
1.機械学習のトレーニングに失敗したしくじり事例まとめ
・データの収集とデータの品質向上は本質的に矛盾するので別作業として考える
・指標がないと感覚だけで是非を判断しなければならない状況に陥り難度が上がる
・自由に色々な事を試すためには経済的基盤をもっと盤石にする必要がある
2.データの収集と品質のトレードオフ
OpenAIのJukeBoxを使ってスタジオジブリっぽい音楽を作ってみようという試みをかなり試行錯誤してみたけれども最終的に行き詰まって失敗事例として断念したというお話です。
アイキャッチ画像のクレジットはPhoto by Jonas Denil on Unsplash
GoogleやOpenAIなどの成功事例ばかりを読んでいるとあたかも簡単な事のようにも見えてきてしまうけれども、実際には成功事例よりもっと多くの失敗事例があったはずで、それらは語られることもなく歴史の闇に埋もれていくのだろうけれども、参考事例として自分の失敗をまとめておこうと思ったのでまとめておきます。
しかし、失敗事例があまり世に出てこない理由は自分で書いてみてわかったけれども、格好悪いと言うこともあるが 「失敗ではなく、まだ成功してないだけだ」と言い張りたくなる自分がおり、整理すればするほど、「こんなやり方もあるのではないだろうか?」などなどアイディアが出てきて収拾がつかなくなってくるので、以下あまりまとまりきれていない文章ですが、ご参考までに。
データの収集とデータの品質向上は本質的に矛盾
たくさんのデータを集めるためには必然的に多少品質が悪いデータや本来の収集対象枠からやや外れたデータも対象にせざるを得なくなってくる。
ジブリの例で言えば、当初はジブリのサウンドトラックからスタートしたとしてもそれだけでは到底足りないので、ジブリ楽曲のアレンジ、同じ作曲家の作った他の映画音楽、ジブリと系統が似ている他のアニメ映画作品、なども対象にせざるを得なくなっていく。
元のOpenAIのJukeBoxは120万曲を学習用データとして使用したとの事だが、上記のようにデータ収集範囲をかなり広げても1万曲にも到底届かない。
どの程度のデータ量が必要なのかは明示されている文章を見付けられていないのだが、github上には7000曲程度でいい感じに動かせていると書いている人がいた。「いい感じ」がどの程度のものなのかわからないけれども、7000曲もおそらくは「ジャズ」や「クラシック」、もしくは「ピアノの演奏」のようなかなり大きなジャンル枠で収集しているのではないかと思う。相当データ収集範囲を広げないと7000曲も到底無理だと思う。
データが少なすぎると街頭の雑音のような音しか出力されないが、1000曲近い規模でデータを集めると曲っぽいものは作成できるようになってくるが、ジブリっぽいかというと微妙なレベルであり「曲にはなっているがジブリっぽいかはよくわからない」が正直な感想。
まぁ、ジブリ作品と一言でいっても作品によって雰囲気は違うのでジブリ風とは曖昧な表現ではあるけれども、画像合成などより音楽合成はスタイルが再現できているのかイマイチよくわからないし、そもそも「音楽におけるスタイルとは何ぞや?」と言う疑問もわいて出て来る。
画像のスタイル転送でも下記ムスカ大佐の例は微妙な感じがするけれども、音楽で同じようなレベル感で「ジブリ風の音楽」を作曲されてもイマイチ判別ができないだろうとは思う。

魔女の宅急便のウルスラの絵にゴッホの星月夜をスタイル転送(これはイケルだろうと思った)

千と千尋の神隠しの竜に葛飾北斎をスタイル転送(水がバックグラウンドで和な感じなので)

