
1.GoEmotions:きめ細かい感情分類を行うためのデータセット(1/2)まとめ
・感情分類は1992年に提案された6つの基本的な感情を対象とする場合が多い
・GoEmotionsは12ポジティブ、11ネガティブ、4あいまい、1中立の感情からなる
・英語掲示板サイトRedditの58,000のコメントに人間が注釈を付けたデータセット
2.GoEmotionsとは?
以下、ai.googleblog.comより「GoEmotions: A Dataset for Fine-Grained Emotion Classification」の意訳です。元記事の投稿は2021年10月28日、Dana AlonさんとJeongwoo Koさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Tengyart on Unsplash
感情は社会的相互作用の重要な側面であり、人々の行動に影響を与え、人間関係を形成します。これは特に言語に当てはまります。ほんの数語で、さまざまな微妙で複雑な感情を表現することができます。
そのため、機械が文脈と感情を理解できるようにすることは、研究コミュニティの長期的な目標です。これにより、共感するチャットボット、有害なオンライン行動を検出するモデル、カスタマーサポートとのやり取りの改善など、さまざまなアプリケーションが可能になります。
過去10年間で、自然言語処理(NLP:Natural Language Processing)研究コミュニティは、言語ベースの感情分類のためにいくつかのデータセットを利用できるようにしました。それらの大部分は手動で作成され、対象となる領域(ニュースの見出し、映画の字幕、さらにはおとぎ話)をカバーしますが、データセットが比較的小さいか、または、1992年に提案された6つの基本的な感情(怒り(anger)、驚き(surprise)、嫌悪感(disgust)、喜び(joy)、恐怖(fear)、悲しみ(sadness))のみに焦点を当てています。これらの感情データセットは、感情分類の初期の調査を可能にしました。同時にまた、将来のより広い範囲への応用を潜在的に促進する可能性のある、より広範な感情のセットにわたる大規模なデータセットの必要性を強調しました。
論文「GoEmotions: A Dataset of Fine-Grained Emotions」では、GoEmotionsについて説明します。GoEmotionsは人気の高い英語の掲示板サイトであるRedditのフォーラム(subreddits)から抽出され、27の感情カテゴリでラベル付けされた58,000のコメントに人間が注釈を付けたデータセットです。
これまでで最大の完全に注釈が付けられた英語のきめ細かい感情データセットとして、心理学とデータの適用性の両方を念頭に置いてGoEmotions分類法を設計しました。
1つのポジティブな感情(喜び)のみを含む基本的な6つの感情とは対照的に、私たちの分類法には、12のポジティブ、11のネガティブ、4つのあいまいな感情、1つの中立(neutral)なカテゴリが含まれ、感情表現を微妙に区別する必要のある会話理解タスクに広く適しています。
GoEmotionsデータセットを、GoEmotionsを使用してニューラルモデルアーキテクチャ(TensorFlow Model Gardenで利用可能)をトレーニングし会話テキストに基づいて絵文字を提案するタスクに適用するプロセスを示す詳細なチュートリアルとともにリリースします。GoEmotionsモデルカードでは、GoEmotionsで構築されたモデルの追加の使用法、およびデータを使用する際の考慮事項と制限について説明しています。

このテキストは、興奮(excitement)、同意(approval)、感謝(gratitude)など、一度に複数の感情を表現しています。

このテキストは、ポジティブな感情とネガティブな感情の両方を伝える複雑な感情である安堵(relief)を表現しています。

このテキストは、頻繁に表現されるが、単純な感情モデルでは捉えられない複雑な感情である痛恨(remorse)を伝えます。
データセットの構築
私たちの目標は、会話データに焦点を当てた大規模なデータセットを構築することでした。会話データでは感情がコミュニケーションの重要な要素となります。
Redditプラットフォームは、ユーザー間の直接の会話を含む、公開されている大量のコンテンツを提供するため、感情分析のための貴重なリソースです。そのため、2005年(Redditの開始)から2019年1月までのRedditコメントを使用してGoEmotionsを構築しました。これは、削除されたコメントと英語以外のコメントを除いて、少なくとも10,000件のコメントを持つフォーラムから供給されました。
広く代表的な感情モデルの構築を可能にするために、データセットが一般的な、または感情固有の言語バイアスを強化しないようなデータ収集手段を用いました。Redditには若い男性ユーザーに傾倒する既知の人口統計学的偏りがあり、これは世界的に多様な人口を反映していないため、これは特に重要でした。
プラットフォームはまた、有毒で不快な言葉への偏りをもたらします。これらの懸念に対処するために、攻撃的/成人向けおよび俗語のコンテンツ、およびデータのフィルタリングとマスキングに使用したアイデンティティと事前定義された宗教用語を使用して、有害なコメントを特定しました。
さらに、冒とく的な表現を減らし、テキストの長さを制限し、表現された感情や感情のバランスをとるために、データをフィルタリングしました。人気のあるフォーラムでの過剰な表現を回避し、コメントがあまりアクティブでないフォーラムも反映するようにするために、フォーラムコミュニティ間でデータのバランスを取りました。
3つの目的を共同して最大化することを目的とした分類法を作成しました。
(1)Redditデータで表現された感情を最大限にカバー
(2)感情表現のタイプを最大限にカバー
(3)感情の総数とそれらの重複を制限
このような分類法により、データ駆動型のきめ細かい感情の理解が可能になると同時に、一部の感情の潜在的なデータの希薄性にも対処できます。
分類法の確立は、感情ラベルのカテゴリを定義および改良するための反復プロセスでした。データのラベル付けの段階で、合計56の感情カテゴリを検討しました。このサンプルから、評価者がほとんど選択しなかった感情、他の感情との類似性のためにに評価者間の一致度が低い感情、またはテキストから検出するのが困難な感情を特定して削除しました。
また、評価者によって頻繁に提案され、データによく表されている感情を追加しました。最後に、解釈可能性を最大化するために感情カテゴリ名を改良し、高いに評価者間の合意に至りました。94%のサンプルで、少なくとも2人の評価者が少なくとも1つの感情ラベルに同意しています。
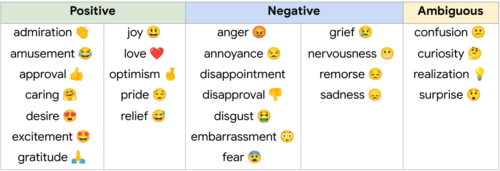
GoEmotionsの分類法。中立を含む28の感情カテゴリーを含みます。
データ分析と結果
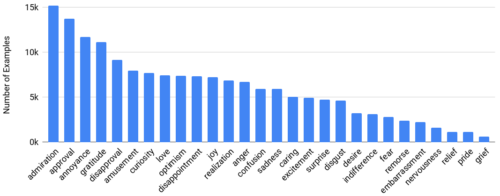
各感情はGoEmotionsデータセット内で一様に分布していません。
重要なのは、ポジティブな感情の頻度が高いことです。これにより、6つの基本的な感情を使った分類法よりも多様な感情の分類法を求める私達の意欲が増強されています。
3.GoEmotions:きめ細かい感情分類を行うためのデータセット(1/2)関連リンク
1)ai.googleblog.com
GoEmotions: A Dataset for Fine-Grained Emotion Classification
2)arxiv.org
GoEmotions: A Dataset of Fine-Grained Emotions
3)github.com
google-research/goemotions/
