
1.FollowYourPose:画像生成モデルとポーズ動画と文章からキャラクターの動画を生成まとめ
・FollowYourPoseは棒人間形式にした動画とプロンプトを与えるとプロンプトと動画に基づいたキャラクター動画を簡単に作れる新モデル
・SpaceやColab、学習済モデルも公開されているので気軽に試す事ができるが、現在公開されているのは素のStable Diffusion 1.4ベース
・自分用のカスタムモデルで動かすためには、微調整が必要で、相当な手間とコストがかかりそうなるので本格的に使うのはまだ難しそう
2.FollowYourPoseとは?
FollowYourPoseを試してみた結論
現在公開されているのは素のStable Diffusion 1.4ベースです。自分用のカスタムモデルで動かすためには、微調整が必要で、相当な手間とコストがかかりそうなるので本格的に使うのはまだ難しそうです。
FollowYourPose概要
・「動画からポーズを抽出して棒人間形式にした.movファイル」と「プロンプト」を与えると、画像生成モデルがプロンプトに基づいて作成したキャラクターが動画から抽出したポーズに従って動く動画を簡単に作れます。
・公開されている学習済モデルは素のStableDiffusin1.4(DiffUsers形式でdiffusers_versionが0.2.2なのでかなり古い)がベースです。StableDiffusin1.5ベースのモデルであれば比較的簡単に動かせそうではありますが、単純に差し替えするだけでは動かせず、おそらくそのモデル専用の微調整が必要そうです。トレーニング用スクリプトも公開されていますがA100が8台必要との事、GCP換算ではおよそ\4,400/h以上ですが何時間かかるかは試してみないとわかりません。
・本プロジェクトではビデオからポーズを抽出する機能はまだ提供されていないです。ただしmmpose等の他プロジェクトのモデルを使って動画から自分自身で作成したポーズ動画を使う事は可能です。
・無料版Colabで動く事は確認済です。(セットアップ中に一部でエラーメッセージが出ますが動きます)ただし、現時点では順番にボタンを押すだけでは作れません。設定ファイル(./config/pose_sample.yaml )に修正を行わないとメモリ不足でエラーになります。気軽に試したい場合はSpaceの方が良いかもしれません。
validation_data:
prompts:
- "Iron man on the beach"
- "Stormtrooper on the sea"
- "Astronaut on the beach"
video_length: 32 ← ここを8にする
・サンプルColabで作成した動画はそのままでは全部同じ振り付けの動画(.gif)になりますが、サンプル動画は2つ提供されているので最終的な動画作成時のコマンドの –skeleton_path の部分をもう一つのファイル(“./pose_example/vis_ikun_pose1.MOV”)を指定するなり、mmposeを使って動画から自分で作成したポーズと置き換える事はできます。
!TORCH_DISTRIBUTED_DEBUG=DETAIL accelerate launch txt2video.py --config="configs/pose_sample.yaml" --skeleton_path="./pose_example/vis_ikun_pose2.mov"
・無料版Colabでは1動画作成に4分くらいかかりかなり重いので、大量に動画を作るのは難しいです。プロンプトは前述の./config/pose_sample.yaml の中に書いてあるので適宜変更はできます。
・最終的なgifファイルは/content/FollowYourPose/checkpoints/inference/配下に出来るので自分でダウンロードする必要があります。
FollowYourPoseで作ってみた動画のサンプル
素のStable Diffusion 1.4ベースと聞いた時点で、一部の例外、そう、例のあの人を除けばそんなに綺麗なキャラクター動画を作れないであろうという確信がありましたが、やはり難しかったです。
プロジェクト内でサンプルとして公開されている動画は相当沢山のトライアンドエラーを繰り返しているか、Stable Diffusion 1.4ベースではないモデルが既に存在しているのだろうと思います。
まず、サンプルプロンプト通りに作ったStable Diffusion内で強力な存在感を誇る御三家概念
スターウォーズのストームトルーパー

