
1.LLaMA、chatGPT値下げ、FLAN-UL2:直近の巨大ゴリラ同士の殴り合いまとめ
・一週間前にMetaが最大650億のパラーメーターを持つLLaMAを非商用ライセンスで公開
・三日前にOpenAIがchatGPTのAPI経由での利用料金を従来比1/10に値下げする事を発表
・昨日、Googleが最大200億のパラーメーターを持つFLAN-UL2を商用にも使いやすいApacheライセンスで公開
2.LLaMAとは?
以下、ai.facebook.comより「Introducing LLaMA: A foundational, 65-billion-parameter large language model」の意訳です。元記事の投稿は2023年2月24日です。
人工知能分野における2大巨頭はGoogleとMeta(FaceBook)と思っています。TensorFlow(Google)とPytorch(Meta)を筆頭に、リサーチ/オープンソースコミュニティへの貢献という観点から見ると両社は別格と感じていて、ビジネスのやり方などに反感を感じる事はあるかもしれませんが、それを差し引いてもやっぱり凄いなと思うのです。
しかし、直近はchatGPTで初めて本格的なAIに触れた人達が、OpenAI/Microsoft陣営を手放しに賞賛していて「Google/Metaは何故AIで遅れを取ったのか?」的な記事や発言を見かける事が多いです。
個人的にはchatGPTが優れている点は「人工知能としての革新性」ではなくて「使いやすいように敷居を下げたこと」であって、Pythonどころかハードウェアやソフトウェアに関する知識が一切なくても自由に使えるインタフェース/API設計で使いやすくなったため、様々な領域から新しいもの好きな人達が集まってきて、自分の業務/得意分野にAIを組み込めないかを試行錯誤しているのが現在の状況と認識しています。
そのため、人工知能に以前から携わっていた人達とはおそらく関心の対象や人工知能が持つ負の側面への懸念度合が異なるので議論も中々かみ合わないのだろうなと思っているのですが、とは言えパンドラの箱は開かれてしまっています。
先週、Metaが新たにモデル公開に踏み切って、OpenAIはAPI値下げで応え、Googleも追随と直近の目まぐるしい流れは以下です。
2023年2月24日
Metaが最大650億のパラーメーターを持つLLaMAを非商用ライセンスで公開(本投稿の記事)
・申し込みフォームへ記入して利用申請が必要
・LLaMAは、70億から650億パラメータまで4サイズ存在
・公開されているデータセットを使ってトレーニングされているので検証が可能
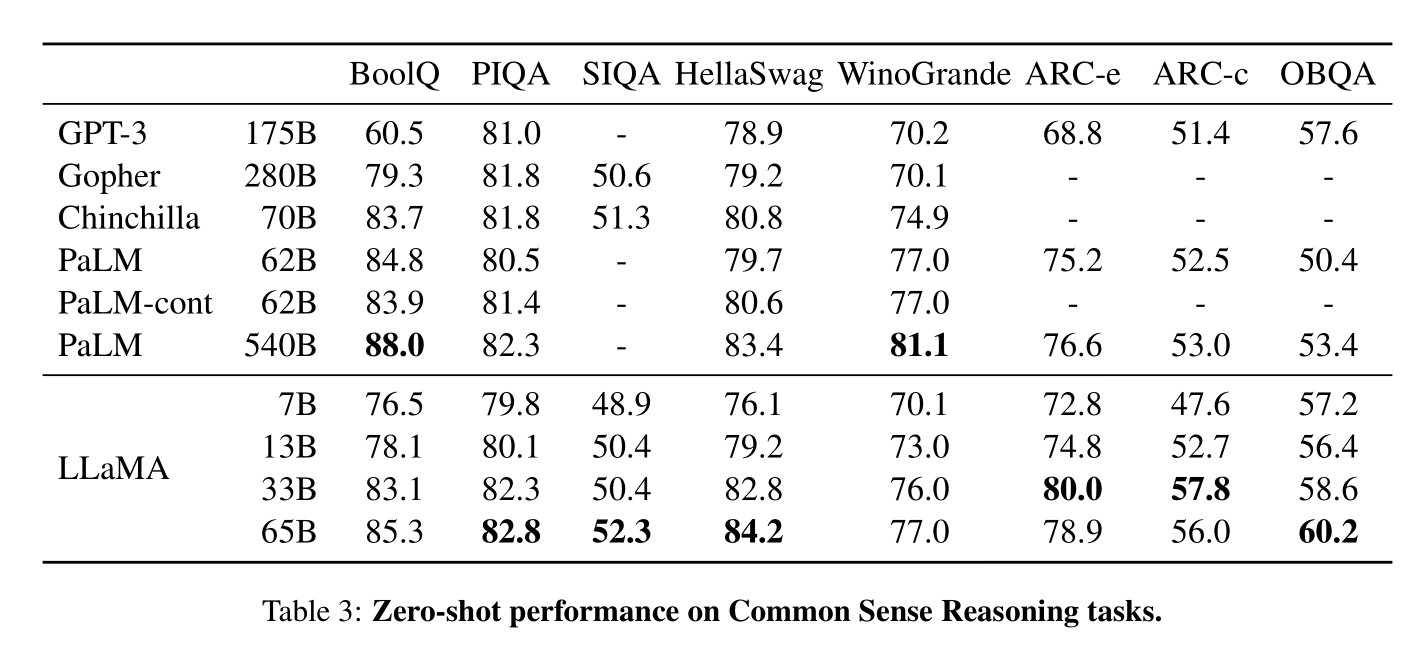
・LLaMA-130億はほとんどのベンチマークでGPT-3(1750億)よりも優れている
・LLaMA-650億は最高のモデルである Chinchilla700億、および PaLM-5400億と競合
2023年3月1日
OpenAIがchatGPTのAPI経由での利用料金を従来比1/10に値下げ
・指輪物語を全部処理させるのに必要な価格が$6ドル
・Wikipediaを全部処理させるのにかかる料金が$8,400ドル
・OpenAIは昨年12月にもAPIの価格体系を大幅に値下げしている
