
1.Flan Collection:指示調整用のデータセットを更に充実(1/2)まとめ
・自然言語処理が新しいタスクに適応する能力は「指示調整」と呼ばれる多様な指示でモデルを訓練する事に起因する
・Flan Collectionは以前のFLANによって紹介された指示調整用のタスク、ひな形、手法をまとめて新たに公開したもの
・Flan Collectionではトレーニングタスクの拡張に加え、ゼロショット、少数回ショット、思考の連鎖などを組み合わせた
2.Flan Collectionとは?
以下、ai.googleblog.comより「Learning with queried hints」の意訳です。元記事は2023年2月1日、Shayne LongpreさんとAdam Robertsさんによる投稿です。
アイキャッチ画像はstable diffusionを自分でカスタムマイズしたモデルで生成したイラストで、地道にデータセットを作っていく様を表現した画像
言語モデルは、多くの場合、それまで見たことがない指示を読み取ることで、多くの新しい自然言語処理(NLP:Natural Language Processing)タスクを実行できるようになりました。新しいタスクを推論する能力は、FLANによって導入され、T0、Super-Natural Instructions、MetaICL、及びInstructGPTで拡張された「指示調整(instruction tuning)」と呼ばれる多種多様でユニークな指示でモデルを訓練することに大きく起因しています。しかし、このような進歩の原動力となるデータの多くは、より広い研究コミュニティに未公開のままです。
論文「The Flan Collection: Designing Data and Methods for Effective Instruction Tuning」では、指示調整用のタスク、ひな形、手法に関する、より新しく広範なコレクションを精査して公開し、指示調整の分析・改良を行うコミュニティが出来る事を向上させることを目的としています。
このコレクションはFlan-T5とFlan-PaLMで初めて使用され、後者はPaLMより大きな改善を達成しました。例えば、MMLU(Massive Multitask Language Understanding)ベンチマークの57タスクでは3%以上の改善、BBH(BigBench Hard)では8%の改善が見られました。
分析によると、この改善は、より大きく多様なタスクセットと、安価で実装が容易なシンプルなトレーニングおよびデータ増強技術のセットを適用したことに起因することが示唆されます。
具体的には、学習時にゼロショット、少数回ショット、思考の連鎖(CoT:Chain of Thought)などのプロンプトを混ぜる、入力反転(input inversion)でタスクを充実させる、タスクの混合(task mixtures)をバランスよく行う、などの手法があります。
これらの手法により、言語モデルは任意のタスクに対して、たとえ微調整の事例を見たことがないタスクであっても、より適切に推論することができるようになります。これらの知見とリソースを公開することで、より強力で汎用的な言語モデルの研究が加速することを期待しています。
公開された指示調整データ集
