
1.PaLI:言語-画像モデルを100以上の言語に規模拡大(1/2)まとめ
・言語モデルは規模拡大すると多様な能力を発揮できるようになり成功している
・視覚と言語を同時に扱う視覚-言語モデルの規模拡大と多言語化対応に挑戦した
・109言語に対応させ、既存の画像や言語用ベンチマークで最先端の性能を達成
2.PaLIとは?
以下、ai.googleblog.comより「PaLI: Scaling Language-Image Learning in 100+ Languages」の意訳です。元記事は2022年9月15日、Xi ChenさんとXiao Wangさんによる投稿です。
アイキャッチ画像はstable diffusionによる生成で多言語対応したトトロ
先進的な言語モデル(GPT、GLaM、PaLM、T5など)は、パラメータ数を増やす事で多様な能力を発揮し、タスクや言語間で素晴らしい結果を達成してきました。
視覚-言語(VL:Vision-language)モデルは、画像への説明文付与、視覚的質問回答(VQA:Visual Question Answering)、物体認識、文脈内(in-context)光学文字認識(OCR:optical-character-recognition)など、多くのタスクに対応するために同様の規模拡大の恩恵を受けることができます。
これらの実用的なタスクの成功率を高めることは、日常的な操作やアプリケーションにとって重要です。さらに、真の意味で普遍的なシステムのためには、視覚-言語モデルは1つの言語だけでなく、多くの言語で動作する必要があります。
論文「PaLI: A Jointly-Scaled Multilingual Language-Image Model」では、100以上の言語で多くのタスクを実行できるように訓練された統一言語画像モデル(unified language-image model)を紹介します。
これらのタスクは、視覚、言語、そして視覚的質問回答、画像説明文付与、物体検出、画像分類、OCR、テキスト推論などのマルチモーダル画像と言語アプリケーションにまたがるものです。さらに、109言語での注釈を自動的に収集した公共画像のコレクションを使用し、これをWebLIデータセットと呼びます。WebLI上で事前学習したPaLIモデルは、COCO-Captions, TextCaps, VQAv2, OK-VQA, TextVQAなどの画像と言語ベンチマークで最先端の性能を達成します。