・同時に公開されたWhisper APIは音声→テキスト変換用API。直近急成長中の英会話アプリ「Speak」で使われているもの
2023年3月3日
Googleが最大200億のパラーメーターを持つFLAN-UL2を商用にも使いやすいApacheライセンスで公開
・「あ、ウチも新しいの公開します、でも申し込みフォーム記入は別に要らないっす」と割と煽る感じ
・2種の言語モデルの長所を併せ持つUL2を更に指示調整しているので思考の連鎖機能が大幅に向上
この煽る感じがやり合ってる感があって笑ってしまって本記事のタイトルに繋がりました。
LLaMA、申し込んで見ようかなぁ、でもこれ以上手を広げるのも厳しいよなぁ、と迷っていたらわずか一週間でこれだけの変化です。一過性のトレンドではなく、本質的な重要度を見極めていきたいですが、何にどう注目して取り上げていくかの取捨選択が従来以上に必要とされる時代になってきているなぁ、と感じます。
アイキャッチ画像はstable diffusionのカスタムモデルによる生成で主に高地で家畜として飼われている事の多いラクダの仲間であるラマ(llama)
Metaのオープン サイエンスへの取り組みの一環として、本日、LLaMA(Large Language Model Meta AI)を一般公開します。LLaMAは、AIのこの一分野で研究者が研究を進めるのに役立つように設計された、最先端の大規模言語モデル基盤です。LLaMAなどのより小さく、より高性能なモデルにより、大規模なインフラストラクチャが利用できない研究コミュニティの他のユーザーがこれらのモデルを研究できるようになり、この重要で急速に変化する分野でさらに利用しやすく民主化されます。
LLaMAのような小規模な基盤モデルをトレーニングすることは、新しい手法をテストし、他の人の研究を検証し、新しい用例を探索するために必要な計算機資源がはるかに少なくて済むため、大規模言語モデル研究時に望ましいとされています。基盤モデルは、ラベル付けされていない大量のデータでトレーニングされているため、さまざまなタスクの微調整に最適です。LLaMAをいくつかのサイズ(70億、130億、330億、および 650億パラメーター)で利用できるようにしており、責任あるAIプラクティスへのアプローチに沿ってモデルを構築した方法を詳述するLLaMAモデル カードも共有しています。
昨年、大規模な言語モデル(数十億のパラメーターを持つ自然言語処理(NLP)システム)は、創造的な文章の生成、数学的定理の解決、タンパク質構造の予測、読解問題への回答などの新しい機能を示しました。これらは、AIが何十億もの人々に大規模に提供できる実質的な潜在的利益の最も明確な例の1つです。
大規模な言語モデルにおける最近のすべての進歩にもかかわらず、そのような大規模なモデルをトレーニングして実行するために必要なリソースのために、それらへの完全な研究利用は依然として制限されています。このように利用が制限されているため、これらの大規模な言語モデルがどのように、なぜ機能するのかを理解する研究者の能力が制限されており、堅牢性を向上させ、偏見、毒性、誤報を生成する可能性などの既知の問題を軽減する取り組みの進歩が妨げられています。
