
1.人々の表情は国や地域が変わっても場面によって共通なのか?(1/2)まとめ
・人間の表情は国や地域に関わらず場面によって普遍的かもしれない
・しかし過去に行われた研究は調査ベースで規模が小さく結果に一貫性がない
・DNNを活用して表情分析研究を大幅に規模拡大し大規模な世界的分析を実施
2.世界中の人々の表情の統一性を理解する試み
以下、ai.googleblog.comより「Understanding Contextual Facial Expressions Across the Globe」の意訳です。元記事の投稿は2021年5月24日、Alan CowenさんとGautam Prasadさんによる投稿です。
日本人だと花火は夏の終わり、郷愁や追想の対象であって、畏敬や畏怖の表情にはならないんじゃないのかなぁ、と思いながら選んだアイキャッチ画像のクレジットはPhoto by Spenser Sembrat on Unsplash
人間の表情は普遍的であると考えるのが妥当かもしれません。そのため、たとえば、ブラジル、インド、カナダのいずれの出身であっても、親しい友人を見たときの笑顔や花火を眺める際の畏敬(awe)の表情は基本的に同じように見えます。
しかし、それは本当に真実でしょうか?
これらの顔の表情と場面の関連性は本当に地理的に異なる地域間でも普遍的なのでしょうか?誰かがニヤリと笑う状況の間の類似点、または相違点は何を教えてくれるでしょうか?人々が異なる文化を越えてどのように繋がる事ができるかについて理解を深める事ができるでしょうか?
これらの質問に答え、文化や地理を超えて人々がどの程度つながっているかを明らかにしようとする科学者は、現地の言語、規範、価値観に大きく依存する可能性のある調査ベースの研究をよく使用します。ただし、そのような研究は規模拡大可能でははなく、多くの場合、サンプルサイズが小さく、結果に一貫性がありません。
調査ベースの研究とは対照的に、顔の動きのパターンを研究することは、表現行動のより直接的な理解を提供します。しかし、顔の表情が実際に日常生活でどのように使用されているかを分析するには、研究者は数百万時間の実世界の映像を調べる必要があり、手動で行うには時間がかかりすぎます。
更に、顔の表情とそれらが表示される場面は複雑であり、統計的に正しい結論を出すために大きなサンプルサイズが必要です。既存の研究は、与えられた場面における表情の普遍性の問題に対する多様な答えを生み出しましたが、研究対象の規模を適切に拡大するために機械学習(ML:Machine Learning)を適用すると答えが明瞭になる可能性があります。
Natureに掲載された論文「Sixteen facial expressions occur in similar contexts worldwide」ではカリフォルニア大学バークレー校と共同で行った研究を紹介し、ディープニューラルネットワーク(DNN:Deep Neural Networks)を活用して、責任ある思慮深い方法で表情分析研究を大幅に規模拡大し、日常生活で顔の表情が実際にどのように使用されるかについての最初の大規模な世界的分析を実施します。
144か国で公開されている600万本の動画のデータセットを使用して、人々が様々な表情を使用する状況を分析し、微妙な表情を含む顔の行動の豊かなニュアンスが世界中の同様の社会的状況で使用されていることを示します。
顔の表情を測定するディープニューラルネットワーク
顔の表情は静的ではありません。人の表情を一瞬一瞬調べてみると、最初は「怒り」に見えても、「畏怖」「驚き」「混乱」になってしまうかもしれません。
