1.RT-1:現実世界の大規模データを取り扱い可能なロボット操作用Transformer(1/2)まとめ
・機械学習は大規模データセットとそれを活用可能なモデルによって進歩している
・ロボット分野は大規模データセットもそれを活用できるモデルも存在しない
・大規模データセットとロボット操作特化型のRobotics Transformer 1を新規公開
2.RT-1とは?
以下、ai.googleblog.comより「RT-1: Robotics Transformer for Real-World Control at Scale」の意訳です。元記事は2022年12月13日、Keerthana GopalakrishnanさんとKanishka Raoさんによる投稿です。
アイキャッチ画像はstable diffusion 2.1のDreamBooth拡張をDALL E2のアウトペインティングで更にサイズ拡張した画像で、映画トランスフォーマーのポスターっぽくしてヒロイン役のナウシカを真ん中に配置ポスター。stable diffusion 2.1で描いた部分の出来が良すぎてDALL E2で描いた背景から浮いてしまってますね。
コンピュータビジョンや自然言語処理など、機械学習(ML:Machine Learning)研究の複数のサブフィールドにおける最近の大きな進歩は、大規模で多様なデータセットを活用する共通のアプローチと、すべてのデータを効率的に吸収できる表現力の高いモデルによって実現されています。このアプローチをロボット分野に適用する試みは様々行われていますが、ロボット分野は他のサブフィールドと同程度の高い能力を持つモデルを活用するには至っていません。
この課題にはいくつかの要因があります。まず、大規模かつ多様なロボットデータがないため、モデルが幅広いロボット体験を吸収することに限界があります。データセットを収集するためには、エンジニアリング作業が重要になる自律的な操作や、人間の遠隔操作によって収集されたデモが必要なため、ロボット工学にとってデータ収集は特に高価で困難なものとなっています。第二の要因は、このようなデータセットから学習し、効果的に汎化できる、表現力豊かで規模拡大可能、かつリアルタイム推論に十分な速度のモデルがないことです。
これらの課題を解決するために、私達はRobotics Transformer 1(RT-1)を提案します。
RT-1は、ロボットの入力と出力行動(カメラ画像、タスク指示、モータ命令など)をトークン化し、実行時に効率的な推論を可能にするマルチタスクモデルで、リアルタイム制御が実現可能です。
このモデルは、Everyday Robots(EDR)の13台のロボットを用いて17ヶ月間に収集された、700以上のタスクをカバーする13万エピソードからなる大規模な実世界のロボティクスデータセットで訓練されています。
私達は、RT-1が先行技術と比較して、新しいタスク、環境、オブジェクトに対するゼロショット汎化能力を大幅に改善できることを実証します。さらに、トークン化、行動表現、データセット構成の効果を分析し、モデルとトレーニングセットにおける多くの設計上の選択を慎重に評価し、精査しています。
最後に、RT-1のコードをオープンソース化し、ロボット学習の規模拡大に関する今後の研究に貴重なリソースを提供することを期待しています。
RT-1は、複数のタスク、オブジェクト、環境を持つロボットの軌跡など、大量のデータを吸収し、より良いパフォーマンスと汎化を実現します。
ロボティクス・トランスフォーマー(RT-1)
RT-1は、ロボットのカメラから提供される画像の短い履歴と、自然言語で表現されたタスクの記述を入力として受け取り、トークン化されたアクションを直接出力するtransformerアーキテクチャで構築されています。
RT-1のアーキテクチャは、因果関係マスキングを施した標準的なカテゴリ クロスエントロピー目的に対して訓練された、現代のデコーダのみのシーケンスモデルのアーキテクチャに類似しています。RT-1の主な機能は、以下に示す、画像トークン化、行動トークン化、トークン圧縮です。
・画像トークン化
