
1.4D-Net:センサーの奥行情報とカメラのRGB画像を同時に扱う(1/2)まとめ
・人間は世界を時間軸を加えた4次元で体感しているが自律走行車やロボットには不可能
・センサーで取得した奥行情報と画像を時間的に並んだデータとして組み合わせるのが難しい
・4D-Netは三次元センサーと車載カメラのRGB画像を時間軸で効果的に組み合わせるモデル
2.4D-Netとは?
以下、ai.googleblog.comより「4D-Net: Learning Multi-Modal Alignment for 3D and Image Inputs in Time」の意訳です。元記事は2022年2月23日、AJ PiergiovanniさんとAnelia Angelovaさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Daniele Levis Pelusi on Unsplash
すぐに実感できる事ではありませんが、私たちは皆、世界を4次元(4D:four dimensions)で体感しています。例えば、道を歩いたり運転したりするとき、私たちは3次元世界をスナップショットとして切り取り、その視覚入力の流れを観察し、それを時間的にまとめて4次元の視覚入力としています。
現在の自律走行車やロボットは、LiDARやカメラなどのさまざまなセンサーを搭載し、これらの情報の多くを取得することができます。
LiDARは、光パルスを利用して風景内の物体の3次元座標を確実に測定するセンサーです。場所を選ばずに利用可能ですが、センサーから遠く離れるほど情報を取得できる点が少なくなり、疎らで範囲が限定されているのも特徴です。つまり、遠くの物体はわずかな点としてしか取得できないか、まったく取得できない可能性があり、LiDARだけでは見えない可能性があります。
一方で、カメラ画像は高密度入力であり、物体の検出や区分といった意味的な理解に非常に有効です。解像度の高いカメラは、遠くの物体を検出するのに非常に有効ですが、奥行を測る精度は低くなります。自律走行車は、LiDARと車載カメラの両方のセンサーからデータを収集します。各センサーの測定値は一定の時間間隔で記録され、4次元の世界を正確に表現することができます。
しかし、この2つを組み合わせて使うアルゴリズムに関する研究は非常に少ないです。特に「時間通りに」つまり、時間的に並んだデータの列として扱うアルゴリズムです。
これは、以下の2つの大きな課題によるものです。
両方のセンサー情報を同時に使用する場合、
(1)計算効率を維持するのが難しい
(2)LiDARによって得た点に関する情報とオンボードカメラのRGB画像入力が必ずしも直接対応していないため、1つのセンサーと別のセンサーの情報を組み合わせる事が必要になり更に複雑になる
ICCV 2021で発表した「4D-Net for Learned Multi-Modal Alignment」では、4次元データを処理できるニューラルネットワークを発表しており、私達はこのネットワークを4D-Netと呼んでいます。
4D-Netは、三次元LiDARによる点群と車載カメラのRGB画像という2種類のセンサーを、両方が時間に沿って連なって存在するときに効果的に組み合わせる初めての試みです。
また、動的接続学習法(dynamic connection learning method)も紹介します。これは、両方の特徴表現にまたがって接続学習(connection learning)を行うことで、風景から4次元情報を取り込む手法です。
最後に、4D-Netが計算効率を維持しながら、遠くの物体を検出するために、モーションキュー(motion cues)と高密度画像情報をより良く利用できることを実証します。
4D-Net
私達は、4次元入力(3次元点群および車載カメラの画像データ)を用いて、非常に人気の高い視覚理解タスクである物体の3次元境界ボックス検出を行う事を計画します。
課題は、異なる領域から生みだされ、必ずしも一致しない特徴を持つ2つのセンサー入力をどのように組み合わせるかという事です。
つまり、まばらなLiDAR入力が3D空間をカバーし、密なカメラ画像は風景の2D投影だけを生成します。
それぞれの特徴の正確な対応は不明であるため、この2つのセンサー入力とその特徴表現の間の接続を学習することを目指します。私達は、以下に示すように、各特徴層(feature layers)が他のセンサー入力から得た潜在層(potential layers)と結合することができるニューラルネットワーク特徴表現を考えています。
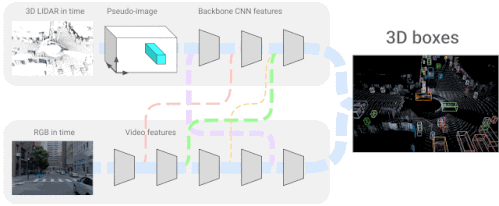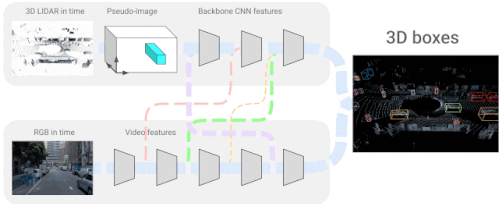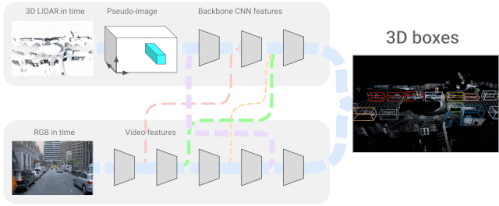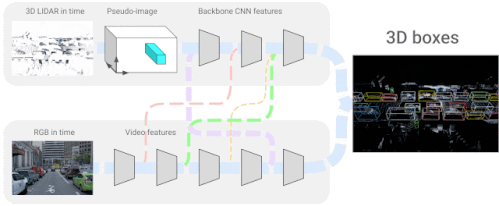
4D-Netは、3D LiDARの点群と、同じく動画として時間的にストリーミングされるRGB画像を効果的に組み合わせ、異なるセンサー間の接続とその特徴表現を学習します。
3.4D-Net:センサーの奥行情報とカメラのRGB画像を同時に扱う(1/2)関連リンク
1)ai.googleblog.com
4D-Net: Learning Multi-Modal Alignment for 3D and Image Inputs in Time
2)openaccess.thecvf.com
4D-Net for Learned Multi-Modal Alignment(PDF)