解釈は、その表現が現れるときの人の顔の動きの変遷に依存します。従って、顔の表情を理解するためのニューラルネットワークを構築する際の課題は、その時間的な変遷を考慮に入れて表情を解釈する必要があることです。このようなシステムのトレーニングには、完全に注釈が付けられた表現を備えた、大規模で多様な異文化間のビデオデータセットが必要です。
データセットを構築するために、熟練した評価者が、公開されているビデオから幅広いコレクションを手動で探し、事前に選択されたすべての表情カテゴリが含まれている可能性のあるビデオを特定しました。
ビデオが代表していると想定される地域と一致することを保証するために、ビデオ選択の際は、原産国表示が含まれるビデオが優先されました。
次に、ビデオ内の顔は、Google Cloud Face Detection APIと同様のディープ畳み込みニューラルネットワーク(CNN)を使用して検出されました。このネットワークは、従来のオプティカルフローに基づく方法を使用して、顔を追跡します。
次に、Googleクラウドソースと同様のインターフェースを使用して、注釈作業者は動画内の任意の時点にターゲットとなる表情が存在したらラベルを付けました。ターゲットとした顔の表情は28の異なるカテゴリにわたります。
目標は、平均的な人が表情をどのように認識するかをサンプリングすることであったため、注釈作業者は指導も訓練もされておらず、ターゲットとなる表情の例や定義も提供されていませんでした。
これらの注釈からトレーニングされたモデルが以下にバイアスされているかどうかを評価するための追加の実験について説明します。
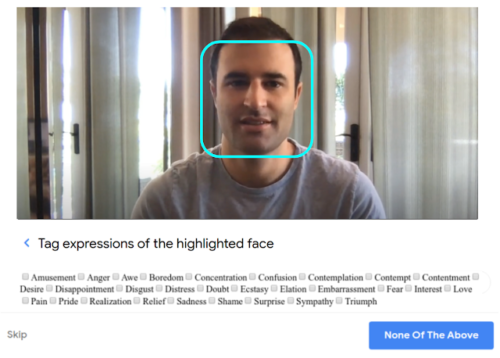
注釈作業者には、集中するために1つの顔が強調表示された動画が提示されました。彼らは動画内の被写体をずっと観察し、彼らが示した表情に注釈を付けました。(youtubeより収集した動画)
顔検出アルゴリズムは、ビデオ全体で各顔の位置と表示される順番を確立します。次に、事前にトレーニングされたインセプションネットワークを使用して、顔から顔の表情の最も顕著な側面を表す特徴を抽出しました。次に、これらの特徴はLTSMネットワークに供給されました。
LTSMは過去の顕著な情報を記憶する能力により、顔の表情が時間の経過とともにどのように進化するかをモデル化できるリカレントニューラルネットワークの一種です。
モデルがさまざまな人口統計グループにわたって一貫した予測を行っていることを確認するために、同様の表情ラベルを使用して構築された既存のデータセットでモデルの公平性を評価し、最高のパフォーマンスを示した16の表情のサブセットをターゲットにしました。
モデルのパフォーマンスは、評価データセットで表されるすべての人口統計グループで一貫しており、注釈付きの顔の表情にトレーニングされたモデルに測定可能なバイアスがかかっていないことを裏付ける証拠を提供します。クラウドにアップロードした画像で、1,500枚の画像にわたる16個の顔の表情のモデルの注釈を調べることができます。
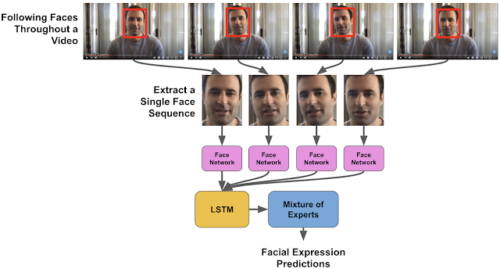
CNNを使用して各フレームで顔から特徴を抽出し、LSTMネットワークに入力として与えて時間の経過に伴う表現の変化をモデル化することにより、各ビデオで選択した顔をモデル化しました。(youtubeより収集した動画)
3.人々の表情は国や地域が変わっても場面によって共通なのか?(1/2)関連リンク
1)ai.googleblog.com
Understanding Contextual Facial Expressions Across the Globe
2)www.nature.com
Sixteen facial expressions occur in similar contexts worldwide

