
1.MeRL:強化学習でまばらで仕様が曖昧な報酬に対応(3/3)まとめ
・報酬が疎になる作業を学習させるためにカルバック・ライブラー情報量(KL)を利用している
・カルバック・ライブラー情報量は、2つの異なる確率分布がどの程度異なるかを示す尺度
・全ての最頻値を網羅しようと試みるKLと特定の最頻値を探し出すKLを活用している
2.報酬が滅多に発生しない作業を学習させるためには?
以下、ai.googleblog.comより「Learning to Generalize from Sparse and Underspecified Rewards」の意訳です。元記事は2019年2月22日、Rishabh AgarwalとMohammad Norouziさんによる投稿です。要は、迷路探索(個々の行動がゴールに近づいたか否か判断しにくい)のような頻繁に報酬を発生させる事ができない作業(報酬が疎な作業)では、過去の成功事例(メタラーニングまたはベイズ最適化で算出)と似ているか否かをカルバック・ライブラー情報量を元に計算して補助的な報酬として使う、と言う事を言っているのだと思います。
疎な報酬から学ぶ
疎な報酬から学ぶためには、一連の成功した行動を見つける事が重要です。本稿では、2種のカルバック・ライブラー情報量(KL)を利用してこの課題に対処します。KLは、2つの異なる確率分布がどの程度異なるかを示す尺度です。
以下の例では、カルバック・ライブラー情報量を使用して、バイモーダル(日本語だと二峰性、下図の紫色の分布。つまり山型が2つある分布)と学習ガウス分布(緑色の分布)の差を最小化しています。これはそれぞれエージェントの最適化ポリシーと私達の学習ポリシーの分布を表現しています。
2種のKLのうちの1種は両方の最頻値(modes)を網羅しようと試みる分布を学習します。その一方で、もう1種のKLは特定の最頻値を探します。(すなわち、それは一方の最頻値を他方の最頻値よりも優先します)。
私達は、複数の最頻値の中心に集中するKLの傾向を利用した最頻値カバーKLで多様な成功行動セットを集め、軌跡間でKLの暗黙の好みを求めるシーキングKLを堅牢な方針を学ぶために利用します。
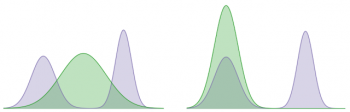
左:最頻値カバーKL。右:最頻値探索KL。
結論
最適な行動と次善の行動を区別する報酬関数を設計することは、実世界のアプリケーションに強化学習を適用するために重要です。本研究は、人間の教師なしに報酬関数をモデル化する方向に小さな一歩を踏み出します。今後の作業では、密な報酬関数を自動的に学習するという観点から、強化学習の貢献度分配問題に取り組みたいと思います。
謝辞
この研究はChen LiangとDale Schuurmansと共同で行われました。 この論文のレビューしてくださったChelsea FinnとKelvin Guuに感謝します。
(MeRL:強化学習でまばらで仕様が曖昧な報酬に対応(2/3)からの続きです)
3.MeRL:強化学習でまばらで仕様が曖昧な報酬に対応(3/3)関連リンク
1)ai.googleblog.com
Learning to Generalize from Sparse and Underspecified Rewards

コメント