
1.EpochとBatch SizeとIterationsとNumber of batchesの違いまとめ
・エポックとは全学習データの事。サイズが多くなるので分割して処理する事が多い
・エポックを分割したものをバッチと呼ぶ。バッチ内のデータ数をバッチサイズという
・1エポックの学習を完了するために必要な繰り返しの回数を反復(Iteration)と言う
2.エポックとバッチサイズとバッチ数とイテレーションの違い
以下、towardsdatascience.comより「Epoch vs Batch Size vs Iterations」の意訳です。元記事の投稿は2017年9月23日、SAGAR SHARMAさんによる投稿です。
時間がない人は「3.Webbigdataによる捕捉」だけ読んでください。
アイキャッチ画像はEpochで検索すると出てきたイタリアはトリノの彫刻でクレジットはPhoto by Alexander Schimmeck on Unsplash
はじめに
あなたも画面を見て頭をかいて不思議に思っていた時代があったに違いありません。
「何故、epoch(エポック)、Batch size(バッチサイズ)、Iteration(イテレーション、反復)、これら3つの数値を入力する必要があるのだろうか?これらの違いは何なのだろうか?」どれもよく似ているからです。
これらの用語の違いを知るためには、勾配降下法(Gradient Descent)などの機械学習用語のいくつかを知って、理解を深める必要があります。以下が勾配降下法の簡単な要約です。
勾配降下法(Gradient descent)
勾配降下法は、機械学習で使用される最適化アルゴリズムであり、目的は最良の結果(曲線の最小値)を見つける事です。
勾配とは、斜面の傾斜を意味します。降下とは、下降していく事を意味します。アルゴリズムは反復的です。つまり、最適な結果を得るには、結果を複数回取得する必要があります。勾配降下法の反復品質は、グラフがデータに適合するようにするために役立ちます。
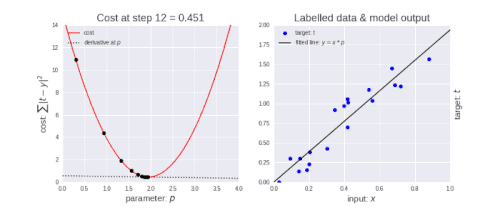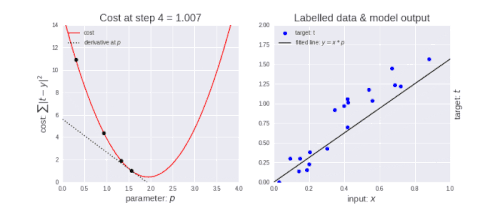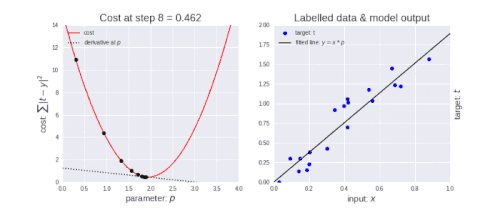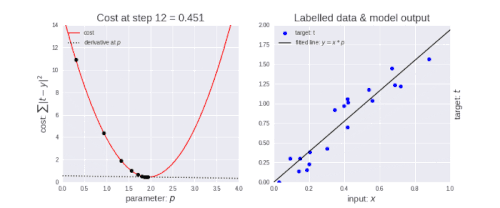
勾配降下法には、学習率と呼ばれるパラメーターがあります。 あなたが左上の図で見ることができるように最初はステップを大きくします。つまり、学習が進み、ポイントが下がるにつれて、ステップのサイズが短くなり、学習率が小さくなります。また、コスト関数が減少しているか、コストが減少しています。
損失関数(Loss Function)が減少している、または損失(Loss)が減少していると言う人を時々目にするかもしれません。コスト(Cost)も損失(Loss)も同じことを表現しています。(ところで、損失/コストが減少しているのは良いことです)
エポック、バッチサイズ、反復などの用語が必要なのは、データが大きすぎて(機械学習では頻繁に発生する事です)、全てのデータを一度にコンピューターが読み込む事ができない場合のみです。
従って、この問題を克服するには、データを小さなサイズに分割して1つずつコンピューターに渡し、すべてのステップの最後にニューラルネットワークの重みを更新して、与えられたデータに適合させる必要があります。
Epochs(エポック)
1エポックとは、データセット全体をニューラルネットワークに1回与えて処理を行う事です。
エポックが大きすぎて一度にコンピューターに与える事が出来ない場合、いくつかの小さなバッチに分割します。
なぜ複数エポックを使用するのでしょうか?
