
1.文字情報と画像情報を同じ概念として認識できる人工知能の出現(1/2)まとめ
・特定の女優さんの画像や名前に反応するニューロンが人間の脳内で見つかった事がある
・ネットワークで機能するので特定のニューロンが反応するのはおかしいと反論があった
・今回、特定の刺激に対して反応するニューロンがニューラルネットワーク内で見つかった
2.マルチモーダルニューロンとは?
以下、openai.comより「Multimodal Neurons in Artificial Neural Networks」の意訳です。元記事の投稿は2021年3月4日、Gabriel Gohさん、Chelsea Vossさん、Daniela Amodeiさん、Shan Carterさん、Michael Petrovさん、Justin Jay Wangさん、Nick Cammarataさん、Chris Olahさんによる投稿です。
CLIPが内部的に何を学んでいるかを調べたお話なのですが、世間一般的には後半に出て来る誤認識事例だけが注目され「リンゴの写真に『iPod』と書いた紙を貼るとリンゴを『iPod』と誤認識するらしいよ。人工知能もまだまだだなぁ~」と言うネガティブな感じの受け取り方にもなっていました。
しかし、第一段階が猫画像などの画像の認識、第二段階が文脈の認識としたら、これは第三段階でもうすぐ人間が前処理をしなくても紙の本から直接学習可能な人工知能が出現するんだろうなと予感します。
アイキャッチ画像のクレジットはPhoto by Steven Libralon on Unsplash
どのような形式で表現されていても同じ概念として反応するニューロンをCLIPで発見しました。文字、シンボル、または概念的に提示されているかどうかに関わらず同じ概念として捉える事が出来ています。
これは、概念を視覚的特徴表現として分類する際のCLIPの驚くべき正確さを説明している可能性があります。また、CLIPや同様のモデルが学習する関連性とバイアスを理解するための重要なステップでもあります。
15年前、Quiroga et alは、人間の脳がマルチモーダルニューロンを持っていることを発見しました。これらのニューロンは、特定の視覚的特徴ではなく、高レベルで抽象的な概念が共通している事に応答します。これらの中で最も有名なのは、Scientific AmericanとThe New York Timesの両方で取り上げられたニューロンである「Halle Berryニューロン」です。このニューロンはHalle Berryの写真、スケッチ、およびテキスト「Halle Berry」に反応します。他の人の名前が書かれたテキストには反応しません。
2か月前、OpenAIはCLIPを発表しました。これは、ResNet-50のパフォーマンスに匹敵するが、最も困難なデータセットのいくつかで既存の視覚システムよりも優れた性能を発揮できる汎用の視覚システムです。
困難なデータセット、例えばObjectNet、ImageNet Rendition、ImageNet Sketchではそれぞれ、単純な歪みや照明やポーズの変化だけでなく、モデルの堅牢性、完全な抽象化や再構築(スケッチ、漫画、さらにはオブジェクトの彫像など)をテストしました。