2020年以降、下記の年表に示すように、いくつかの指示調整タスク集が相次いで公開されています。最近の研究では、タスクのセット、モデルのサイズ、入力形式がすべて異なっており、統一された手法にまとまっていないのが現状です。この新しいコレクションは、FLAN、P3/T0、Natural Instructionsの以前のコレクションに、新しい対話、プログラム合成、複雑推論タスクを加えたもので、以下「Flan 2022」と呼びます。
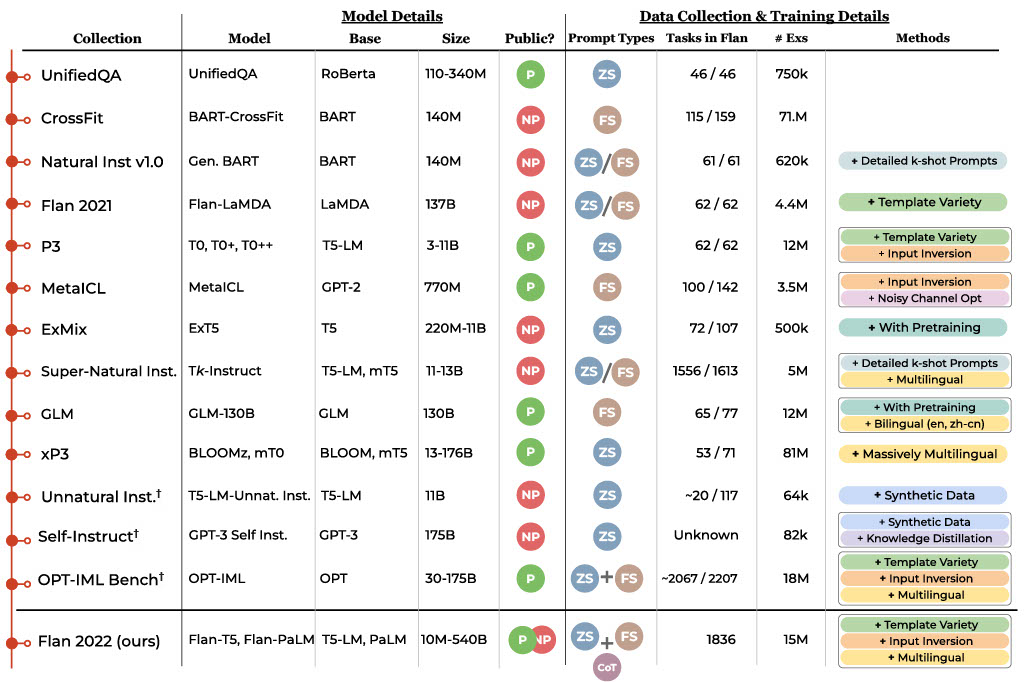
公開済指示調整コレクションの年表
UnifiedQA、CrossFit、Natural Instructions、FLAN、P3/T0、MetaICL、ExT5、Super-Natural Instructions、mT0、Unnatural Instructions、Self-Instruct、OPT-IML Benchが含まれます。表には、リリース日、タスクコレクション名、モデル名、このコレクションで微調整されたベースモデル、モデルサイズ、結果のモデルが公開(緑)か非公開(赤)か、ゼロショットプロンプト(ZS)で学習するか、小数回プロンプト(FS)か、思考の連鎖プロンプト(CoT)の併用(+)か別けてか(/)、Flan2022におけるこのコレクションからのタスク数、サンプルの合計、これらの著作で使われた、コレクションに関連した注目すべき方法などです。タスクとサンプル数は異なる仮定の下で変化するため、概算であることに注意してください。それぞれの数え方は、それぞれの研究のタスク定義を採用しています。
Flan Collectionでは、より有益なトレーニングタスクへの拡張に加え、事前知識を与えずに行う指示(ゼロショットプロンプト)、タスクの実行例を事前に小数回示した後に行う指示(少数回ショットプロンプト)、答えとともに説明を求める指示(思考の連鎖プロンプト)など、異なるタイプの入出力指定でトレーニングを組み合わせています。
独自に収集したデータを活用したInstructGPTを除けば、Flan2022は、トレーニング中にこれらのプロンプト設定を混在させることの強い利点を公に示した最初の研究です。このように、訓練中にプロンプト設定を混ぜることで、推論時にすべてのプロンプト設定が改善されることがわかりました。
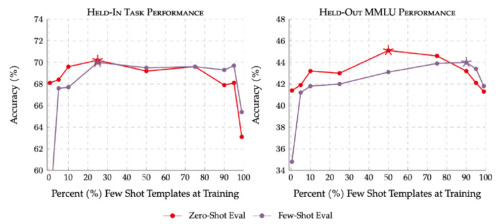
ゼロショットと小数回ショットのプロンプトのひな形を用いて合同で行う訓練により、訓練データと初見データの両方のタスクでパフォーマンスが向上します。星印は、それぞれの設定におけるピーク時のパフォーマンスを示します。赤線はゼロショットプロンプトの評価、紫線は少数回ショットプロンプトの評価を示します。
3.Flan Collection:指示調整用のデータセットを更に充実(1/2)関連リンク
1)ai.googleblog.com
The Flan Collection: Advancing open source methods for instruction tuning
2)arxiv.org
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
3)github.com
google-research / FLAN

