
1.ICDAR 2023で行われる階層的テキスト検出・認識に関するコンペ(1/2)まとめ
・文書画像よりも複雑な背景を持つ自然画像にOCRを適応させる研究は場面内テキスト検出・認識や場面内テキスト位置決定と呼ぶ
・場面内テキスト検出・認識と関係が深いレイアウト解析は独立した技術として開発されており相乗効果はほとんど研究されていない
・画像中のテキストに対して、行や段落に分類された単語を使って階層的な構造を注釈付けできるシステムを構築するコンペを開催
2.HierText Challengeとは?
以下、ai.googleblog.comより「Announcing the ICDAR 2023 Competition on Hierarchical Text Detection and Recognition」の意訳です。元記事は2023年3月7日、Shangbang Longさんによる投稿です。
まず最初にすいません、ポスターやチラシなど、文字の大きさや色や形が一定ではない画像から文字を読み取るコンペだそうなのですが、締め切りは4/1なので既に過ぎています。
こういった限定された場面で必要になるタスクも最終的に大規模モデルがこなせるようになっていくのか、それとも8割くらいまでは、大規模モデルが追いつけるけれども、それ以上精度を上げようとしたら特化型モデルがやっぱり必要なのかをなどをちょっと考えてみましたが、直近の大規模言語モデルは自分が解決できなかったら他のモデル or 人間を使ってそのタスクをこなすくらいの事はやりそうですよね。
アイキャッチ画像はchatGPT先生に相談して作成したプロンプトに手を加えてカスタムStable Diffusion先生に作って貰ったイラスト。光学式文字認識の概念から、近未来的なブレードランナー or 攻殻機動隊的なテイストになったのだと思います。
ここ数十年、光学式文字認識(OCR:Optical Character Recognition)術は急速に発展し、深層学習研究の初期のブレークスルーに使用される学術的なベンチマークタスクから、消費者向け機器やサードパーティ開発者が日常的に使用できる具体的な製品へと発展しています。
これらのOCR製品は、紙や画像ベースのソース(書籍、雑誌、新聞、フォーム、道路標識、レストランのメニューなど)に保存されている貴重な情報をデジタル化して民主化し、インデックス化、検索、翻訳、さらに最先端の自然言語処理技術によって処理できるようにします。
文書画像よりも複雑な背景を持つ自然画像にOCRを適応させることで、この急速な発展を牽引してきたのが、場面内テキスト検出・認識(scene text detection and recognition)の研究です。(または場面内テキスト位置決定(scene text spotting)と呼ばれます)
しかし、これらの研究は、画像中の個々の単語の検出と認識に焦点を当て、これらの単語がどのように文や記事を構成しているかを理解することはありません。
レイアウト解析(Layout analysis)は、文書画像からその構造、すなわちタイトル、段落、見出し、図、表、キャプションを抽出する、もう一つの関連する研究分野です。これらのレイアウト解析の取り組みは、OCRと並行して行われ、一般的に文書画像でのみ評価される独立した技術として開発されてきました。そのため、OCRとレイアウト解析の間の相乗効果は、ほとんど未解明なままです。
私達は、OCRとレイアウト解析は、機械学習による画像中のテキストの解釈を可能にする相互補完的なタスクであり、組み合わせることで、両タスクの精度と効率を向上させることができると考えています。
このような背景から、第17回International Conference on Document Analysis and Recognition(ICDAR 2023)の一部として開催される「階層的テキスト検出・認識に関する競技会」(The HierText Challenge)を発表します。
本競技会は、Robust Reading Competitionのウェブサイト上で開催され、OCRとレイアウト解析を統合する最初の大きな取り組みとなります。本競技会では、画像中のテキストに対して、行や段落に分類された単語を使って階層的な注釈を生成できるシステムを構築する研究者を世界中から募集します。
本競技会が、OCRとレイアウト解析にまたがる研究努力を統合し、下流の情報処理タスクのための新しいシグナルを生み出すことを目標に、画像ベースのテキスト理解に重要かつ長期的な影響を与えることを期待しています。
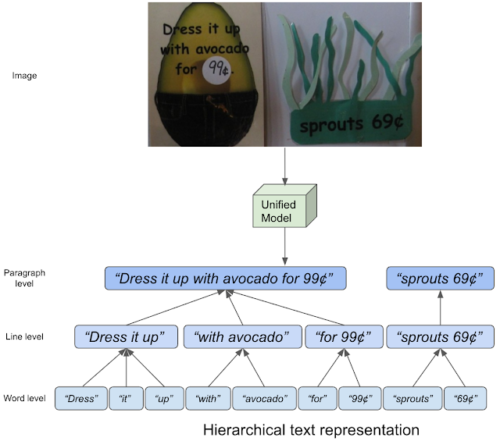
テキストを階層的に表現する概念
階層的なテキストデータセットの構築
本大会では、CVPR 2022で発表された論文「Towards End-to-End Unified Scene Text Detection and Layout Analysis」とともに発表したHierTextデータセットを使用します。
これは、テキストの階層的な注釈を提供する最初の実画像データセットで、単語、行、段落レベルの注釈を含んでいます。
ここで、「単語(words)」は「空白(spaces)で中断されていない文字の並び」と定義されます。
「行(Lines)」は「論理的に一方向に連続している、空間的に近接して配置された空白で区切られた単語のクラスタ」として解釈されます。
最後に「段落(paragraphs)」は、「同じ意味上のトピックを共有し、位置的に一貫性のある行から構成」されます。
3.ICDAR 2023で行われる階層的テキスト検出・認識に関するコンペ(1/2)関連リンク
1)ai.googleblog.com
Announcing the ICDAR 2023 Competition on Hierarchical Text Detection and Recognition
2)rrc.cvc.uab.es
Overview – Hierarchical Text: Challenge on Unified OCR and Layout Analysis