ImageNetで事前に学習したEfficientNet-B3モデルに画像を与え、得られた9×9×512の空間特徴マップを81個のトークンに平坦化します。イメージトークナイザは自然言語によるタスク指示を条件としており、タスクに関連する画像特徴を早期に抽出するように初期化されたFiLMレイヤーを使用しています。
・行動トークン化
ロボットの行動次元は、腕の動き(x, y, z, roll, pitch, yaw, gripper opening)のための7変数、土台の動き(x, y, yaw)のための3変数、そして3つのモード(腕を制御、ベースを制御、エピソードを終了)の間を切り換えるための追加の離散変数です。各行動次元は256ビンに離散化されます。
・トークン圧縮
このモデルは、要素別AttentionモジュールTokenLearnerによる学習への影響に基づいて、圧縮可能な画像トークンの柔軟な組み合わせを適応的に選択し、2.4倍以上の推論速度の向上を実現しました。
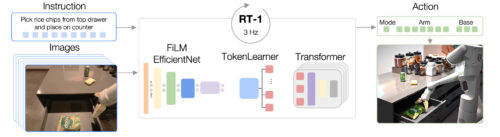
RT-1のアーキテクチャ
テキストによる指示と画像のセットを入力とし、事前に学習されたFiLM EfficientNetモデルによってトークンとしてエンコードし、TokenLearnerによってトークンを圧縮するモデルです。そして、これらをTransformerに送り、アクショントークンを出力します。
新しいタスクに汎化でき、気を散らす様々な物体(distractors)や背景に対して堅牢なシステムを構築するために、私達は大規模で多様なロボットの軌跡のデータセットを収集しました。
7自由度のアーム、2本指のグリッパー、移動ベースを備えた13台のEDRロボットマニピュレータを用い、17ヶ月間にわたって13万エピソードを収集しました。
遠隔操作による人間による実演を用い、各エピソードにはロボットが実行した命令をテキストによる説明文で注釈づけしました。
このデータセットで表現される高レベルのスキルには、品物を選ぶ・置く、引き出しを開ける・閉める、引き出しにアイテムを入れる・出す、細長いアイテムを真上に置く、物体を倒す、ナプキンを引く、瓶を開けるなどが含まれます。このデータセットには、700以上のタスクに対応する13万以上のエピソードが含まれており、様々なオブジェクトを使用しています。
実験と結果
RT-1の汎化能力をより理解するために、3つの比較対象手法に対する性能を研究しました。Gato、BC-Z、BC-Z XL(RT-1と同じパラメータ数のBC-Z)の3つの先行手法に対して、4つのカテゴリで性能を調査しました。
・見たことのあるタスクに関する性能:学習中に見た事のあるタスクの性能
・見たことのないタスクに関する性能:スキルや物体は学習データセット内には別々に存在していましたが、新たな形式で組み合わされた見たことのないタスクに関するパフォーマンス
・堅牢性(気を散らすものと背景):気を散らすもの(最大9個の気を散らす物と視線を遮る物)および背景の変化(新しいキッチン、照明、背景)に対応するパフォーマンス
・長期目線で考える事が必要になるシナリオ: 実際のキッチンでSayCan型の自然言語による指示の実行
RT-1は、4つのカテゴリすべてにおいて、比較対象手法よりも大きな差をつけており、優れた汎化性と頑健性を示しています。
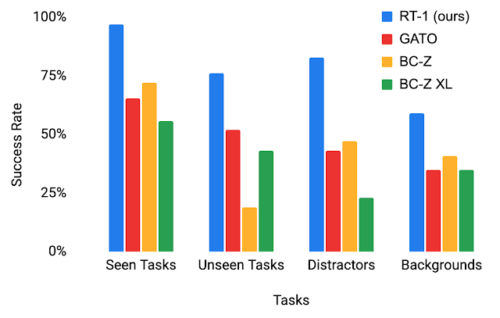
評価シナリオにおけるRT-1と従来手法の性能比較
3.RT-1:現実世界の大規模データを取り扱い可能なロボット操作用Transformer(1/2)関連リンク
1)ai.googleblog.com
RT-1: Robotics Transformer for Real-World Control at Scale
2)robotics-transformer.github.io
RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE
3)github.com
google-research / robotics_transformer
