
1.CLIP:学習していない視覚タスクを実行なニューラルネット(1/3)まとめ
・自然言語を教師に視覚的概念を効率的に学習するネットワークCLIPの紹介
・CLIPはGPT-2やGPT-3の「ゼロショット」機能を視覚タスクで実現
・個々のタスク用に最適化せずとも様々な視覚分類ベンチマークを実行可能
2.CLIPとは?
以下、openai.comより「CLIP: Connecting Text and Images」のまとめです。元記事の投稿は2021年1月5日、Alec Radfordさん、Ilya Sutskeverさん、Jong Wook Kimさん、Gretchen Kruegerさん、Sandhini Agarwalさん, Justin Jay Wangさんによる投稿です。
文章から画像を作成するDALL·Eと同時に発表された、DALL·Eの背後に存在する技術です。
2021年1月追記)CLIPを使ってみた結果はこちら。
アイキャッチ画像のクレジットはPhoto by STIL on Unsplash
自然言語を教師データとして視覚的な概念を効率的に学習するCLIPと呼ばれるニューラルネットワークを紹介します。CLIP(Contrastive Language–Image Pre-training、対照的言語画像事前トレーニング)は、GPT-2やGPT-3の「ゼロショット」機能と同様に、認識して欲しい視覚カテゴリの名前を提供するだけで、視覚分類ベンチマークを実行できます。
ディープラーニングはコンピュータービジョンに革命をもたらしましたが、現在の手法にはいくつかの大きな問題があります。一般的な視覚タスク用データセットは、小さいデータセットであっても労働集約的な作業が必要になりコストがかかります。
更に、標準的な視覚モデルが出来る事は1つのタスクだけであり、他のタスクの応用が出来ません。新しいタスクに適応させるには多大な労力が必要です。
ベンチマーク用タスクでうまく機能するモデルは、残念ながらモデルに負荷をかけるようなストレステストではパフォーマンスが低くなります。これらの問題は、コンピュータービジョンタスクにディープラーニングを適用する手法全体に疑問を投げかけています。
本日、これに対処することを目的としたニューラルネットワークを紹介します。これは、インターネット上で豊富に利用できる様々な自然言語の教師を備えた様々な画像でトレーニングされています。
設計上、GPT-2およびGPT-3の「ゼロショット」機能と同様に、様々な分類ベンチマークを実行するようにネットワークに自然言語で指示できます。個々のベンチマーク用に最適化する必要はありません。
これは重要な変更です。モデルをベンチマーク用に最適化しないので、ベンチマーク結果が従来よりもモデルの性能を表現するようになる事を意味しています。私達のシステムは、各ベンチマーク用のラベル(128万)を使用していませんが、ゼロショットでImageNetのResNet 50のパフォーマンスに匹敵するスコアを出します。同時にResNetが対応できないような様々なベンチマークにも対応可能で「堅牢性ギャップ(robustness gap)」を最大75%埋めます。
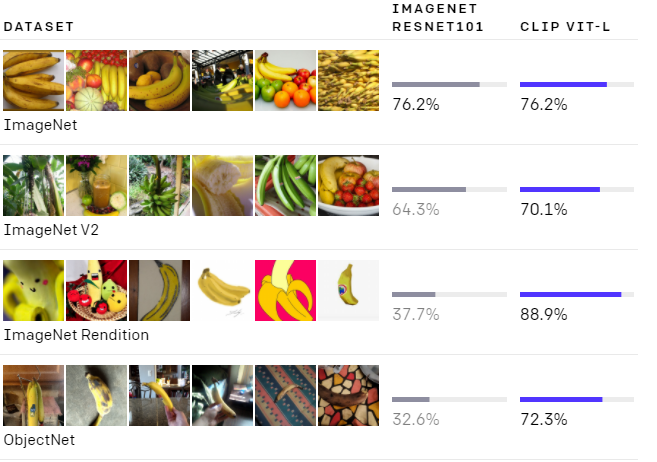
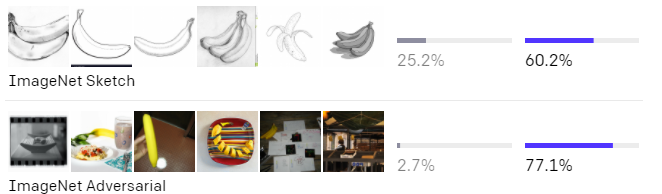
どちらのモデルもImageNetテストセットでは同程度の精度です。しかし、CLIPのパフォーマンスは、ImageNetとは異なるデータセットで精度を測定するとどの程度機能できるかを表現しています。例えば、ObjectNetは、家の中の様々な形状や背景を持つ物体を認識するモデルの機能をチェックします。ImageNet RenditionとImageNet Sketchは、物体のより抽象的な描写を認識するモデルの機能をチェックしています。
背景と関連する研究
CLIPは、ゼロショット転移、自然言語教師、およびマルチモーダル学習に関する大量の研究に基づいて構築されています。ゼロデータ学習のアイデアは10年以上前にさかのぼりますが、最近まで、学習時に現れなかった物体にも対応可能な一般化手法としてコンピュータビジョンで主に研究されていました。
重要な洞察は、一般化と転移を可能にする柔軟な予測空間として自然言語を活用することでした。
2013年、Richer Socherとスタンフォード大学の共著者は、CIFAR-10でモデルをトレーニングして単語ベクトルembedding空間で予測を行うことにより概念実証を開発し、このモデルが2つの未見クラスを予測できることを示しました。同じ年、DeVISEはこのアプローチを拡張し、ImageNetモデルを微調整して、元のトレーニングセットに含まれている1000クラス以外の物体を正しく予測できるように一般化できることを実証しました。
CLIPに最もインスピレーションを与えたのはFAIRのAngLiと彼の共著者の仕事です。2016年に自然言語教師を使用してImageNetデータセットなどの既存のコンピュータービジョン分類データセットへのゼロショット転移が可能な事を実証しました。
彼らは、ImageNet CNNを微調整して、3000万枚のFlickr写真のタイトル、説明、タグのテキストから、はるかに幅広い視覚的概念(visual n-grams)を予測することでこれを実現しました。ImageNetのゼロショットで11.5%の精度を達成したのです。
最後に、CLIPは、過去1年間の自然言語教師から視覚的特徴表現を学ぶことを再考する一連の論文の一部です。この一連の研究には、Transformerなどのより最新のアーキテクチャが使用され、自己回帰言語モデリングを調査したVirTex、マスク言語モデリングを調査したICMLM、CLIPで使用しているのと同じ対照的な目的を医療画像の分野で調査したConVIRTが含まれます。
手法
様々な画像分類データセットで競争力のあるゼロショットパフォーマンスを実現するには、単純な事前トレーニングタスクを規模拡大するだけで十分であることを示します。私達の手法では、インターネット上で見つかった画像と組み合わせたテキストという、豊富に利用可能な教師ソースを使用します。このデータは、CLIPの次の代替トレーニングタスクを作成するために使用されます。画像を指定して、ランダムに抽出された32,768個の断片的なテキストのセットを使い、データセット内で実際にペアになっているものを予測します。
3.CLIP:学習していない視覚タスクを実行なニューラルネット(1/3)まとめ
1)openai.com
CLIP: Connecting Text and Images
2)cdn.openai.com
Learning Transferable Visual Models From Natural Language Supervision(PDF)
3)github.com
openai / CLIP

