
1.PaLM-E:ロボットは邪魔をされても引き出しからポテチを取り出すくらいはできるようになっている(1/2)まとめ
・ロボットモデルの規模拡大は一定の成功を収めているが、テキストや画像に匹敵する規模のデータセットがないので遅れをとっている
・PaLM-Eは様々な視覚・言語領域の知識をロボット工学システムに転移させた新しい具現型言語モデル且つ汎用ロボティクスモデル
・PaLM-Eは言語モデル(PaLM)と視覚モデル(Vision Transformer)の両方を併せ持ち、テキストと他の入力情報を混ぜて学習した
2.PaLM-Eとは?
以下、ai.googleblog.comより「PaLM-E: An embodied multimodal language model」の意訳です。元記事は2023年3月10日、Danny DriessさんとPete Florenceさんによる投稿です。
chatGPTで日本でも有名になったOpenAIは2021年6月頃に、ロボット部門を解散した事が報道されており、その際は、利用可能なデータが言語や視覚領域ほど多くない事を理由の1つに上げています。
Googleも本稿内でロボット領域はデータ不足が原因で他の領域に遅れをとっている事を言及しています。そして、Googleも今年2月にロボットの研究開発に取り組んできたEveryday Robotsを閉鎖する事を発表しているのですが、その後も引き続き、本稿のようにGoogle AIにロボットネタは投稿されているので、ロボットに関する研究を全て止めたわけではありません。
直近の大規模言語モデルで流行している「AIを使って他のツール(他のAIを含む)を操作する」アプローチを取れば、ロボットに命令を出す事は可能と思います。しかし、5感(視覚、聴覚、触覚、味覚、嗅覚)のうち、視覚と言語のみで現実世界に適応するのはどこかのタイミングで限界を迎えるでしょうから、本稿内で紹介されている「マルチモーダル文(multimodal sentences)」の考え方が将来的に主流になっていくのではないかと思います。
アイキャッチ画像はPaLM-EのイメージをchatGPT先生に伝えて作って貰ったプロンプトを私が修正してカスタムStable Diffusion先生に作って貰ったイラスト
近年、機械学習(ML:Machine Learning)領域で多大な進歩が見られます。
様々な言語でジョークを説明可能なモデル、視覚を使って質問に答えるモデル、テキスト記述に基づいて画像を生成するモデルなどがあります。
このような革新は、大規模なデータセットの入手が可能になったことと、これらのデータでモデルの学習を可能にする幾つかの、進歩によって可能になりました。ロボットモデルの規模拡大は一定の成功を収めていますが、大規模なテキスト資料や画像データセットに匹敵する規模のデータセットがないため、他の領域に遅れをとっています。
本日は、様々な視覚・言語領域の知識をロボット工学システムに移植することで、これらの問題を克服した新しい汎用ロボティクスモデル、PaLM-Eを紹介します。
PaLMは、強力な大規模言語モデルです。私達はPaLMをロボットエージェントからのセンサーデータで補完することによって「具現化(Embodied)」(PaLM-Eの「E」)することから開始しました。これが、大規模な言語モデルをロボット工学に導入する従来の取り組みと大きく異なる点です。PaLM-Eでは、テキスト入力だけに頼るのではなく、ロボットのセンサーデータを直接取り込みながら言語モデルを学習させています。その結果、非常に効果的なロボット学習が可能になっただけでなく、言語だけを使って学習した際の優れたタスク機能を維持しながら、最先端の汎用視覚言語モデルを実現しています。
PaLM-Eは具現型言語モデルであり、視覚と言語に関する総合的な知識を持つモデルです。
その一方、PaLM-Eは主にロボット工学のモデルとして開発され、複数の種類のロボットと複数種類の入力情報(画像、ロボットの状態、ニューラルネットワークによる風景の特徴表現)に対して様々なタスクを解決しています。同時に、PaLM-E は汎用的に使用可能な視覚・言語モデルでもあります。画像の描写、物体の検出、風景の分類などの視覚タスクが可能で、詩の引用、数学の方程式の解答、コードの生成などの言語タスクも得意としています。
PaLM-Eは、最新の大規模言語モデルPaLMと、最先端の視覚モデルViT-22Bを組み合わせています。PaLM-540Bをベースに構築されたこのアプローチの最大のインスタンスはPaLM-E-562Bと呼ばれ、タスク固有の微調整を行わず、PaLM-540Bと本質的に同じ汎用的言語性能を保持しながら、視覚言語OK-VQAベンチマークで最大のスコアを達成しました。
PaLM-Eはどのように動作するのか?
技術的には、PaLM-E は、事前学習した言語モデルに観測データを注入することで動作します。これは、自然言語の単語を言語モデルで処理するのと同じような手順で、センサーデータ、例えば画像を特徴表現に変換することで実現します。
言語モデルは、テキストを数学的に表現するメカニズムに依存しています。これにより、テキストをニューラルネットワークが処理できるようになります。
まずテキストを単語(または単語の一部分)を表すいわゆるトークン(token)に分割し、それぞれのトークンに高次元の数値ベクトルであるトークン埋め込み(token embedding)を関連付けることで実現されます。次に、言語モデルは、得られたベクトル列に対して数学的演算(例えば、行列の乗算)を繰り返し適用して学習し、次に来る最も可能性の高い単語トークンを予測できるようになります。新たに予測された単語を入力として再び与える事で、言語モデルはより長い文章をテキストを繰り返し生成することができるようになります。
PaLM-Eの入力は、テキストと他の入力情報(画像、ロボットの状態、風景のembeddingsなど)を任意の順序で並べたもので、私達は「マルチモーダル文(multimodal sentences)」と呼んでいます。例えば、「<img_1>と<img_2>の間に何が起こったのか?」というような入力があり、<img_1>と<img_2>は二つの画像です。出力は、PaLM-Eが自動回帰的(auto-regressively)に生成するテキストで、質問に対する答えや、テキスト形式の一連の判断などがあります。
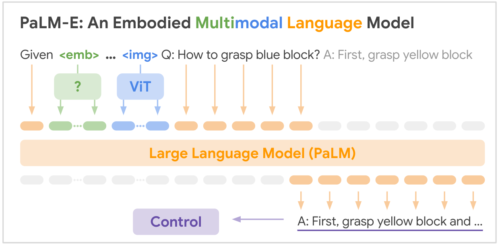
PaLM-Eがどのように異なる種類の情報(状態や画像)を取り込み、マルチモーダル言語モデリングによってタスクに対処するかを示すモデルの概要図
PaLM-Eの発想は、様々な入力を自然語トークンembeddingsと同じ空間に変換するエンコーダを訓練することです。これらの連続的な入力は、(必ずしも離散的な集合を形成するわけではありませんが)「単語」に似たものにマッピングされます。単語embeddingsと画像embeddingsは同じ次元を持つので、言語モデルへの投入が可能です。
PaLM-Eは、言語モデル(PaLM)と視覚モデル(Vision Transformer、通称ViT)の両方を事前に学習させた状態で初期化します。モデルのすべてのパラメータは、学習中に更新することができます。
3.PaLM-E:ロボットは邪魔をされても引き出しからポテチを取り出すくらいはできるようになっている(1/2)関連リンク
1)ai.googleblog.com
PaLM-E: An embodied multimodal language model
2)palm-e.github.io
PaLM-E: An Embodied Multimodal Language Model

