
1.2022年のGoogleのAI研究の成果と今後の展望~責任あるAI編~(2/2)まとめ
・モデルの来歴を明示するモデルカードの考えをデータとヘルスケア領域に発展させた
・解釈可能性ツールであるLITをアップデートとし、偏りをチェックするCLPもリリース
・アクセスビリティ、健康、メディアに関してAIの公平性と有益性を促進する研究を実施
2.Google AIの2022年の振り返り~責任あるAI編~
以下、ai.googleblog.comより「Google Research, 2022 & beyond: Responsible AI」の意訳です。元記事の投稿は2023年1月24日、Marian Croakさんの投稿です。
アイキャッチ画像はstable diffusionのカスタムモデルによる生成
テーマ3:ツールおよび技法
責任あるデータ
・データに関する文書
モデルカードとモデルカードツールキットに関する従来の研究を発展させ、データカードとデータカードプレイブックをリリースしました。また、データセットの起源、注釈付けプロセス、使用例、倫理的配慮、進化などを考慮したデータ文書化のベストプラクティスに関する研究も進めてきました。
また、これを医療に応用し、国際的なコラボレーション「Standing Together」の基礎となる「ヘルスシート(healthsheets)」を作成しました。
患者さん、医療従事者、政策立案者を集め データセットが多様で包括的であることを保証する標準を開発し、AIを民主化するために、患者、医療専門家、政策立案者が集まっています。
新しいデータセット
・公平性
MLの公平性と敵対的テストタスクを支援する新しいデータセットをリリースしました。
主に生成テキストデータセットに対するデータで、このデータセットには590の単語やフレーズが含まれています。特定の個人やグループの敏感、もしくは保護された特性に基づくステレオタイプな関連付けがなされている形容詞、単語、フレーズ間の相互作用が示されています。
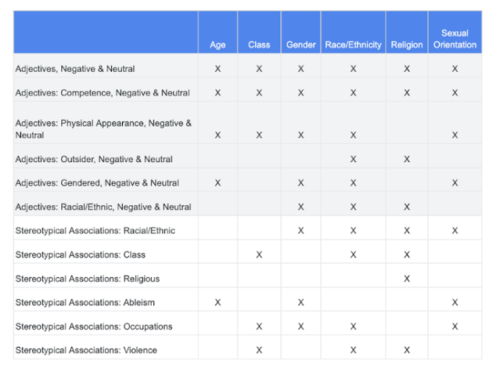
データセットに含まれる敏感な特性の一部で、形容詞やステレオタイプ的な連想との関連を示したもの
・毒性
コメントの毒性が返信先のコメントに依存するケースを特定するための、1万件の投稿からなるデータセットを構築し、一般に公開しました。これにより、モデレーション支援モデルの品質が向上し、オンラインコメントの有害性を改善するより良い方法を研究しているコミュニティを支援します。
・社会的文脈データ
実験的な社会的コンテキストリポジトリ(SCR:Societal Context Repository)を使用して、民族、宗教、年齢、性別、性的指向などのカテゴリに関連する用語のアイデンティティおよび含意のコンテキストデータを、多言語でPerspectiveチームに提供しました。
この補助的な社会的コンテキストデータは、意図しない偏見を大幅に削減するためにデータセットを補強しバランスをとるのに役立ち、広く使用されているPerspective APIの毒性モデルに適用されました。
LIT:Learning Interpretability Tool
より安全なモデルを開発するために重要なことは、デバッグや理解を助けるためのツールを持つことです。これをサポートするために、MLモデルの可視化と理解のためのオープンソースプラットフォームであるLearning Interpretability Tool(LIT)のメジャーアップデートをリリースし、画像と表形式データをサポートするようにしました。
このツールは、Googleでモデルのデバッグ、モデルリリースのレビュー、公平性の問題の特定、データセットのクリーンアップに広く利用されています。また、従来よりも10倍多くのデータを可視化できるようになり、最大で数十万点のデータポイントを一度にサポートするようになりました。
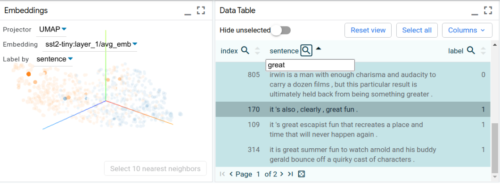
言語解釈ツールで生成した文章をデータテーブル上に表示した画面
反事実的ロジットペアリング(CLP:Counterfactual Logit Pairing)
MLモデルは、入力から参照される属性が削除されたり置換されたりすると予測が反転してしまうことがあります。
例えば、毒性分類器では、「私は男です」と「私はレズビアンです」の違いで、誤って異なる出力を生成する可能性があります。オープンソースコミュニティのユーザがMLモデルにおける意図しないバイアスに対処できるように、私たちは新しいライブラリ、CLP(Counterfactual Logit Pairing)を発表しました。

反事実的ロジットペアリングにより緩和できる予測の不公平性の説明
テーマ4:AIの社会的便益の実証
私たちは、AIを使って、人道的な問題や環境問題など、答えのない難しい問題に取り組むことができると考えています。私たちの研究とエンジニアリングの取り組みは、アクセシビリティ、健康、メディア表現など多くの分野にまたがり、多様性の受け入れの促進と人々の生活の有意義な向上を最終目標として掲げています。
・アクセシビリティ
長年にわたる研究の結果、私たちは、パーソナライズされたAIベースの音声認識モデルを使用して、標準的でない話し方をする人々が他の人とより簡単にコミュニケーションできるようにするAndroidアプリ、Project Relateを発表しました。このアプリは、オーストラリア、カナダ、ガーナ、インド、ニュージーランド、英国、米国の18歳以上の英語話者に提供されています。
