
1.MeRL:強化学習でまばらで仕様が曖昧な報酬に対応(2/3)まとめ
・偶然成功した行動は強化学習エージェントが作業を一般化する際に有害な影響を与える
・MeRLでは成功した行動の特徴に基づいて偶然の成功と意図的な成功を区別した補助的な報酬を使う
・MeRLは補助的な報酬を自動的に学習し疎な報酬より洗練されたフィードバックを与える事が出来る
2.MeRLとは?
以下、ai.googleblog.comより「Learning to Generalize from Sparse and Underspecified Rewards」の意訳です。元記事は2019年2月22日、Rishabh AgarwalとMohammad Norouziさんによる投稿です。
MeRLは成功した行動のメモリバッファと結合されています。メモリバッファはまばらな報酬から学ぶために新しい探査戦略を使って集められます。
私たちのアプローチの有効性は、意味解析(Semantic parsing)で実証されています。例えば、自然言語から論理形式へ変換する事、具体的には質問文から解を導くSQL文を作成する事などです。私達の論文では、弱い教師付き問題設定を調査しました。ここでの目的は、質問と回答のペアから論理的なプログラムを自動的に発見することです。プログラムに対する教師は一切必要ありません。
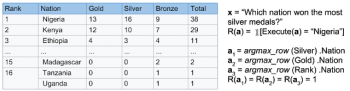
例えば、「どの国が最も銀メダルを獲得しましたか?」という質問と、それに関連するウィキペディアの表が与えられます。
エージェントは、正しい答えをもたらすSQLのようなプログラム(すなわち、「ナイジェリア」)を生成する必要があります。
今回提案されたアプローチはWikiTableQuestionsとWikiSQLベンチマークで最先端の結果を達成し、従来の最高スコアをそれぞれ1.2%と2.4%改善します。MeRLは、教師役なしで補助的な報酬機能を自動的に学習し、それをより広く適用可能にするので、以前の報酬学習アプローチとは区別されます。以下の図は、このMeRLアプローチの概要を示しています。
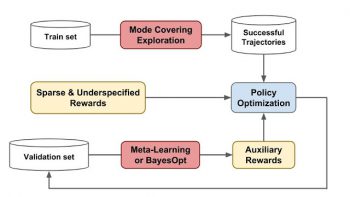
提案されたアプローチの概要:我々は、(1)探索をカバーするモードを使用して、メモリバッファに成功した一連の行動を集めます。(2)メタラーニング、またはベイズ最適化を用いて補助的な報酬を学習します。補助的な報酬はポリシーの最適化に対してより洗練されたフィードバックを提供します。
Meta Reward Learning (MeRL)
MeRLの根底にある重要な洞察は、偶然成功した行動はエージェントが作業を一般化する際に有害であるということです。
例えば、エージェントは上記の迷路問題で特定の事例を解決する事ができるかもしれません。ただし、トレーニング中に仕様が不明確な報酬により誤った行動を学んだ場合、盲目状態で指示が与えられた時に失敗する可能性があります。
この問題を軽減するために、MeRLはより洗練された補助的な報酬機能を最適化します。これは、行動軌跡の特徴に基づいて偶然の成功と意図的な成功を区別することができます。補助的な報酬は、メタラーニングによるホールドアウト検証セットでトレーニング済みエージェントのパフォーマンスを最大化することによって最適化されます。
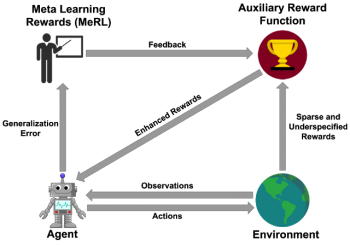
MeRLの概略図:強化学習エージェントは補助報酬モデルから得られた報酬信号を介してトレーニングされ、補助報酬はエージェントの一般化誤差を使用してトレーニングされます。
(MeRL:強化学習でまばらで仕様が曖昧な報酬に対応(1/3)からの続きです)
(MeRL:強化学習でまばらで仕様が曖昧な報酬に対応(3/3)に続きます)
3.MeRL:強化学習でまばらで仕様が曖昧な報酬に対応(2/3)関連リンク
1)ai.googleblog.com
Learning to Generalize from Sparse and Underspecified Rewards
2)arxiv.org
A Survey of Inverse Reinforcement Learning: Challenges, Methods and Progress

コメント