
1.Deep Bootstrap Framework:データが無限に存在する世界ではディープラーニングはどうなるか?(2/2)まとめ
・優れたモデルとトレーニングとは、理想世界で迅速で現実世界では迅速すぎない事
・事前トレーニングの主な効果は理想世界の最適化速度を改善する事であった
・データ拡張の主な利点は現実世界の最適化時間を延長する事であった
2.Deep Bootstrap Frameworkの適用
以下、ai.googleblog.comより「A New Lens on Understanding Generalization in Deep Learning」の意訳です。元記事の投稿は2021年3月10日、Hanie SedghiさんとPreetum Nakkiranさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by jamie-fenn on Unsplash
これらの実験は、一般化に関する新しい視点を示唆しています。つまり、(無限データで)迅速に最適化し、(有限データで)適切に一般化するモデルです。例えば、ResNetモデルは、有限データではMLPモデルよりも一般化に優れていますが、これは、無限データでも最適化が高速であるためです。
最適化の挙動から一般化を理解する
重要な観察結果は、現実世界と理想世界のモデルは、現実世界のトレーニングが収束するまで(1%未満のトレーニングエラー)、全てのタイムステップでテストエラーが近似しているということです。従って、理想世界での対応動作を研究することにより、現実世界でのモデルを研究することができます。
これは、モデルの一般化が2つのフレームワークを使って最適化パフォーマンスの観点から理解できることを意味します。
(1)オンライン最適化(Online Optimization)
理想世界でテストエラーがどれだけ速く減少するか?
(2)オフライン最適化(Offline Optimization)
現実世界でトレインエラーがどれだけ早く収束するか?
従って、一般化を研究する際に、上記の2つの条件を同等に研究できます。
これらの用語は、最適化の問題のみを含むため、概念的に単純にすることができます。この観察に基づくと、優れたモデルとトレーニング手順は、
(1)理想世界では迅速に最適化され、
(2)現実世界では最適化が迅速すぎないものです。
ディープブートストラップフレームワークの適用
研究者は、Deep Bootstrapフレームワークを使用して、深層学習における設計や研究の選択をガイドできます。原則は次のとおりです。
現実世界の一般化に影響を与える変更(アーキテクチャ、学習率など)を行うときは常に、以下の影響を考慮する必要があります。
(1)テストエラーの理想世界における最適化(速いほど良い)
(2)トレインエラーの現実世界における最適化(遅いほど良い)
たとえば、事前トレーニングは、実務的には、小規模データしか利用できない際にモデルの一般化を支援するためによく使用されます。ただし、事前トレーニングが役立つ理由はよくわかっていません。
上記の条件(1)および(2)に対する事前トレーニングの効果を調べることにより、DeepBootstrapフレームワークを使用してこれを調べることができます。
事前トレーニングの主な効果は、「(1)理想世界の最適化」を改善することであることがわかりました。すなわち、 事前トレーニングは、ネットワークをオンライン最適化のための「高速学習者」に変えます。
従って、事前トレーニングされたモデルの改善された一般化は、理想世界の最適化推移で正確に補足できます。次の図は、CIFAR-10でトレーニングされたVision-Transformers(ViT)での事例を示しており、ゼロからのトレーニングとImageNetでの事前トレーニングを比較しています。
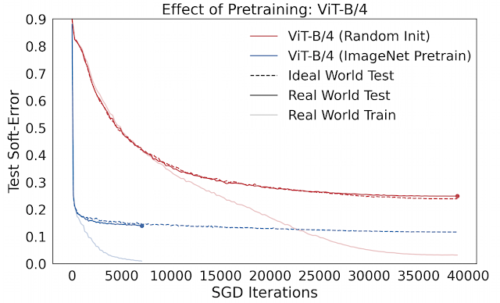
事前トレーニングの効果
事前トレーニングされたViTは、理想的な世界でより速く最適化されます。
このフレームワークを使用してデータ拡張(data-augmentation)を研究することもできます。理想世界でのデータ拡張は、同じサンプルを複数回拡張するのではなく、各新鮮なサンプルを1回拡張することに対応します。このフレームワークでは、優れたデータ拡張とは、
(1)理想世界の最適化に大きな害を及ぼさない
つまり、水増ししたサンプルが「分布外データ(out of distribution)」に見えない
または
(2)現実世界の最適化速度を抑制する
つまり、現実世界ではそのトレーニングセットに適合するのに時間がかかります
データ拡張の主な利点は、(2)を通じて、現実世界の最適化時間を延長することです。(1)に関しては、いくつかの積極的なデータ拡張(mixup/cutout)は実際には理想世界に害を及ぼす可能性がありますが、このマイナス効果は(2)によって小さくなります。
結論
ディープブートストラップフレームワークは、ディープラーニングの一般化と経験的現象に関する新しい視点を提供します。
将来、ディープラーニングの他の側面を理解するためにこのフレームワークが適用されるのを見るのを楽しみにしています。多くの理論的なアプローチとは対照的に、一般化が純粋に最適化の考慮事項によって特徴付けられることは特に興味深いことです。重要なのは、オンラインとオフラインの両方の最適化を検討することです。これらは個別には不十分ですが、それが一緒になると一般化を決定します。
ディープブートストラップフレームワークは、ディープラーニングが多くの設計選択に対してかなり堅牢である理由にも光を当てることができます。多くの種類のアーキテクチャ、損失関数、オプティマイザー、正規化、および活性化関数がうまく一般化できています。ディープブートストラップフレームワークは、統一の原則を示唆しています。つまり、オンライン最適化設定で適切に機能する選択は、オフライン設定でも一般化されるということです。
最後に、最新のニューラルネットワークは、パラメーターが多すぎる(例えば、小さなデータタスクでトレーニングされた大規模なネットワーク)か、パラメーターが不足している(例えば、OpenAIのGPT-3、GoogleのT5、またはFacebookのResNeXt WSL)可能性があります。ディープブートストラップフレームワークは、オンライン最適化がこれらのケースで成功するための重要な要素であることを意味します。
謝辞
共著者であるBehnam Neyshaburの論文への多大な貢献と、ブログへの貴重なフィードバックに感謝します。ブログと論文に有益なコメントを寄せてくれたBoaz Barak, Chenyang Yuan, 及び Chiyuan Zhangに感謝します。
3.Deep Bootstrap Framework:データが無限に存在する世界ではディープラーニングはどうなるか?(2/2)関連リンク
1)ai.googleblog.com
A New Lens on Understanding Generalization in Deep Learning
2)arxiv.org
The Deep Bootstrap Framework: Good Online Learners are Good Offline Generalizers
3)github.com
preetum / cifar5m