データセット全体をニューラルネットワークに渡すだけでは不十分です。完全なデータセットを同じニューラルネットワークに複数回渡す必要があります。ただし、限られたデータセットを使用している事と、学習とグラフを最適化するために、反復プロセスである最急降下法を使用している事が前提条件にある事に注意してください。反復プロセスであるために、1エポックで重みを更新するだけでは不十分です。
1エポックでは、下図の「適合不足(underfitting)」になります。
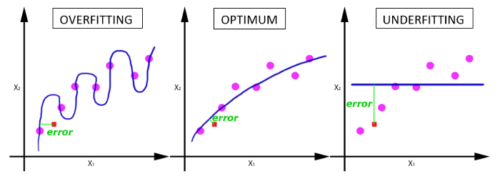
エポックの数が増えると、ニューラルネットワークで重みが変更される回数が増え、曲線は適合不足(underfitting)から最適化(optimal)を得て、過剰適合(overfitting)の曲線になります。
それでは、最適なエポック数を求めるにはどうすれば良いですか?
残念ながら、この質問に対する正しい答えはありません。答えはデータセットごとに異なるので、唯一言える事は、エポックの数はデータの多様性に関連していると言えます。
ほんの一例ですが、貴方のデータセット内には黒猫のみが存在するのでしょうか?それともはるかに多様な猫が含まれるデータセットでしょうか?
Batch size(バッチサイズ)
1つのバッチ内に存在するトレーニング事例(training samples)の総数
注:バッチサイズ(Batch size)とバッチ数(number of batches)は2つの異なるものです。
しかし、バッチとは何でしょうか?
先ほど言ったように、データセット全体を一度にニューラルネットに渡すことはできません。
従って、データセットを幾つかの「セット(sets)」または「パーツ(parts)に分割します。
この数の事を「バッチ数」と言います。
本記事は「はじめに」、「勾配降下法」、「エポック」、「バッチサイズ」、「反復」などの複数のセット/パーツ/バッチに分割して、読者が記事全体を読みやすく、理解しやすくしていますが、これと同じ事です。
Iterations(反復、イテレーション)
Iterations(反復)を理解するには、掛け算の九九を知っているか、電卓を持っている必要があります。
Iterations(反復)は、1つのエポックを完了するために必要なバッチの数です。
注:バッチ数(Number of batches)は、1つのエポックを処理するための反復回数と同じです。
トレーニング用のサンプルが2000個あるとします。
2000サンプルのデータセットを500サンプルずつバッチに分割すると、1つのエポックを完了するのに4回の反復が必要になります。
または、バッチサイズが500、反復を4回行う事で、1つの完全なエポックとなります。
あなたは完全に理解しました!
同様な投稿を見るには、Mediumで私をフォローしてださい。
Facebook、Twitter、LinkedIn、Google +で私に連絡してください
コメントや質問がある場合は、コメントに書き込んでください。
お役に立てればれしいです。 頑張って!
3.Webbigdataによる捕捉
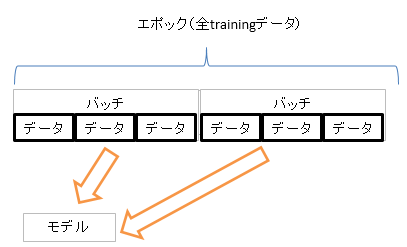
・上図では学習用(training)データは6つのデータから構成されており、1エポックは6データ
・バッチサイズ(Batch size)は各バッチは3つのデータから構成されているので3
・1エポックの学習を完了するために必要なバッチの数(Number of batche)は2なので反復(Iteration,イテレーション)は2
上の図では「データ」と表記してますが、1つ1つのデータは「サンプル」と表記される事も多いですね。なので、「1バッチは3サンプルから構成されているのでバッチサイズは3」なんて表現を見る事もあるかもしれません。
余談ですが、1エポック分の学習が終わると検証用データ(Validation data)を使って
・精度が向上したか?