本日、CLIPにマルチモーダルニューロンが存在するという発見を発表します。例えば「スパイダーマン(Spider-Man)」ニューロンです。(「Halle Berry」ニューロンに非常によく似ています)これは、蜘蛛の画像、「spider」と書かれたテキストを画像化したもの、そして漫画のキャラクター「スパイダーマン」の衣装またはイラストに反応します。
CLIPでのマルチモーダルニューロンの発見は、合成ビジョンシステムと自然ビジョンシステムの両方に共通するメカニズムである抽象化(abstraction)についての手がかりを与えてくれます。CLIPの最上位レイヤーは、画像を「アイデアを緩やかに意味的にまとめた集合(loose semantic collection of ideas)」として編成し、モデルの多様性と特徴表現のコンパクトさの両方を簡単に説明していることを発見しました。
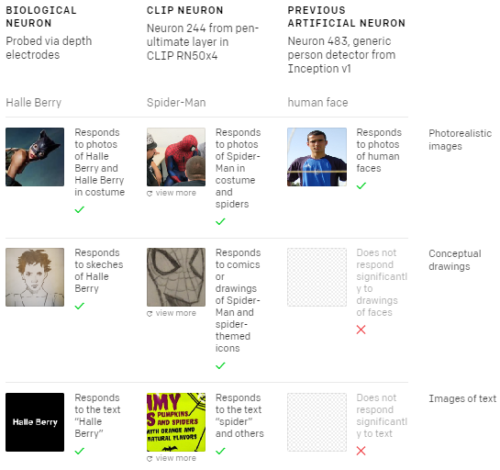
有名なハルベリーニューロンなどの生物学的ニューロンは、特定の概念の「視覚的に同質な集団」ではなく、「意味的に同質な集団」に対して発火します。CLIPの最上位層では、同様の意味的不変性が見られます。画像はQuirogaet al実験で使われた画像の高解像度版です。
解釈可能性ツールを使用して、CLIPの重みの中に存在する豊富な視覚的概念に前例のない外観を与えました。CLIP内で、地理的領域、顔の表情、宗教的な図像、有名人など、人間の視覚用語集の大部分にまたがる高レベルの概念を発見しました。各ニューロンが下流に影響を与えるものを調べることにより、CLIPがその分類をどのように実行するかを垣間見ることができます。
CLIPのマルチモーダルニューロン
私たちの論文は、畳み込みネットワークの解釈に関する10年近くの研究に基づいており、これらの古典的な手法の多くがCLIPに直接適用できるという観察から始まります。 モデルのアクティブ化を理解するために、2つのツールを使用します。
・特徴表現の視覚化(feature visualization)
入力に対して勾配ベースの最適化を行うことでニューロンの発火を最大化する特徴表現を視覚化する
・データセットの事例(dataset examples)
データセットからニューロンを最大に活性化させる画像の分布を調べる
これらの簡単な手法を使用して、CLIP RN50x4(EfficientNetスケーリングルールを使用して4倍にスケールアップされたResNet-50)のニューロンの大部分が容易に解釈できることがわかりました。
実際、これらのニューロンは、「多面的なニューロン」の極端な例であるように見えます。これは、より高いレベルの抽象化が行われた際に、複数の異なるケースに応答するニューロンです。
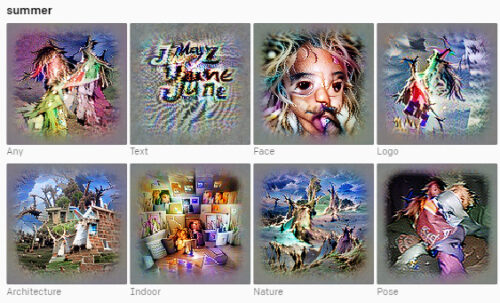
夏のイメージ
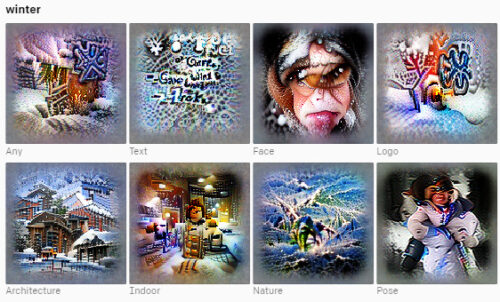
冬のイメージ
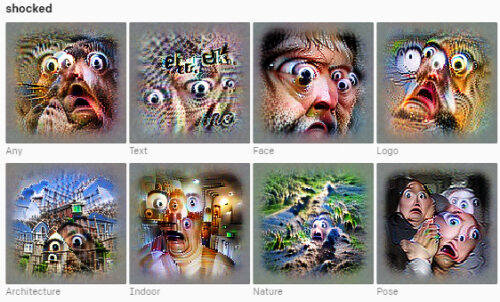
驚きのイメージ
19世紀半ばのイメージ

