
1.Project Guideline:視力の弱い人が一人で走れるようにする(2/2)まとめ
・既存のデータセットは自動運転車用でランニング用途の学習に使う事が難しかった
・自動運転車用データ、合成データ、本当のランニングデータの3段階で転移学習させた
・最終的なモデルはTensorflowLiteおよびMLKitでPixel上で直接動かすと非常に高速だった
2.Project Guidelineのトレーニング手法
以下、ai.googleblog.comより「Project Guideline: Enabling Those with Low Vision to Run Independently」の意訳です。元記事の投稿は2021年5月18日、Xuan Yangさんによる投稿です。
データ不足に陥った場合は中途半端にデータを集めるより、品質が悪くても巨大なデータセットで訓練してから小数でも品質が高いデータセットに転移させるアプローチがやっぱり王道なんですかね。
アイキャッチ画像のクレジットはPhoto by cameron-venti on Unsplash
データの収集
モデルをトレーニングするには、さまざまな道路条件を再現する大規模なトレーニング画像セットが必要でした。当然のことながら、公開されているデータセットは、カメラを屋根に取り付けた自動車が車用の線境界線に従って走行する自動運転車のトレーニング用途を想定しており、ランナーのガイドを行う用途は想定されていませんでした。
これらのデータセットを使ってトレーニングしたモデルでは、用途のギャップが大きいため、満足のいく結果が得られないことがわかりました。ガイドラインモデルでは、高速道路や混雑した街路に存在する障害物を見つけることではなく、歩行者用案内線に沿って走る人の腰に装着したカメラで収集したデータが必要でした。

自動運転データセットとランナー用データセット間の大きなギャップ。
左側はBerkeley DeepDriveデータセットの画像で、右側がランナー用データセットの画像です。
既存のオープンソースデータセットが今回の目的には役立たないことが判明したため、以下で構成される独自のトレーニングデータセットを作成しました。
手作業で収集されたデータ
チームメンバーは、明るい色のダクトテープを使用して舗装された経路に一時的にガイドラインを配置し、1日のさまざまな時間帯、さまざまな気象条件でライン上およびラインの周りを走って走行データを記録しました。
合成データ
COVID-19の行動制限により、データ収集の取り組みは複雑に厳しく制限されていました。 これにより、環境、天気、照明、影、視線を遮る物体を変化させて、何万もの画像を合成するカスタムレンダリングパイプラインを構築することになりました。
モデルが実際のテストで特定の条件に苦しんでいる時は、状況に対処するために特定の合成データセットを生成することができました。例えば、モデルは元々、落ち葉が山のように落ちている状況でガイドラインをセグメント化するのに苦労していました。 追加の合成トレーニングデータを使用して、後続のモデルリリースでそれを修正することができました。
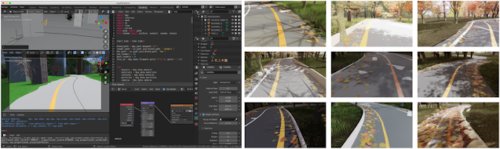
レンダリングパイプラインは、幅広い環境に対応するための合成画像を生成します。
また、小規模な退行確認データセット(regression dataset)を作成しました。
これは、最もありがちなシナリオにおけるデータと、樹木や人間の影、落ち葉、視線を遮る道路標示、ガイドラインに反射する太陽光、急な曲がり角、急な斜面など、最も困難なシナリオを組み合わせたもので構成されています。
この退行確認データセットを使って新しいモデルを以前のモデルと比較し、新しいモデルの精度の全体的な性能改善によって、特に重要または困難なシナリオで新しいモデルが精度の低下を引き起こしている事を見逃していないかを確認します。
トレーニング手順
3段階のトレーニング手順を設計し、転移学習を使用して、限られたトレーニングデータセットの問題を克服しました。このデータセットは大きくともランニング用データとしては品質が低いCityscapeで事前にトレーニングされたモデルから始めて、合成画像を使用してモデルをトレーニングしました。 最後に、収集した限られたランニング用データを使用してモデルを微調整しました。
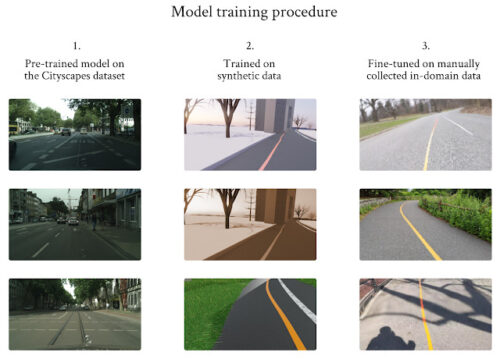