ムスカ大佐にムンクの叫びをスタイル転送(名前と色合いが似てるから。無理筋とは思った)
そうすると、特定の作品の楽曲、特定の楽器(ピアノ、オルゴール、歌声有、等)、特定の作風(~風アレンジ、オーケストラ、インストゥルメンタル)などに限定し、特徴をよりはっきりさせるためにデータを洗練させる方向性に進みたくなるが、カテゴリの分類を厳密にして対象外データを弾いていく事はデータ収集で頑張って集めたデータを捨てる行為なので、 この2つの作業を同時に進めていくと、どちらの作業が足りないのか、どっちをもっと頑張るべきなのかよくわからなくなってしまい、最終的に立ち往生してしまう。
一歩引いて考えてみれば当たり前の話なのだけれども、夢中でやっていると、本質的に矛盾した作業を同時に進めようとしている事に気付けない。
おそらく正解は、「別々の作業として進める」であり、成功したプロジェクトは品質が悪くとも巨大なデータで学習させたあとに、少量ではあっても精錬した厳選データを使って微調整させているケースが多いので、この二段階アプローチが現時点で判明している最適解なのだろうとは思う。
本件であれば、自己収集データでゼロから学習させる事は断念し、120万曲データで学習済のOpenAIのモデルに対して、例えばもののけ姫なり風の谷のナウシカなりの楽曲を厳選したデータで微調整させればもう少しいい感じになるのかもしれないとは思ってはいるが、
・120万曲データの半分は英語の楽曲なので、日本語の歌詞に転移はおそらくできない可能性が高い
・そもそも厳選した楽曲データであってもラベル付与や歌詞データ整備はかなり手間がかかる
・学習済みモデルを微調整するには15G以上のメモリを備えたGPUが必要なので私のRTX3060では動かせず300円/hのお金がかかる
・すでに20万円近い金額とかなりの時間をかけているが、できるかできないかわからない作業にこれ以上つっこむべきなのか?
などなどの迷うポイントが大量に湧き出てきてこちらも結局、立ち往生してしまった。突破力が足りない。
指標は大事
作成した楽曲の品質は、グラフだけみても改良の度合いがホントにわからないので、聞いてみるしかないけれども前述の通り聞いても品質がよくわからない場合が多く、画像はモード崩壊的なものが起こるとすぐわかるけれども、音楽はおそらく無音部分が多くなるが、そういう曲なのかもしれないと思うと、最後まで聞くしかないので、余計に時間がかかる事なども本件を難しくしている原因の1つ。
Google AIなどでも新しいベンチマークや指標、データセットの発表がよくあるけれども、指標がないと人間の感覚だけで是非を判断しなければならない状況に陥り、それは結構厳しい事なんだなと改めて実感。
なにか新しい分野の研究を始める際は、「指標(ものさし)はどんなものがあるのか?」を調べる事が大事と言う点は失敗から学んだ事の一つ。
音楽センスがある人ならば、以下のどのタイミングが最もジブリっぽい楽曲になっており学習をストップさせるべきであるのか簡単にわかるのだろうか?
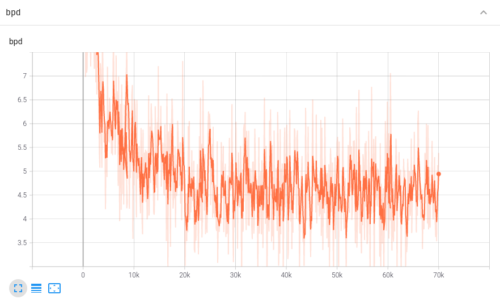
(1)30k時点
(2)40k時点
(3)50k時点
(4)60k時点
お金と時間は大事
クラウドはほんとに便利だが、やっぱり何度も学習をし直すなどのトライアンドエラーをやると10万20万円は簡単に飛んでいく。
学習 or 勉強 or 研究 or 実験のためという大義名分があるのと、あともう少し続けたらいい感じの結果が出るかもしれない、という淡い期待があるためズルズル続けてしまうが、通常、10万円越えの買い物をする際はもっと熟考するので撤退ラインはあらかじめ決めておくべきなのであろうとは思う。
しかしながら、機械学習の研究に関する逸話でも「今回もダメだったかと思ったが、学習を止めるのを忘れていて数週間放置していたら収束していた!」と言う事例は読んだ事があるので、撤退ラインを金額で決めておくのは望ましくないのかもしれない。しかしそれでも、一時間300円を動かしっぱなしで数週間放置は300円 x 24時間 = 7200円、7200円 x 7日 = 50,400円、50,400円 x 2週間 = 100,800円。動かしっぱなしでは来月の請求書がお幾ら万円になるのかわからず、心がドキドキと休まらないので現状は無理である。
もちろん、結果的に電子ゴミしか生み出せずに浪費してしまったとしても心が痛まないくらいお金が豊富にあれば話は別だが、そのようなお金は残念ながら現在は保有していない。なので、自由に色々な事を試すためには経済的基盤をもっと盤石にする必要があるな、とは本当に実感する。
ちょっと前にキュリー夫人の話を読んだのだけれども研究資金を稼ぐためにアルバイトなどをしていたとのお話で、今で言えば本業に加えてクラウド代金を稼ぐためにUber Eatsを頑張って、その資金で研究やってノーベル賞取りましたみたいな事をやったのかと思うと、普通の人であれば働くだけで疲れ切って疲弊してしまって研究などには気力が続かないと思うので、偉人は本当に偉人なんだなぁ、と思う。
もちろん、お金だけあってもダメで、人生において時間は限られており時間は大事。当たり前だが、お金も時間も大事。しかしながら、順番的にまずはお金を稼ぐ方向にもう少し重点を入れねば色々と試す事もできないな、と思う。