・過剰適合(過学習)になってないか?
を検証し、更に学習を進めるかここでストップするかを決定します。何エポックでストップさせるか?は以下のようにグラフなどを見ながら決めます。
Epochの決め方
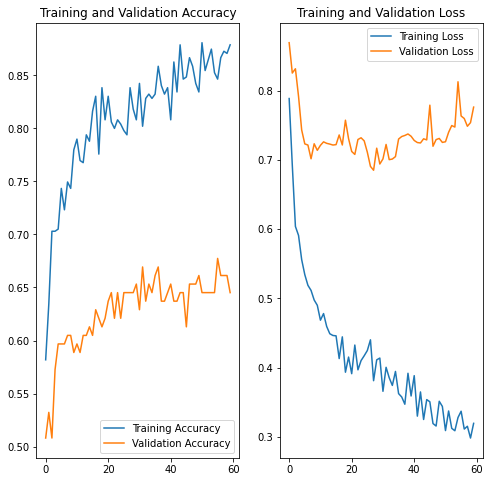
精度をY軸、epoch数をX軸で下図のようにグラフ化し、30epochくらいからTrainingデータは精度が上がっているけれどもValidationデータの方の精度が上がらなくなってきているので、この辺りからTrainingデータへの過剰適合が始まっているかなぁ、と当たりを付けます。このグラフはTensorflowやPytorchのようなFrameworkの方で色々と便利な仕組みが用意されているので自動でグラフ化できます。
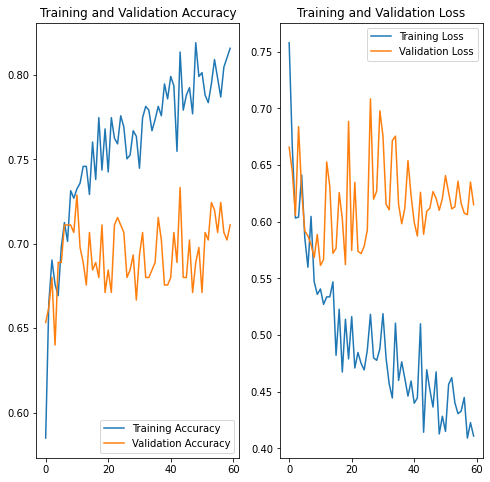
データ数を約二倍の増やしてそれ以外は同じ条件で学習させたのが下図。こうなると本当は10 epochくらいで止めておくべきでしょうか。しかし、実は増やす前も10 epoch近辺が妥当だったのかなぁ、などなどと悩みながら決めていく事になります。
お疲れ様でした!
色々と情報を詰め込み過ぎてるかもしれませんが、何となくは理解できましたでしょうか?
見慣れない似たような単語が複数出てきて少し混乱してしまったかもしれませんが、慣れの問題でもあるのでそんなに気にしなくても大丈夫です。
更に、このページは初心者向けに解説している用語解説をしているページと思ったかもしれませんが、実はけっこう深い話に繋がっている混乱しがちなポイントでもあるので本当にお疲れ様でした。お気をつけてお帰り下さい!
・・・・
まだ余裕があって最先端の世界をチラッと覗き見したい人は以下の記事なども読んでみると興味深いと感じるかもしれません。割とホントにわけがわからなくなってくる可能性もあるので学習熱心な方のみどうぞ。教科書に書かれているレベルの話が割と簡単にひっくり返ったり、矛盾した結果が発表されるのが今の人工知能の面白いところで且つ、着いていくのが大変な所でもあります。
Deep Bootstrap Framework:データが無限に存在する世界ではディープラーニングはどうなるか?(1/2)
Deep Bootstrap Framework:データが無限に存在する世界ではディープラーニングはどうなるか?(2/2)
何故、エポックをバッチに分割して処理するのか?の議論も実は深いです。以下の記事などが参考になるかもしれません。
ディープラーニングコースを受講した生徒からの興味深い質問(1/4)
単にメモリが足りなくなると言う実務的な意味での規模感を知りたい場合は以下の記事なども参考になるかもです。
4.EpochとBatch SizeとIterationsとNumber of batchesの違い関連リンク
1)towardsdatascience.com
Epoch vs Batch Size vs Iterations

