさんとXerxes Dotiwallaさんによる投稿です。
より階層的な都市では、「フロー階層:Φ」の値が上限1に近くなります。
より階層的な都市とは、活動レベルが同等な地域同士を人の流れの観点から比較する事でわかります。階層的な都市は、モビリティが均一的に分布している傾向が高く、公共交通機関が広く利用され、歩きやすく、汚染物質の排出が少なく、健康に関する様々な指標が優れている傾向があります。
私達の例に戻ると、パリのフロー階層はΦ= 0.93(サンプリングされた174都市の中で上位から1/4)であり、ロサンゼルスのフロー階層は0.86(下位から1/4)です。
人口密度やスプロール複合指数(訳注:sprawl composite indices:sprawlは虫食いの意ですが、都市計画用語としては都市が無秩序に拡大してゆく現象を指します)などの都市構造を測定する既存の手法は、フロー階層と相関しますが、さらにフロー階層は行動的および社会経済的要因を含み比較的多くの情報を伝達することがわかります。
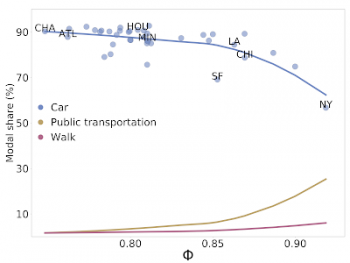
米国の都市を使って、フロー階層Φと都市指標(交通手段)の関係をグラフ化しています。
縦軸:交通手段の割合(自家用車、公共交通機関、徒歩)、横軸:Φ
プロットに表示されるサンプル都市名は、ATL(アトランタ), CHA(シャーロット), CHI(シカゴ), HOU(ヒューストン), LA(ロサンゼルス), MIN(ミネアポリス), NY(ニューヨーク市), SF(サンフランシスコ) より高いフロー階層を持つ都市は、公共交通機関の使用率が著しく高く、車の使用が少なく、歩行性が高いことがわかります。
都市のスプロール化の測定には、土地利用、人口、仕事の密度、および道路の地理的配置などの詳細な情報(時には最大20にも異なる変数)から作成された複合インデックスが必要です。
データを広範から収集しなければいけない事に加えて、このような情報は取得するのにもコストがかかります。例えば、国勢調査や実地踏査では、訪問や面談を行うために大量の人手が必要になり、更に国によって実施方法が異なるため、全世界的規模でスプロール化を定量的に測定する事ができません。一方、フロー情報は、モビリティ情報のみで構築されているため、編集コストが大幅に低く(コンピューターによる処理のみ)、リアルタイムで利用できます。
都市の最適な構造に関する進行中の議論を考えると、フロー階層は、既存の測定とは異なる概念的視点を導入し、都市構成の考え方に新たな光を当てることができます。公共政策の観点から考えると、モビリティ階層の度合いが高い都市ほど、より望ましい都市指標を持つ傾向があることがわかります。
ここで言う階層とは、社会経済的hub間の近接性と直接接続性の尺度であることを考えると、hub-to-spoke構造よりもhub-to-hub構造を大きく促進する方向に誘導し、機会と需要を形成していく事が都市の将来性に繋がります。
訳注:spokeは車輪、hubは車輪の中心部のイメージです
hubの近接性は、適切な土地利用を通じて形成できます。これは、ビジネス、居住地、またはサービスエリアに関する地区計画をデータ主導で行う事で実現できます。
効率的な公共交通機関の存在と自家用車使用率の減少も、もう1つの重要な要素です。もしかしたら、以下のような2つの政策の組み合わせが役立つかもしれません。一つは混雑時割り増し料金制度など、社会経済的なhubに個人所有の乗り物で向かうインセンティブを下げさせる制度です。もう一つはhub同士をターゲットを絞った公共交通機関で直接接続する事です。
次のステップ
この研究はGoogleが掲げるAI for Social Good、つまりGoogleが持つ熟練した技能を人道的および環境的課題の対処に当てる大きなキャンペーンの一部です。今回のモビリティマップは、最初の一歩であり、今後も高いプライバシー基準を確保しながら、疫学、インフラストラクチャ計画、および災害対応に影響を与えていきます。
ここで説明した作業は、プライバシーを維持するために非常に長い時間をかけて行われます。また、federated learningなどの端末内で学習を行う新しい手法にも取り組んでいます。これは、更に一歩進んで、個人データを個人所有のスマートフォンから一切送信せずに、集約したフロー情報を計算できるようにする仕組みです。分散された安全な集約手段、またはランダム化された応答を使用することにより、集約対象の個々のデータに関する知識を集約作業者に持たせなくても、大域的な人の流れを計算できます。この手法は、悪意のある攻撃からChromeブラウザを保護するためにも適用されています。
謝辞
この研究は学際的な共同研究から生れました。IFISC(Institute for Cross-Disciplinary Physics)のAleix BassolasとJosé J. Ramasco。IFISC, CSIC-UIBのBrian Dickinson, Hugo Barbosa-Filho, Gourab Ghoshal, Surendra A. Hazarie。そしてRochester大学Ghoshal研究所コンピュータサイエンス学科のHenry Kautz。Bruno Kessler財団のRiccardo Gallotti。GoogleのXerxes Dotiwalla、Paul Eastham、Bryant Gipson、Onur Kucuktunc、Allison Lieber、Adam Sadilek。
この研究で使用された差分プライバシー(differential-privacy)はオープンソースとして公開されており、GitHubリポジトリから入手できます。
3.人の流れを統計的に処理した結果から新しい洞察を得る(3/3)関連リンク
1)ai.googleblog.com
New Insights into Human Mobility with Privacy Preserving Aggregation
2)www.nature.com
Hierarchical organization of urban mobility and its connection with city livability
3)github.com
google/differential-privacy

コメント