
1.2022年のGoogleのAI研究の成果と今後の展望~言語・視覚・生成モデル編~(2/5)まとめ
・MaxViTはオリジナルのVision Transformerの計算量削減に成功し、より効率的に規模を拡大可能にした
・Pix2Seqは物体検出に言語モデルを応用するアイディアでシンプルで汎用的な手法を探求した
・LOLNerfは一枚の画像から三次元構造を推定可能。機械が3次元世界をよりよく理解できるようになった
2.Google AIの2022年の振り返り~コンピュータビジョン編~
以下、ai.googleblog.comより「Google Research, 2022 & Beyond: Language, Vision and Generative Models」の意訳です。元記事の投稿は2023年1月18日、Google AIのトップのJeff DeanがGoogle Research communityを代表しての執筆です。
アイキャッチ画像はstable diffusionのカスタムモデルによる生成
コンピュータビジョン(Computer Vision)
コンピュータビジョンは進化を続け、急速な進歩を遂げています。
2020年のVision Transformersに関する私達の研究から始まった一つのトレンドは、コンピュータビジョンモデルに畳み込みニューラルネットワークではなく、Transformerを用いることです。
畳み込みの局所的に特徴を構築して抽象化する能力は、多くのコンピュータビジョン問題に対して強力なアプローチですが、モデル全体で画像の局所的、及び非局所的な情報を利用できるTransformerの汎用的なAttention機構ほど柔軟ではありません。しかし、汎用的なAttention機構は画像サイズに対して二次関数的に規模が拡大してしまうため、より高解像度の画像に適用するには困難が伴います。
「MaxViT: Multi-Axis Vision Transformer」では、視覚モデルの各段階において、局所的、及び非局所的な情報を結合するアプローチを模索しました。オリジナルのVision Transformerに存在する完全なAttentionメカニズムよりも効率的に規模を拡大する事ができます。このアプローチは、ImageNet-1k分類タスクや様々な物体検出タスクにおいて、他の最先端モデルよりも優れた性能を発揮できますが、計算コストは著しく低いです。
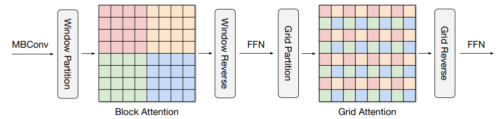
MaxViTでは、多軸のAttention機構が、ブロック化した局所的Attentionと拡張した大域的Attentionを順次行い、その後にFFNを行いますが、その複雑さは一次関数的な増加に留まります。同じ色の画素は一緒に処理されます。
「Pix2Seq: A Language Modeling Framework for Object Detection」では、全く異なる視点から物体検出に取り組む、シンプルで汎用的な手法を探求しています。
既存の「特定のタスクに特化したアプローチ」とは異なり、私達は物体検出を「観測された画素入力を条件とする言語モデリングタスク」として捉え、画像中の注目すべき物体に関する位置やその他の属性を「読み取る」ようにモデルを学習させます。
Pix2Seqは、大規模な物体検出COCOデータセットにおいて、高度に専門化・最適化された既存の検出アルゴリズムと比較して競争力のある結果を達成し、さらに大規模な物体検出データセットでモデルを事前学習することにより、その性能を向上させることができます。

物体検出のためのPix2Seqフレームワーク
ニューラルネットワークは画像を認識し、各物体に対して境界ボックスとクラスラベルを生成します。
コンピュータビジョンのもう一つの長年の課題は、1枚または数枚の2次元画像から実世界の物体の3次元構造をよりよく理解することです。私たちは、この分野の進歩のために複数のアプローチを試みています。
「Large Motion Frame Interpolation」では、数秒間隔で撮影された2枚の画像の間を補間することで、部分的に大きな動きがあっても短いスローモーション動画が作成できることを示しました。
「View Synthesis with Transformers」では、ライトフィールドニューラルレンダリング(LFNR:Light Field Neural Rendering)と汎用的パッチベースニューラルレンダリング(GPNR:Generalizable Patch-based Neural Rendering)という2つの新しい技術を組み合わせて、コンピュータビジョンの長年の課題である風景の新しい視点を合成する方法を示しています。
LFNRは、参照画素の色の組み合わせを学習するTransformersを用いることで、視点に依存した効果を正確に再現できる技術です。LFNRは単一風景内ではうまく機能しますが、新しい風景に一般化させる事には限界があります。GPNRは、正規化された位置エンコーディングを持つ一連のTransformersを用いることでこの問題を克服し、一連の風景で学習させることで、新しい風景の視点を合成することができます。これらの技術を組み合わせることで、以下のように、わずか数枚の風景画像から新規風景に対しても高品質な視点合成が可能になります。

LFNRとGPNRを組み合わせると、わずか数枚の画像が与えられただけで、その風景の新しい見方を作り出すことができるモデルです。これらのモデルは、試験管の屈折や半透明物体のような視野に依存する効果を扱うときに特に効果的です。出典 NeX/Shinyデータセットの静止画
さらに進んで、「LOLNerf: Learn from One Look」では、たった1枚の2次元画像から高品質な特徴表現を学習する能力を探っています。特定のカテゴリの物体の多くの異なる例(例えば、異なる猫の多くの単一画像)で学習して、物体の3D構造を予測する事が出来ます。そして、新しいカテゴリの単一画像(例えば、以下に示すように、あなたの愛猫の単一画像)の3Dモデルを作成可能になります。

上:AFHQの猫画像例。下:LOLNeRFで作成した新しい3D視点
この研究の汎用的な目的は、コンピュータが3次元世界をよりよく理解できるようにするための技術を開発することです。これはコンピュータビジョンの長年の夢でした!
3.2022年のGoogleのAI研究の成果と今後の展望~言語・視覚・生成モデル編~(2/5)関連リンク
1)ai.googleblog.com
Google Research, 2022 & Beyond: Language, Vision and Generative Models
2)arxiv.org
Large Language Models Encode Clinical Knowledge
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Pixel Recurrent Neural Networks
Neural Discrete Representation Learning
Image Transformer
Vector-quantized Image Modeling with Improved VQGAN
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
3)benanne.github.io
Guidance: a cheat code for diffusion models
4)research.google
Imagen : unprecedented photorealism × deep level of language understanding
Phenaki : Realistic video generation from open-domain textual descriptions
5)google-research.github.io
AudioLM : A Language Modeling Approach to Audio Generation
6)ai.google
2022 AI Principles Progress Update(PDF)