アイロンマン

宇宙飛行士

さて、以下はインターネット上の人気者の動画化に挑戦してみたものです。
火星のイーロン・マスク

カエルのぺぺ

サウスパークのランディ・マーシュ

スポンジボブ

プールサイドのニコラス・ケイジ
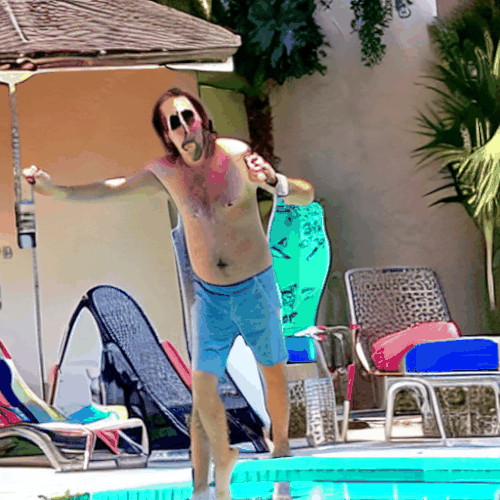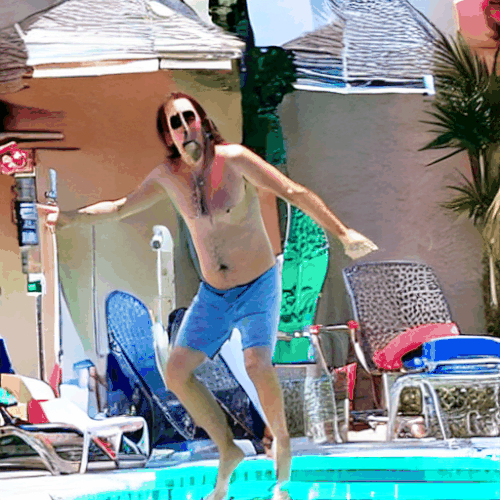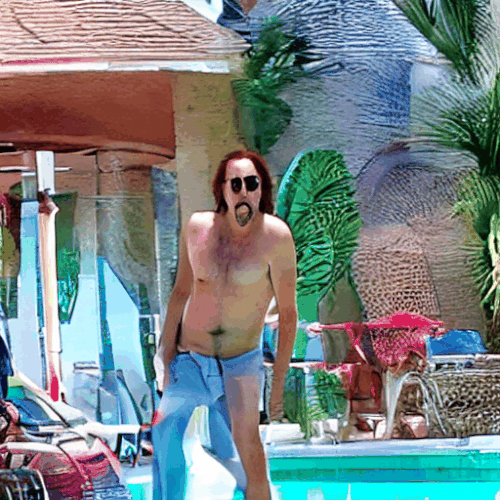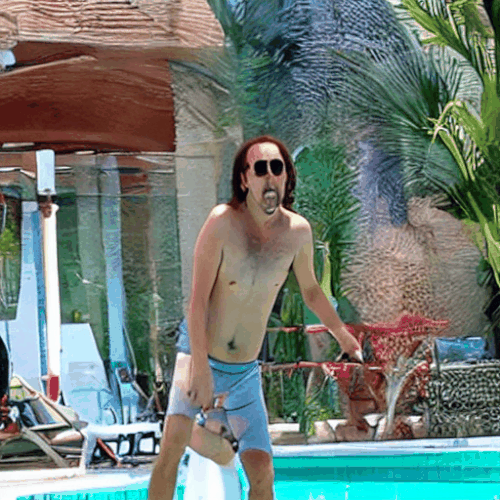
火星のニコラス・ケイジ

最後に全部ニコラス・ケイジに持っていかれました。
しかし、崩れず、場面に合わせて着替える事さえやってのける、やっぱり今回のような強力な概念が必要とされる場面では非常に頼りになります。
3.FollowYourPose:画像生成モデルとポーズ動画と文章からキャラクターの動画を生成まとめ
1)arxiv.org
Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos
2)github.com
mayuelala / FollowYourPose
open-mmlab / mmpose
3)huggingface.co
Follow Your Pose (Spaceで気軽に試してみたい方はこちら)
4)colab.research.google.com
quick_demo.ipynb (Colabに慣れている方はこちら)