概要
本プロジェクトの目的の一つは、言語モデルと視覚モデルがどのように相互作用するか、特に言語-画像モデルの規模拡大性を検証することです。
私達は入力モーダルごとの規模と規模拡大の結果として生じるクロスモーダルの相互作用の両方を調査します。私たちの最大のモデルは170億(17B)パラメータで訓練されます。視覚コンポーネントは40億(4B)パラメータに、言語モデルは130億(13B)まで規模拡大します。
PaLIモデルのアーキテクチャはシンプルで、再利用性と拡張性に優れています。入力テキストを処理するTransformerエンコーダと、出力テキストを生成するauto-regressive Transformerデコーダから構成されています。
画像を処理するために、Transformerエンコーダーの入力には、Vision Transformer(ViT)によって処理された画像を表す「ビジュアルワード」も含まれます。PaLIモデルの重要な要素は再利用であり、mT5-XXLやlarge ViTsなど、過去に学習したユニモーダル視覚・言語モデルからの重みをモデルに付与しています。この再利用により、ユニモーダルな学習から能力を引き継ぐことができるだけでなく、計算コストの削減も可能となります。
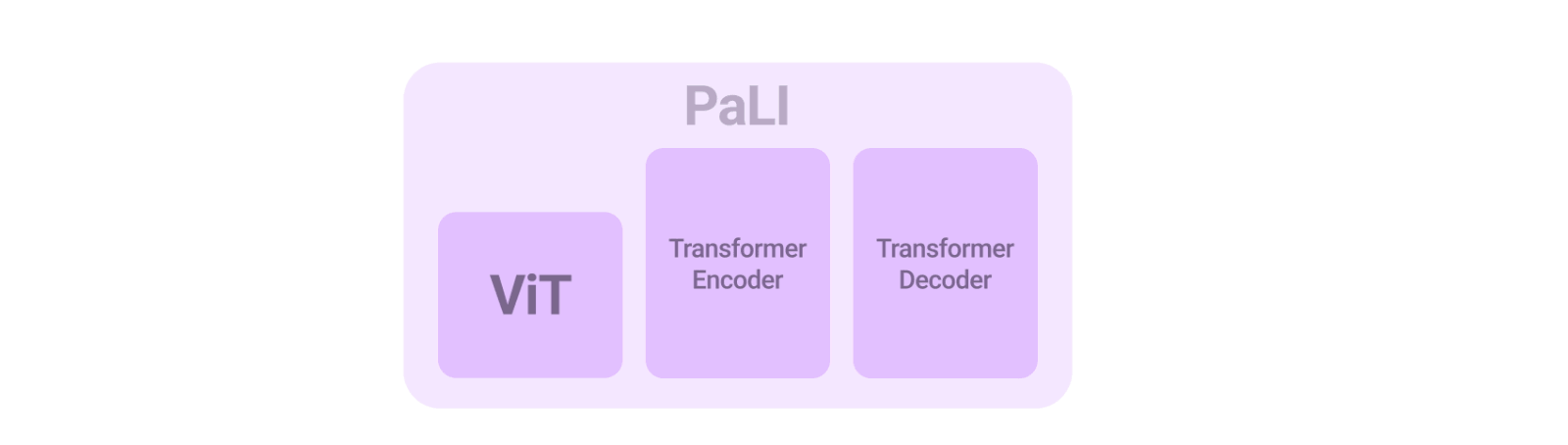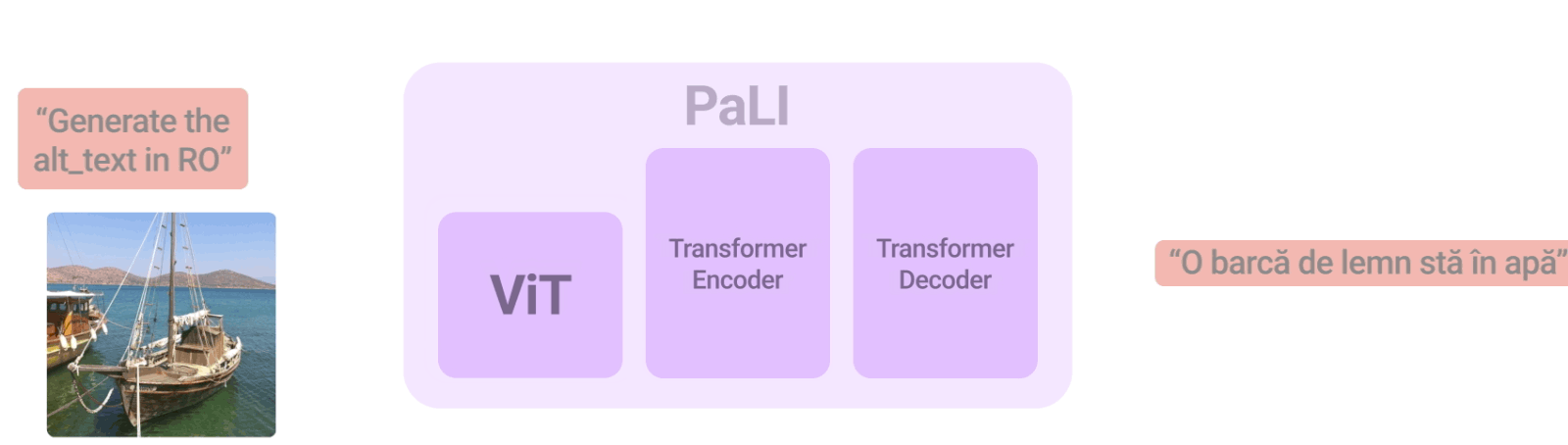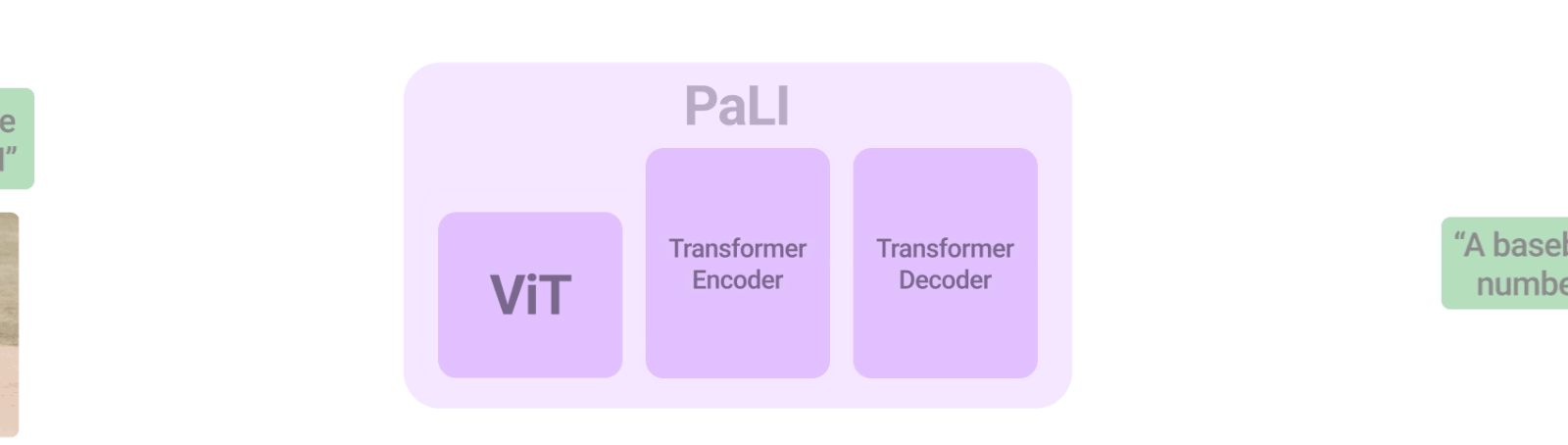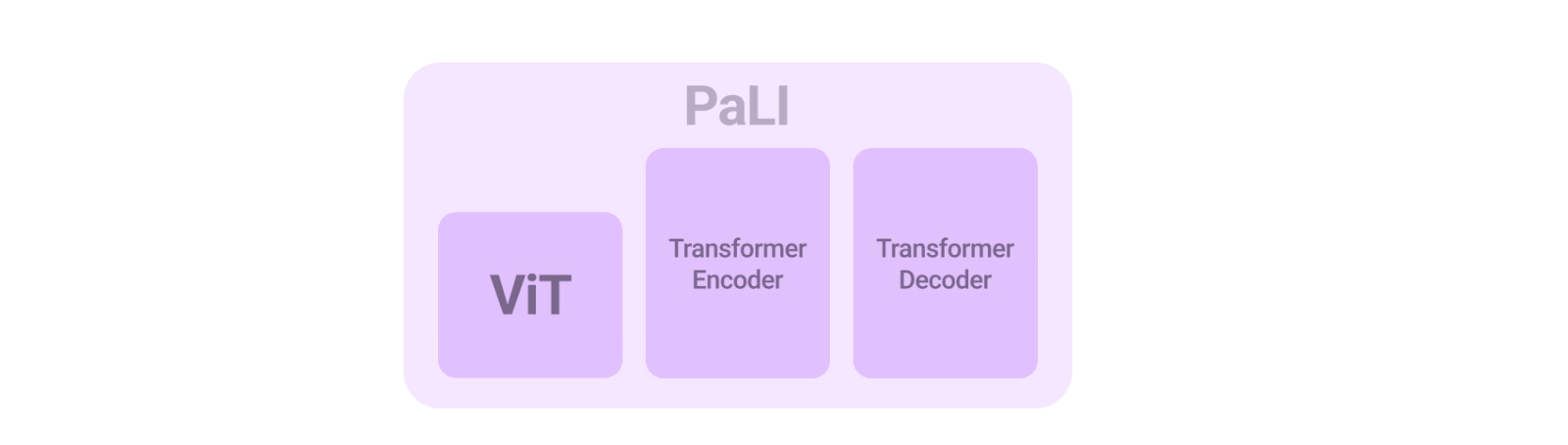
PaLIモデルは、言語-画像、言語のみ、画像のみの領域で、同じAPIを用いて幅広いタスクに対応します。(例:視覚的質問回答、画像への説明文付与、風景-文書理解など)。このモデルは100以上の言語をサポートするように学習しており、複数の言語-画像タスクに対して多言語で実行できるようにチューニングされています。
100言語以上に対応する言語-画像理解データセット
