
1.発声に困難を抱える人の音声コミュニケーションを支援するモデル用のデータセットの開発(1/2)まとめ
・自動音声認識(ASR)テクノロジーは発声に困難を持つ個人を支援する可能性を秘めている
・ASRの精度向上は著しいが発声に困難を持つ個人が使用するには十分な性能ではない
・乱れた発声データを学習用に100万を超える発話で構成される大規模データを開発した
2.Disordered Speech Data Collectionとは?
以下、ai.googleblog.comより「Personalized ASR Models from a Large and Diverse Disordered Speech Dataset」の意訳です。元記事は2021年9月9日、Katrin TomanekさんとBob MacDonaldさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Timothy Dykes on Unsplash
流暢な発話が難しい事は何百万人もの人々に影響を及ぼします。根本的な原因は神経学的または遺伝的状態から身体的な困難、脳損傷または難聴にまで及びます。
同様に、結果として生じる発声パターンは、吃音、神経原性の発話障害(dysarthria)、失行症などを含む多様性を持ち、自己表現、社会への参加、および音声対応テクノロジーの利用に悪影響を与える可能性があります。
自動音声認識(ASR:Automatic Speech Recognition)テクノロジーは、発声内容の書き起こしやホームオートメーションシステムの利用しやすさを改善し、コミュニケーション能力を強化することにより、このような発声に困難を持つ個人を支援する可能性を秘めています。
ただし、深層学習システムの計算能力の向上と大規模なトレーニングデータセットが広く利用可能になった事により、ASRシステムの精度は向上しましたが、音声障害を持つ多くの人々にとっては性能が依然として不十分であり、最も恩恵を受ける可能性のある多くの話者がASRテクノロジーを使用できなくなっています。
2019年に、Project Euphoniaを紹介し、乱れた発声用に「個人向けに調整したASRモデル」を使用して、通常の発声用の「個人向けに調整されていないASRモデル」と同等の精度を達成する方法について説明しました。
本日、Interspeech 2021で発表された、個人向けに調整したASRモデルの可用性をより多くのユーザーに拡大することを目的とした2つの研究結果を共有します。
論文「Disordered Speech Data Collection: Lessons Learned at 1 Million Utterances from Project Euphonia」では、100万を超える発話で構成される、大幅に増強された乱れた発声データのコレクションを紹介します。
そして論文「Automatic Speech Recognition of Disordered Speech: Personalized models outperforming human listeners on short phrases」では、前述の音声データに基づいて個人向けに調整したASRモデルを生成する取り組みについて説明します。
このアプローチにより、一般的な音声でトレーニングされた調整せずに使用可能な音声モデルと比較して、選択した領域の単語誤り率を最大85%向上させることができる非常に正確なモデルが得られます。
発声が困難な人の音声を大規模に収集したデータセット
2019年以降、さまざまな条件でさまざまな程度の重症度の言語障害を持つ話者が、Project Euphoniaの研究ミッションをサポートするために音声サンプルを提供してきました。
この取り組みにより、Euphoniaの音声資料は100万回以上の発話に成長し、1330人の話者から1400時間以上(2021年8月現在)で構成されています。
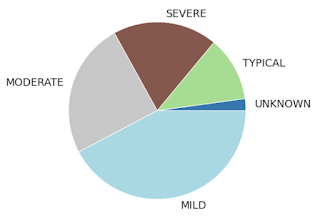
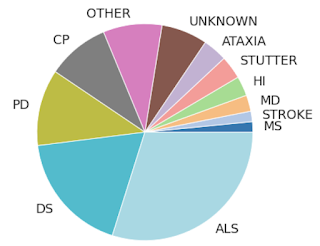
300以上の発話が記録されたすべての話者にわたる言語障害および状態の重症度の分布
話者が5人を超える場合のみ分類されています。(他のすべてはk-匿名性のために「OTHER」に集約されています)。ALS =筋萎縮性側索硬化症、DS =ダウン症、PD =パーキンソン病、CP =脳性麻痺、HI =聴覚困難、MD =筋ジストロフィー、MS =多発性硬化症
データ収集を簡素化するために、実験参加者は、スタジオ品質の録音を収集する理想的な実験室内ではなく、個人のハードウェア(ノートパソコン、またはスマートフォンで。ヘッドフォンの有無が混在)で自宅の録音システムを使用しました。
高い転記一致性を維持しながら、転記にかかる費用を削減するために、台本として収録した音声の収集を優先しました。参加者は、ブラウザベースの記録ツールに表示される例文を読みます。
例文は、ホームオートメーションで想定される例文(「テレビをオンにする」)、介護者との会話(「お腹がすきました」)、日常的な会話(「お元気ですか?良い一日でしたか?」)などの使用例をカバーしました。ほとんどの参加者は1500の例文のリストを受け取りました。これには、1100の固有のフレーズと、それぞれがさらに4回繰り返された100のフレーズが含まれていました。
音声の専門家が、すべての話者の発話の一部分を聞いて、包括的な聴覚-知覚音声評価を実施しました。
発話障害タイプ(例:吃音、構音障害、失行症)、異常な発話の24の特徴の評価(例:鼻音過多、関節の不正確さ、構音障害)。
また、技術的(例:信号のドロップアウト、セグメンテーションの問題)、音響的(例:環境ノイズ、二次話者のクロストーク)など両方の品質評価を記録しました。
個人向けに調整したASRモデル
この拡張された聞き取り難さのある音声データセットは、聞き取り難さを持つ音声を個人向けに調整したASRモデルの新しい手法の基盤です。個人向けに調整された各モデルは、ターゲットとなる話者のデータのみを使用して微調整された標準的なエンドツーエンドのRNNトランスデューサー(RNN-T)ASRモデルを使用します。
RNN-Transducerの概要
この場合、エンコーダーネットワークは8層で構成され、予測子ネットワークは2層の単方向LSTMセルで構成されます。
3.発声に困難を抱える人の音声コミュニケーションを支援するモデル用のデータセットの開発(1/2)関連リンク
1)ai.googleblog.com
Personalized ASR Models from a Large and Diverse Disordered Speech Dataset
2)sites.research.google
Project Euphonia
3)www.isca-speech.org
Disordered Speech Data Collection: Lessons Learned at 1 Million Utterances from Project Euphonia
Automatic Speech Recognition of Disordered Speech: Personalized Models Outperforming Human Listeners on Short Phrases