限られたデータの問題を克服するための3段階のトレーニング手順。
左の列の画像はCityscapesの厚意により提供されています。
開発の初期段階で、セグメンテーションモデルのパフォーマンスが画像フレームの上部で低下していることが明らかになりました。
ガイドラインがフレームの上部に存在し、カメラの視点からより離れると、線自体が消え始めます。これにより、フレームの上部で予測されたマスクの精度が低下します。この問題に対処するために、すべてのフレームの上位k画素行に基づいた損失値を計算しました。この値を使用して、モデルが苦労した消失ガイドラインを含むフレームを選択し、それらのフレームでモデルを繰り返しトレーニングしました。このプロセスは、消える線の問題に対処するだけでなく、ぼやけたフレーム、曲線、視線を妨げる物体による線の消失など、私たちが遭遇した他の問題を解決するのにも非常に役立つことがわかりました。
システムパフォーマンス
TensorflowLiteおよびMLKitとともに、Pixelデバイスで非常に高速に直接実行可能で、Pixel 4XLで29+FPS、Pixel5で20+FPSを達成します。
セグメンテーションモデルを完全にDigital Signal Processor上で動かすと、Pixel 4 XLでは6ミリ秒、Pixel5では12ミリ秒で高精度で実行できました。エンドツーエンドシステムは、評価データセットで99.5%のフレーム成功率、93%のmIoUを達成し、回帰テストに合格しています。
これらのモデルパフォーマンス基準は非常に重要であり、システムがユーザーにリアルタイムのフィードバックを提供できるようにします。
次にやる事は何ですか?
私達はまだ調査を始めたばかりですが、私達の進歩と今後の展望に興奮しています。私達は、視覚障害者や弱視者のコミュニティにサービスを提供する追加の主要な非営利団体と協力して、公園、学校、公共の場所により多くのガイドラインを導入し始めています。より多くの線を描き、ユーザーから直接フィードバックを受け取り、さまざまな条件下でより多くのデータを収集することで、セグメンテーションモデルをさらに一般化し、既存の特徴セットを改善したいと考えています。
同時に、システム全体の堅牢性と信頼性を向上させる新しい研究と技術、および新しい機能を調査しています。
プロジェクトとその経緯について詳しくは、blog.googleで紹介されたThomas Panekのストーリー「How Project Guideline gave me the freedom to run solo」をご覧ください。より多くのGuidelinesを世界中に設置するのを手伝いたい場合は、goo.gle/ProjectGuidelineにアクセスしてください。
謝辞
Project Guidelineは、Google Research、Google Creative Lab、およびアクセシビリティチーム間のコラボレーションです。
特にチームメンバーに感謝します:Mikhail Sirotenko, Sagar Waghmare, Lucian Lonita, Tomer Meron, Hartwig Adam, Ryan Burke, Dror Ayalon, Amit Pitaru, Matt Hall, John Watkinson, Phil Bayer, John Mernacaj, Cliff Lungaretti, Dorian Douglass, Kyndra LoCoco。また、Fangting Xia、Jack Sim、その他のモバイルビジョンチームの同僚や友人、Guiding Eyes for theBlindにも感謝します。
3.Project Guideline:視力の弱い人が一人で走れるようにする(2/2)関連リンク
1)ai.googleblog.com
Project Guideline: Enabling Those with Low Vision to Run Independently
2)docs.google.com
Project Guideline inquiry form
3)blog.google
How Project Guideline gave me the freedom to run solo


セグメンテーションモデルの精度と堅牢性は、困難なケースでもVersionUpで継続的に向上しました。