ディープラーニングの規模拡大に関する研究によると、より大きなモデルを効果的に学習させるには、より大きなデータセットが必要であることが示されています。言語-画像事前学習の可能性を引き出すために、私たちは、公共のウェブ上で利用可能な画像とテキストから構築された多言語言語画像データセットであるWebLIを構築しました。
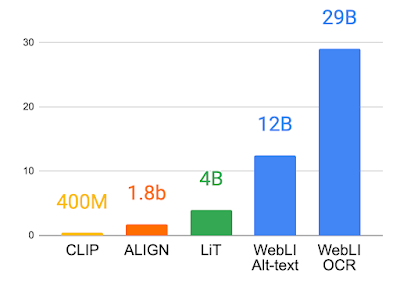
WebLIはテキスト言語を英語のみのデータセットから109言語まで規模拡大し、多くの言語での下流タスクを可能にします。データ収集プロセスは、ALIGNやLiTなど他のデータセットで採用されているものと同様であり、WebLIデータセットを100億の画像と120億のalt-textにスケールアップすることを可能にしました。
ウェブテキストの注釈に加えて、Cloud Vision APIを適用して画像のOCRを実行し、290億の画像とOCRのペアを作成しました。
68の汎用的な視覚と視覚-言語のデータセットに対してトレーニング、検証、テスト分割を行い画像の重複をほぼ排除します。これにより文献にあるように、下流の評価タスクからデータが漏れないようにします。
さらにデータ品質を向上させるため、画像とaltテキストのペアをクロスモーダルな類似性に基づいてスコアリングし、画像の10%のみを残すように閾値を調整しました。PaLIの学習に使用された画像は、合計10億枚です。

多言語のaltテキストとOCRに関連したWebLIからのサンプル画像
2枚目の画像はjopradier(オリジナル)、CC BY-NC-SA 2.0ライセンスの下で使用されています。残りの画像も許可を得て使用しています。
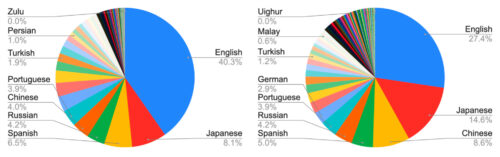
WebLIにおけるalt-textとOCRから認識された言語の統計
3.PaLI:言語-画像モデルを100以上の言語に規模拡大(1/2)関連リンク
1)ai.googleblog.com
PaLI: Scaling Language-Image Learning in 100+ Languages
2)arxiv.org
PaLI: A Jointly-Scaled Multilingual Language-Image Model