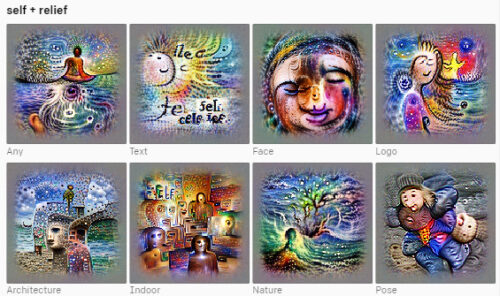
自己救済のイメージ
クリスマスのイメージ

ローマの芸術のイメージ

子どものラクガキイメージ

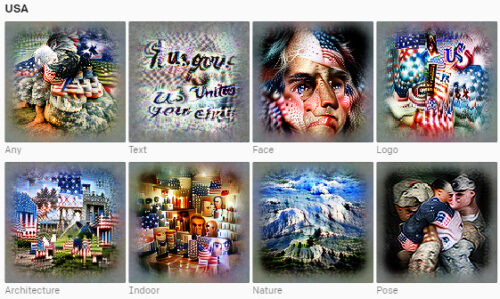
アメリカのイメージ
インドのイメージ

ハートのイメージ

西アフリカのイメージ

4つのCLIPモデルの最終層から選択されたニューロン
各ニューロンは、人間が選択した概念ラベルを使用した特徴の視覚化によって表され、各ニューロンの感覚をすばやく感じ取るのに役立ちます。ラベルは、特徴の視覚化に加えて、ニューロンを活性化する何百もの刺激を調べた後に選択されました。地域、感情、その他の概念のステレオタイプの描写に対するモデルの傾向を示すために、ここにいくつかの例を含めることにしました。
また、ニューロンの解像度のレベルに不一致が見られます。米国やインドなどの特定の国は明確に定義されたニューロンに関連付けられていましたが、ニューロンが地域全体で発火する傾向があるアフリカの国では同じではありませんでした。これらのバイアスのいくつかとその影響については、後のセクションで説明します。
確かに、これらのカテゴリーの多くが頭蓋内深部に電極を備えたてんかん患者で記録された内側側頭葉のHalle Berryニューロンのように見える事に驚きました。これらには、感情、動物、有名人に反応するニューロンが含まれます。
しかし、CLIPを調査したところ、数を数えているように見えるニューロン、アートスタイルに応答するニューロン(画像にデジタル効果を加えて改ざんしたものであっても)など、さらに多くの奇妙で素晴らしい抽象化が明らかになりました。
3.文字情報と画像情報を同じ概念として認識できる人工知能の出現(1/2)関連リンク
1)openai.com
Multimodal Neurons in Artificial Neural Networks
2)distill.pub
Multimodal Neurons in Artificial Neural Networks
3)microscope.openai.com
OpenAI Microscope
4)github.com
openai / CLIP-featurevis


訳注:Halle Berryはアメリカの女優さんで主演作には「キャットウーマン」などがあります。
ハルベリーニューロンは2005年の実験で、てんかん手術の評価を受けている人々の脳に電極を埋め込み、お気に入りの人々や場所の画像を見せたところ、ある男性の特定のニューロンがHalle Berryさんの画像や「Halle Berry」と書かれた文字を見せられるたびに発火する事が確認されたと言うお話です。
興味深い事は、「Halle Berryニューロン仮説」に対する主な反論は、(脳科学における)ニューラルネットワーク派からであったそうで、皆さんご存知の通り、ニューロン(神経細胞)は幾層にもわたる複雑に絡み合ったネットワーク全体として機能するのだから、1つのニューロンが1つの概念専用であるなんて事はおかしい、と言う反論であったそうです。
で、この度、(コンピューターサイエンスにおける)最先端の人工ニューラルネットワークから「Halle Berryニューロンっぽいのが見つかった」と言う事であり、脳を真似た仕組みが脳の謎に迫ってきている感があり、とっても面白い、ワクワクしますね。