
1.深層強化学習の力でロボットが俊敏で知的な移動を実現(3/3)まとめ
・階層強化学習では高レベルポリシーと低レベルポリシーは同時にトレーニングされる
・トレーニング目的はロボットの軌道から得られる総報酬を最大化する事
・学習完了後は高レベルポリシーを再学習させて微調整すれば他の経路にも対応可能
2.階層強化学習の性能
以下、ai.googleblog.comより「Agile and Intelligent Locomotion via Deep Reinforcement Learning」の意訳です。元記事の投稿は2020年5月6日、Yuxiang YangさんとDeepali Jainさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Sherry Chen on Unsplash
高レベルポリシーと低レベルポリシーは別々のタイムスケールで動作するため、ポリシー構造全体をエンドツーエンドで別々に扱う事はできません。そのため、PPO(Proximal Policy Optimization Algorithms)やSAC(Soft Actor-Critic)などの標準的な勾配ベースのRLアルゴリズムは使用できません。
代わりに、強化学習タスクで優れたパフォーマンスを示した単純な進化的最適化手法である拡張ランダムサーチ(ARS:Augmented Random Search)を通じて階層型ポリシーをトレーニングします。
2つのポリシーレベルの重みは一緒にトレーニングされ、その目的はロボットの軌道から得られる総報酬を最大化することです。
同じ四足ロボットを使用して、指定された経路に従って歩行するタスクでフレームワークをテストします。タスクを完了するためには、ロボットはまっすぐ歩くことに加えて、様々な方向に方向転換する必要があります。
低レベルポリシーは経路上のロボットの現在位置を認識していないため、単独でタスク全体を完了するための十分な情報を持っていない事に注意してください。
しかしながら、高レベルポリシーと低レベルポリシー間の調整により、潜在的なコマンドスペースに操舵動作が自動的に出現し、ロボットが経路を効率的に辿る事ができます。シミュレーション環境でのトレーニングが成功した後、階層強化学習(HRL:Hierarchical Reinforcement Learning)ポリシーを実際のロボットに転送し、その方向結果の軌跡を記録することにより、ハードウェアでの結果を検証します。

カーブした経路上でのロボットの成功軌道
左:ロボットが通過した軌道。軌道上の点は位置を示しています。この点で高レベルのポリシーが低レベルのポリシーに新しい潜在的なコマンドを送信しました。
中央:シミュレーション環境で経路に沿って歩くロボット
右:現実世界の道を歩くロボット
学習した階層型ポリシーをさらに実証するために、さまざまな潜在コマンドの下で、学習した低レベルポリシーの動作を視覚化しました。下図に示すように、さまざまな潜在コマンドにより、ロボットはまっすぐ歩いたり、左または右に異なる速度で曲がる事ができます。
また、低レベルポリシーの一般化可能性を、類似した新しいタスクに転送することでテストしました。これにはさまざまな形状の経路をたどることが含まれます。低レベルのポリシーの重みを修正し、高レベルのポリシーのみをトレーニングすることにより、ロボットは様々な経路を正常に辿る事ができました。
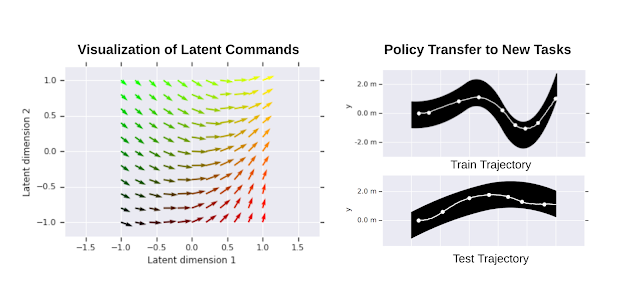
左:学習した潜在コマンドスペースの二次元視覚化。ベクトルの方向はロボットの移動方向に対応します。ベクトルの長さは、その距離に比例します。
右:低レベルポリシーの転送
右上:HRLポリシーは単一の経路でトレーニングされました。
右下:学習された低レベルポリシーは、他の経路で高レベルポリシーをトレーニングするときに再利用されました。
結論
強化学習は、コントローラーの設計プロセスを自動化することにより、ロボット工学に将来の可能性をもたらします。 モデルベースのRLを使用して、実際のロボットで直接、一般化可能な歩行動作の効率的な学習を可能にしました。 階層型RLを使用すると、ロボットはポリシーをさまざまなレベルで調整して、より複雑なタスクを達成することを学びました。 将来的には、ロボットが実世界で真に自律的に動作できるように、知覚をループに取り入れることを計画しています。
謝辞
Deepali JainとYuxiang Yangは両名とも、Ken CaluwaertsとAtil Iscenが指導するAI Residencyプログラムの研修者です。また、研究のサポートについてはJie TanとVikas Sindhwaniに、ニューヨークAIレジデンシープログラムのマネージメントについてはNoah Broestlに感謝します。
3.深層強化学習の力でロボットが俊敏で知的な移動を実現(2/3)関連リンク
1)ai.googleblog.com
Agile and Intelligent Locomotion via Deep Reinforcement Learning
2)arxiv.org
Data Efficient Reinforcement Learning for Legged Robots
Hierarchical Reinforcement Learning for Quadruped Locomotion


コメント