より多くのトークン(単語の断片)でトレーニングされた小さなモデルは、再トレーニングが容易で、特定の潜在的な製品の用例に合わせて微調整できます。LLaMA 650億と LLaMA 330億は1.4 兆トークンでトレーニングしました。当社の最小モデルである LLaMA70億は、1 兆個のトークンでトレーニングされています。
他の大規模な言語モデルと同様に、LLaMA は一連の単語を入力として受け取り、次の単語を予測して再帰的にテキストを生成します。モデルをトレーニングするために、ラテン文字とキリル文字の派生言語に焦点を当て、最も多くの話者を持つ20の言語からテキストを選択しました。(訳注:日本語は対象に入っていませんが、使用した全7データセットの中で4.5%を占めるwikipediaデータセットを20言語に絞ったという事で、基本は英語を使って学習しています。日本語が特別に除外されているというわけではありません)
大規模な言語モデルにおける偏見、有毒なコメント、幻覚のリスクに対処するために行う必要がある研究はまだまだあります。他のモデルと同様に、LLaMA はこれらの課題を共有しています。基本モデルとして、LLaMA は用途が広いように設計されており、特定のタスク用に設計された微調整されたモデルとは対照的に、さまざまなユース ケースに適用できます。LLaMA のコードを共有することで、他の研究者は、大規模な言語モデルでこれらの問題を制限または排除するための新しいアプローチをより簡単にテストできます。また、この論文では、モデルの限界を示し、この重要な分野でのさらなる研究をサポートするために、モデルのバイアスと毒性を評価するベンチマークに関する一連の評価を提供しています。
整合性を維持し、誤用を防ぐために、研究の用例に焦点を当てた非商用ライセンスの下でモデルをリリースしています。モデルの利用は、ケースバイケースで学術研究者に許可されます。政府、市民社会、学界の組織に所属する人々。および世界中の産業研究所。アクセスの申請に関心のある方は、私たちの研究論文の申請へのリンクを見つけることができます。
私たちは、AI コミュニティ全体(学術研究者、市民社会、政策立案者、業界)が協力して、責任ある AI 全般、特に責任ある大規模言語モデルに関する明確なガイドラインを作成する必要があると考えています。コミュニティが LLaMA を使用して何を学び、最終的に構築できるかを楽しみにしています。
3.LLaMA、chatGPT値下げ、FLAN-UL2:直近の巨大ゴリラ同士の殴り合い関連リンク
1)ai.facebook.com
Introducing LLaMA: A foundational, 65-billion-parameter large language model
Meta AI’s LLaMA Request Form
2)arxiv.org
LLaMA: Open and Efficient Foundation Language Models
UL2: Unifying Language Learning Paradigms
3)github.com
facebookresearch / llama
google-research/ul2/
4)huggingface.co
google / flan-ul2
5)openai.com
Introducing ChatGPT and Whisper APIs
6)www.yitay.net
A New Open Source Flan 20B with UL2