また、障がい者のためにAIの進歩を促進するため「Speech Accessibility Project」を立ち上げました。このプロジェクトは、Google、Amazon、Apple、Meta、Microsoft、イリノイ大学アーバナ・シャンペーン校の研究者による、複数年にわたる共同作業の集大成となるものです。このプログラムでは、障害音声の大規模なデータセットを構築し、開発者がアクセシビリティを向上するアプリケーションの研究や製品開発に利用できるようにします。また、この研究は、ユーザーの視線を利用する技術の改善を通じて、重度の運動障害や言語障害を持つ人々を支援する私達の取り組みを補完するものです。
・健康
私たちは、慢性的な健康障害を抱える人々の生活を向上させる技術の構築にも注力しています。同時に、システム上の不公平に対処し、透明性のあるデータ収集を可能にしています。
フィットネストラッカーや携帯電話などの消費者向け技術が健康のためのデータ収集の中心となる中、私たちは臨床リスクスコアの解釈可能性を向上させ、慢性疾患における障害スコアをより適切に予測し、早期治療やケアにつなげるための技術の活用を検討しました。また、この分野におけるインフラとエンジニアリングの重要性を提唱しました。
多くの健康アプリケーションは、生体認証やベンチマークを計算し、出生時の性別を含む変数に基づいて推奨事項を生成するよう設計されたアルゴリズムを使用していますが、この設計はユーザーの現在の性自認(gender identity)を考慮していない可能性があります。
この問題に対処するため、私たちは一般消費者向けテクノロジーとデジタルヘルスアプリケーションのトランス(trans、出生時の性と異なる逆の性同一性を持つ人)およびノンバイナリ(nonbinary、自己認識する性が男性・女性という性別のどちらにも明確に当てはまらないという考えを持つ人)のユーザーを対象とした大規模な国際調査を完了し、これらのテクノロジーで使用されるデータ収集とアルゴリズムがどのように進化すれば公平性を実現できるかを学びました。
・メディア
私たちは、南カリフォルニア大学(USC)のGeena Davis Institute on Gender in Media(GDI)およびSignal Analysis and Interpretation Laboratory(SAIL)と協力し、テレビにおける12年間の表現について調査しました。440時間を超えるテレビ番組の分析に基づき、この報告書では、肌の色が明るいキャラクターと暗いキャラクター、男性と女性、若いキャラクターと年配のキャラクターの画面および発言時間に著しい格差があることを明らかにし、注意を喚起しています。この前例のないコラボレーションは、高度なAIモデルを使用して、メディアで人物中心のストーリーがどのように描かれているかを理解し、主流メディアで公平な表現を促すことを最終目標としています。
2023年以降の計画
私たちは、すべての人にとってポジティブで、包含的で、安全な経験を例示する研究と製品を作る事を約束しています。これは、私たちが行う革新的な仕事に内在するAIのリスクと安全性の多くの側面を理解し、この理解に至るまでに多様な人々の声を取り入れることから始まります。
・責任あるAI研究の推進
私たちは、指標と評価を改善することで、私たちが創造するテクノロジーの意味を理解し、人々がテクノロジーを使ってより良い世界市民になれるようにするための方法論を考案することに努めます。
・製品における責任あるAI研究
製品が新しいAI機能を活用して新しいユーザー体験を提供する際、製品チームと密接に協力して、社会的影響を理解、測定し、製品がGoogleのAI原則を守ることができるような新しいモデリング技術を開発していきます。
・ツールとテクニック
未知の障害を発見し、モデルの動作を説明する能力を向上させ、トレーニング、責任ある生成(responsible generation)、および障害の軽減を通じてモデルの出力を向上させる新しい技術を開発する予定です。
・AIの社会的利益を実証
私たちは、グローバルな目標のためのAIに関する取り組みを拡大し、研究、技術、資金を結集して、持続可能な開発目標の進捗を加速させる計画です。この約束には、NGOや社会的企業を支援するための2,500万ドルが含まれる予定です。私たちは、コミュニティベースの専門家や影響を受けるコミュニティとより多くの協力関係を結ぶことで、包含(inclusion)と公平(equity)に関する活動をさらに進めていきます。これには、カリフォルニア大学バークレー校のOthering and Belonging Institute、PolicyLink、エモリー大学法学部のコミュニティベースの専門家とともに、AIの潜在的影響と下流の害に焦点を当てたEquitable AI Research Roundtables(EARR)を継続することが含まれます。
責任ある倫理的な方法でMLモデルや製品を構築することは、私たちの中核的な焦点であり、中核的な約束です。
謝辞
この作品は、Responsible AI and Human-Centered Technology コミュニティ全体、研究者、エンジニア、プロダクトマネージャー、プログラムマネージャーなど、AI コミュニティに作品を提供するために貢献するすべての人々の努力を反映しています。
Google の研究、2022 年とその後
本記事は、「Google Research, 2022 & Beyond」シリーズの2つ目のブログ記事でした。このシリーズの他の投稿は、以下の投稿にからリンクされています。
2022年のGoogleのAI研究の成果と今後の展望~言語・視覚・生成モデル編~
3.2022年のGoogleのAI研究の成果と今後の展望~責任あるAI編~(2/2)関連リンク
1)ai.googleblog.com
Google Research, 2022 & beyond: Responsible AI
2)pair.withgoogle.com
Measuring Fairness

