
1.Director:マネージャーの上に社長を配置して疎らな報酬に挑む(2/2)まとめ
・Directorは世界モデルに基づく2つの最先端アルゴリズムより高いスコアを出した
・必ずしも長期目線の探索を必要としてないタスクでも高いスコアを出せた
・学習した世界モデルのサブゴールを解釈しやすい事もDirectorの特色
2.Directorの性能
以下、ai.googleblog.comより「Deep Hierarchical Planning from Pixels」の意訳です。元記事は2022年7月8日、Danijar Hafnerさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Keenan Barber on Unsplash
私達はDirectorを同じく世界モデルに基づく2つの最先端アルゴリズムと比較評価しました。
Plan2Exploreはタスク報酬とアンサンブルの不一致に基づく探索ボーナスの両方を最大化し、Dreamerは単にタスク報酬を最大化するものです。両ベースラインとも、世界モデルが想像した軌道から非階層的なポリシーを学習します。
Plan2Exploreでは、ノイズの多い動きになってしまうことがわかりました。そのため、ロボットが仰向けになり、ゴールに到達できません。
Dreamerは最小の迷路ではゴールに到達できますが、より大きな迷路の探索に失敗します。このような大きな迷路では、Directorが唯一の方法であり、確実にゴールを見つけることができます。
3D環境の特徴表現学習の課題とは別に、非常に疎な報酬を発見するエージェントの能力を研究するために、私達は一連のVisual Pin Padタスクを提案します。
これらの課題では、エージェントは黒い正方形を操作し、それを動かして異なる色のパッドを踏みます。画面下部には、以前に起動したパッドの履歴が表示され、長期記憶の必要性を排除しています。タスクは、すべてのパッドをアクティブにするための正しい順序を発見することであり、その時点でエージェントは疎な報酬を受け取ることができます。ここでもDirectorは従来の手法を大きく上回っています。
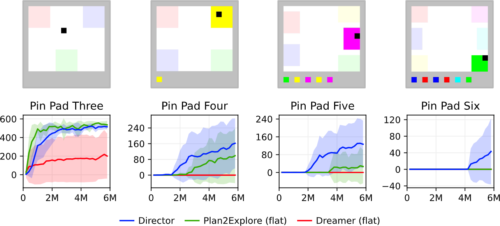
Visual Pin Padベンチマークは、3Dシーンの知覚や長期記憶などの互いに相関する課題なしに、非常にまばらな報酬の下でエージェントを評価することを可能にします。
私達は、報酬が疎なタスクの解決に加えて、関連文献によく見られる幅広いタスクに対するDirectorの性能を研究しています。これらのタスクは必ずしも長期目線の探索を必要としません。
この実験では、Atari games、Control Suiteタスク、DMLab迷路環境、研究プラットフォームであるCrafterを含む12のタスクが含まれています。その結果、Directorは同じハイパーパラメータでこれら全てのタスクに成功し、階層学習プロセスの頑健性を実証しました。
更に、タスクの報酬をworkerに与えることで、Directorはタスクに対する正確な動作を学習し、最先端のDreamerアルゴリズムの性能に完全に匹敵するか、それを上回る性能を示します。
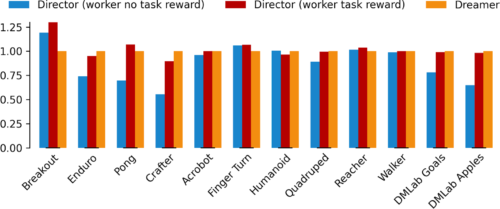
Directorは報酬が密で標準的な幅広いタスクを同じハイパーパラメータで解く事が可能で、階層学習プロセスの頑健性を実証しています。
ゴールの可視化
Directorは潜在的なモデルの状態をゴールとして用いますが、学習した世界モデルによって、これらの目標を人間が解釈できるような画像にデコードすることができます。
私達は、Directorの意思決定に関する洞察を得るために、複数の環境に対するDirectorの内部ゴールを可視化し、Directorが長期目線が必要なタスクを分解する多様な戦略を学習していることを見出しました。
例えば、WalkerとHumanoidのタスクでは、managerが前傾姿勢と床面の移動を要求し、workerが脚の動き方の詳細を補完します。Egocentric Ant Mazeでは、managerは異なる壁の色の並びを要求することによって、アリロボットを操縦します。2D研究プラットフォームCrafterでは、画面下部のインベントリ表示で資源収集や道具を依頼し、DMLab迷路では、目的の物を収集した直後のテレポートアニメーションでworkerを励まします。


左:Egocentric Ant Maze XLでは、managerはworkerに異なる色の壁をターゲットにして迷路の中を進むように指示します。
右:Visual Pin Pad Sixでは、managerは下部の履歴表示と異なるパッドを強調表示することでサブゴールを指定します。


左:Walkerでは、managerは前傾姿勢と、両足を地面から離すこと、床の模様が変わることを要求し、workerは足の動きの詳細を補完します。
右:難易度の高いヒューマノイドタスクでは、Directorが画素情報から確実に立ち上がり歩けるようになります。エピソードを早期に終了させる事はありません。


左:Crafterでは、画面下部のインベントリ表示部で、managerがリソース収集を依頼します。
右:DMLab Goals Smallでは、workerにタスクを伝える方法として、報酬を受け取る際に発生するテレポートアニメーションをmanagerがリクエストしています。
今後の方向性
私達はDirectorを階層型強化学習(HRL:Hierarchical reinforcement learning)研究の一歩として捉え、将来的にそのコードを公開できるよう準備を進めています。
Directorは、実用的で解釈可能な一般に適用可能なアルゴリズムであり、研究コミュニティによる将来の階層型人工エージェントの開発に効果的な出発点を提供するものです。
例えば、ゴールを完全な特徴表現ベクトルの部分集合にのみ対応させること、ゴールの持続時間を動的に学習すること、3段階以上の時間的抽象度を持つ階層型エージェントを構築することなどが考えられます。
私達は、HRLにおける将来のアルゴリズムの進歩が、知的エージェントの性能と自律性の新しいレベルを解き放つだろうと楽観視しています。
3.Director:マネージャーの上に社長を配置して疎らな酬に挑む(2/2)関連リンク
1)ai.googleblog.com
Deep Hierarchical Planning from Pixels
2)arxiv.org
Deep Hierarchical Planning from Pixels

